Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Comment le Googlebot crawle-t-il et indexe-t-il réellement votre site web ?
- □ Comment Google construit-il réellement son index et pourquoi ça change tout pour votre SEO ?
- □ Comment Google classe-t-il réellement les résultats pour une requête donnée ?
- □ Google personnalise-t-il vraiment tous les résultats selon l'utilisateur ?
- □ Les résultats organiques Google reposent-ils vraiment uniquement sur la pertinence du contenu ?
- □ Peut-on vraiment payer Google pour améliorer son positionnement organique ?
- □ Google distingue-t-il vraiment ses annonces des résultats organiques de manière efficace ?
- □ Les ressources officielles Google suffisent-elles vraiment à optimiser votre visibilité SEO ?
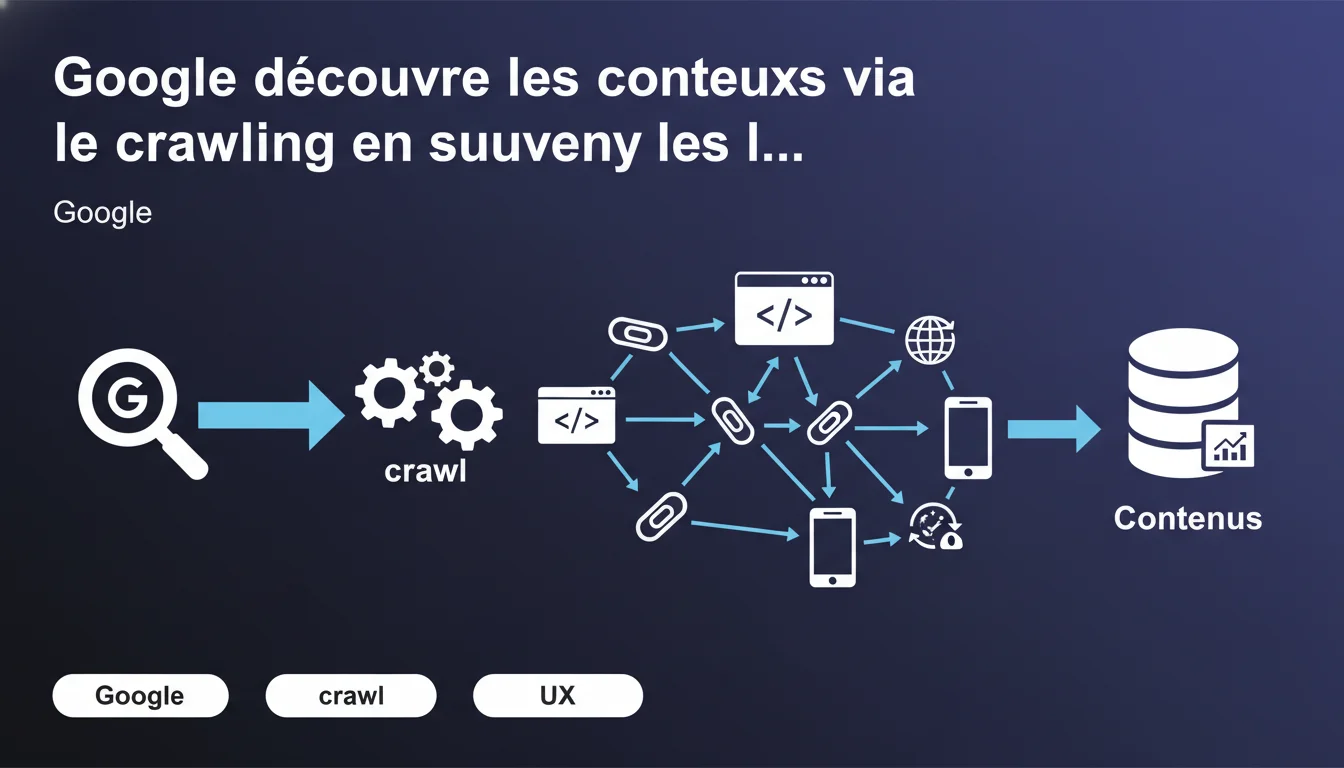
Google découvre de nouveaux contenus en suivant les liens de page en page — c'est le crawling. Sans liens pointant vers une page, elle reste invisible pour le moteur. Le maillage interne et les backlinks sont donc les deux piliers de la découvrabilité.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur le rôle central des liens dans la découverte ?
Le crawling est le processus par lequel Googlebot parcourt le web en suivant les hyperliens d'une page à l'autre. Chaque lien est une porte d'entrée potentielle vers un nouveau contenu. Sans lien, une page reste orpheline — techniquement accessible par URL directe, mais invisible pour le moteur.
Cette déclaration rappelle une vérité fondamentale : la structure de liens détermine la découvrabilité. Une page enfouie à 10 clics de la home, sans backlink externe, sera crawlée tard, voire jamais.
Qu'est-ce que cela implique concrètement pour l'indexation d'un site ?
Si Google ne trouve pas vos pages, il ne peut pas les indexer. Le maillage interne devient donc un levier stratégique pour prioriser le crawl des contenus importants. Une page accessible en 2 clics depuis la home sera découverte plus rapidement qu'une page enterrée dans une sous-catégorie obscure.
Les backlinks jouent un rôle similaire : ils signalent à Google qu'une page mérite d'être crawlée, surtout si le lien provient d'un site déjà dans l'index et régulièrement visité.
Google utilise-t-il d'autres méthodes pour découvrir des contenus ?
Oui, mais les liens restent le canal principal. Google peut aussi découvrir des pages via les sitemaps XML, les flux RSS, ou les soumissions manuelles via Search Console. Mais ces méthodes ne remplacent pas les liens — elles complètent.
Le sitemap aide surtout pour les pages récentes ou mal liées. Mais si une URL n'a aucun lien interne ou externe, même un sitemap ne garantit pas un crawl rapide.
- Les liens sont le principal vecteur de découverte — sans eux, une page reste invisible
- Le maillage interne structure la priorité de crawl et accélère l'indexation des pages stratégiques
- Les backlinks signalent la pertinence et déclenchent un crawl plus fréquent des pages liées
- Les sitemaps XML sont un complément, pas un substitut au maillage et aux backlinks
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. Les audits de crawl le confirment : les pages orphelines ou mal liées sont rarement indexées rapidement, voire pas du tout. Les logs serveur montrent que Googlebot suit méticuleusement les liens internes et externes pour découvrir de nouvelles URLs.
Cela dit, Google omet une nuance importante : tous les liens ne se valent pas. Un lien en footer partagé sur 10 000 pages aura moins d'impact qu'un lien éditorial contextuel depuis une page stratégique. [A vérifier] : Google ne précise jamais comment il pondère les liens dans son algorithme de crawl — on sait juste qu'il y a une différence.
Quelles erreurs fréquentes découlent d'une mauvaise compréhension de ce mécanisme ?
Beaucoup de sites comptent uniquement sur leur sitemap XML pour faire indexer de nouvelles pages. Résultat : délais importants, voire absence totale d'indexation. Le sitemap ne déclenche pas un crawl prioritaire — il informe simplement Google qu'une URL existe.
Autre erreur classique : créer des pages sans aucun lien interne en pensant qu'elles seront découvertes par magie. Ça ne fonctionne pas. Une page doit être liée, idéalement depuis plusieurs endroits stratégiques du site.
Dans quels cas cette règle ne s'applique-t-elle pas totalement ?
Pour les très gros sites — e-commerce avec des millions de produits, médias à forte volumétrie — le crawl budget devient un facteur limitant. Google ne crawle pas tout, même si tout est bien lié. Il faut alors prioriser le maillage des pages à forte valeur et bloquer le crawl des pages inutiles (filtres, paramètres, etc.).
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser la découverte de vos contenus ?
Structurez votre maillage interne de manière hiérarchique : les pages stratégiques (conversions, contenus piliers) doivent être accessibles en 2-3 clics maximum depuis la home. Utilisez des liens contextuels dans vos contenus éditoriaux pour renforcer la découvrabilité des pages importantes.
Auditez régulièrement vos pages orphelines — celles qui n'ont aucun lien interne. Corrigez en ajoutant des liens depuis des pages déjà bien crawlées. Priorisez les backlinks de qualité pour accélérer le crawl des nouvelles sections ou contenus stratégiques.
Quelles erreurs éviter absolument ?
Ne comptez pas uniquement sur votre sitemap XML. Il ne remplace pas les liens. Évitez aussi de créer des structures de navigation trop profondes — chaque clic supplémentaire retarde la découverte et dilue l'équité de lien.
Attention aux liens bloqués par robots.txt ou JavaScript mal géré : Googlebot ne peut pas suivre ce qu'il ne voit pas. Vérifiez que vos liens critiques sont en HTML standard et crawlables.
Comment vérifier que votre site est bien structuré pour le crawl ?
- Vérifiez dans Search Console que les pages stratégiques sont bien indexées rapidement après publication
- Analysez vos logs serveur pour identifier les pages jamais ou rarement crawlées
- Utilisez Screaming Frog pour détecter les pages orphelines et les corriger
- Auditez la profondeur de crawl : aucune page importante ne devrait être à plus de 3 clics de la home
- Surveillez les backlinks entrants via Ahrefs, Majestic ou Search Console — ils accélèrent le crawl
- Soumettez un sitemap XML propre et à jour, mais ne vous reposez pas uniquement dessus
❓ Questions frequentes
Google peut-il indexer une page sans lien pointant vers elle ?
Le sitemap XML suffit-il à faire indexer mes pages rapidement ?
Tous les liens internes ont-ils le même poids pour le crawl ?
Les backlinks accélèrent-ils vraiment la découverte de nouvelles pages ?
Comment identifier les pages orphelines sur mon site ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.