Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Comment Google découvre-t-il réellement vos pages via le crawling et les liens ?
- □ Comment le Googlebot crawle-t-il et indexe-t-il réellement votre site web ?
- □ Comment Google classe-t-il réellement les résultats pour une requête donnée ?
- □ Google personnalise-t-il vraiment tous les résultats selon l'utilisateur ?
- □ Les résultats organiques Google reposent-ils vraiment uniquement sur la pertinence du contenu ?
- □ Peut-on vraiment payer Google pour améliorer son positionnement organique ?
- □ Google distingue-t-il vraiment ses annonces des résultats organiques de manière efficace ?
- □ Les ressources officielles Google suffisent-elles vraiment à optimiser votre visibilité SEO ?
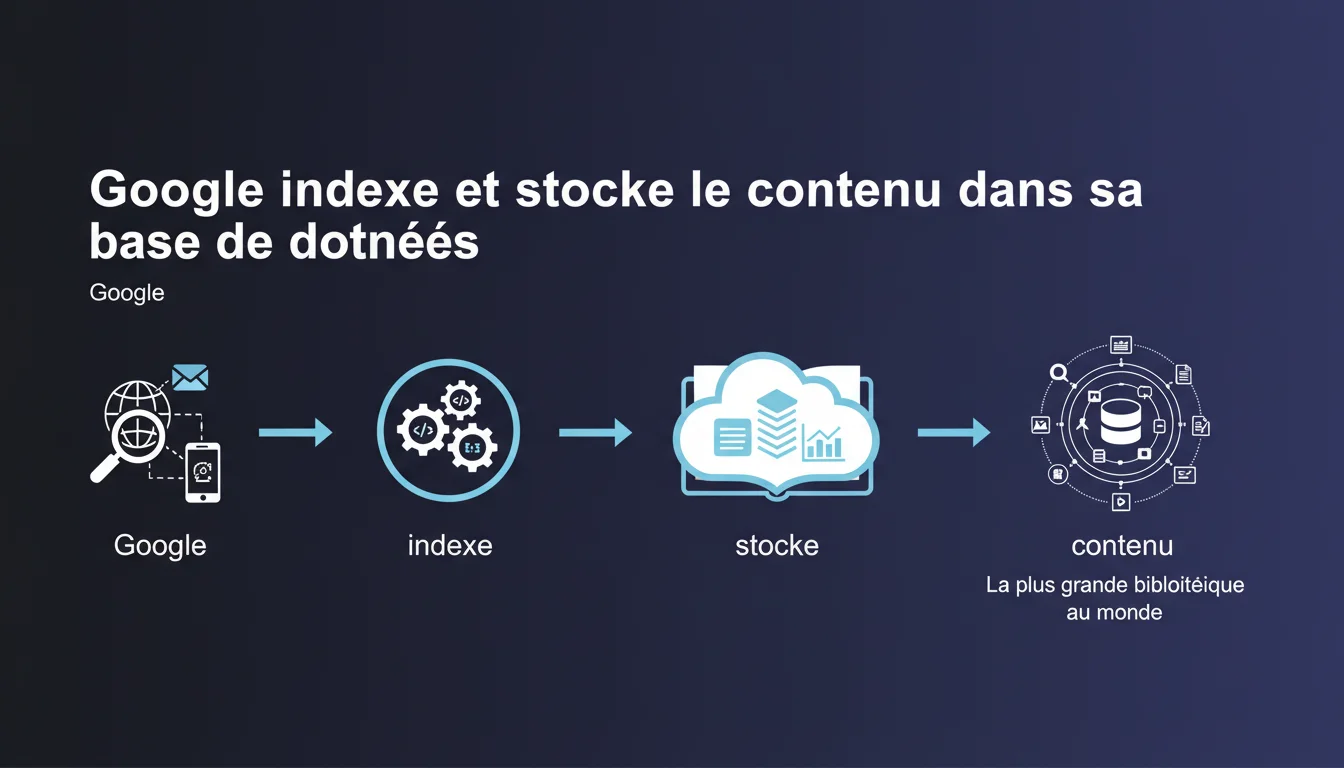
Google analyse le contenu de chaque page crawlée et stocke ces informations dans son index, présenté comme la plus grande bibliothèque au monde. Pour un SEO, comprendre cette mécanique d'indexation détermine directement la visibilité : ce qui n'est pas indexé n'existe tout simplement pas dans les résultats de recherche.
Ce qu'il faut comprendre
Qu'est-ce que l'index Google et pourquoi est-ce le nerf de la guerre SEO ?
L'index de Google, c'est la base de données colossale où sont stockées toutes les informations extraites des pages web crawlées. Quand un utilisateur lance une recherche, Google ne parcourt pas le web en temps réel — il interroge cet index.
Sans indexation, une page reste invisible, peu importe sa qualité ou son optimisation. C'est pourquoi comprendre les mécanismes d'indexation est fondamental : vous pouvez avoir le meilleur contenu du monde, s'il n'entre pas dans cette bibliothèque géante, il n'existe pas pour Google.
Que se passe-t-il concrètement lors de l'analyse d'une page ?
Google extrait et catalogue une multitude d'informations : le texte visible, les balises HTML (title, meta, headings), les images avec leurs attributs alt, les liens internes et externes, la structure du DOM.
Chaque élément est analysé, pondéré selon des critères de pertinence, puis stocké. Cette analyse ne se limite pas au contenu brut — Google cherche à comprendre le sens et le contexte, via des algorithmes de traitement du langage naturel comme BERT ou MUM.
Pourquoi Google insiste-t-il sur la notion de « plus grande bibliothèque au monde » ?
Cette formulation n'est pas anodine. Elle souligne l'ampleur phénoménale de l'infrastructure nécessaire pour stocker et indexer des milliards de pages. Mais elle rappelle aussi un principe clé : comme toute bibliothèque, l'index Google applique des règles de sélection.
Toutes les pages crawlées ne sont pas nécessairement indexées. Google peut décider de ne pas indexer du contenu jugé de faible qualité, dupliqué, ou techniquement inaccessible. L'indexation n'est jamais automatique ni garantie.
- L'indexation est la condition sine qua non de toute visibilité organique.
- Google extrait et stocke bien plus que du texte : structure, liens, métadonnées, contexte sémantique.
- Toutes les pages crawlées ne finissent pas dans l'index — des filtres de qualité s'appliquent.
- L'index est interrogé en temps réel lors des recherches, pas le web lui-même.
- Comprendre comment Google analyse votre contenu permet d'optimiser ce qui sera effectivement stocké et récupérable.
Avis d'un expert SEO
Cette déclaration est-elle complète ou cache-t-elle des zones d'ombre ?
Soyons honnêtes : la déclaration de Google reste en surface. Elle confirme un principe de base — analyse, stockage, index — mais ne détaille aucun critère de sélection. Quels seuils de qualité déclenchent une non-indexation ? Combien de temps une page reste-t-elle en cache avant réanalyse ? Silence radio.
Sur le terrain, on observe régulièrement des pages techniquement accessibles, sans directive noindex, qui ne s'indexent jamais. Google parle d'une « bibliothèque », mais omet de préciser qu'elle applique des politiques d'acquisition opaques. [A vérifier] : les critères exacts déclenchant le refus d'indexation restent largement non documentés.
L'indexation est-elle vraiment garantie si Google crawle ma page ?
Non. Et c'est un point crucial que cette déclaration occulte. Le crawl ne garantit pas l'indexation. Google peut visiter une page, l'analyser, puis décider de ne pas la stocker dans son index.
Les raisons ? Contenu jugé trop mince, duplication détectée, faible autorité du domaine, structure technique défaillante. Problème : Google ne communique pas toujours clairement pourquoi une page est exclue. L'outil Inspection d'URL indique parfois « Explorée, actuellement non indexée » sans plus de détails.
Quelles limites cette déclaration ne mentionne-t-elle pas ?
Premier point : Google ne stocke pas tout le contenu dans les mêmes conditions. Certaines pages sont indexées mais rarement servies dans les résultats — elles existent dans l'index, mais restent invisibles pour des requêtes concurrentielles.
Deuxième point : l'index n'est pas statique. Des pages peuvent en sortir si Google considère qu'elles ne méritent plus d'y figurer — sans notification. Troisième point : la « plus grande bibliothèque au monde » filtre massivement. On estime que moins de 50 % des pages crawlées finissent indexées sur certains domaines de faible autorité. [A vérifier] : Google ne publie aucune statistique officielle sur ce taux de rejet.
Impact pratique et recommandations
Comment vérifier que mes pages sont bien indexées ?
Première méthode : la requête site:votredomaine.com dans Google. Rapide, mais imprécise — elle donne une estimation, pas un inventaire exhaustif. Deuxième méthode, bien plus fiable : la Search Console, onglet Couverture.
Examinez les pages « Exclues » et « Valides avec avertissements ». Identifiez celles marquées « Explorée, actuellement non indexée » ou « Détectée, actuellement non indexée ». Ces statuts signalent que Google a vu la page mais refuse de l'indexer. Creusez les raisons : contenu faible, duplication, balises problématiques.
Quelles actions mener pour maximiser l'indexation de mon contenu ?
Optimisez d'abord la qualité et l'unicité de chaque page. Google privilégie le contenu original, structuré, apportant une réelle valeur. Évitez les pages générées automatiquement sans profondeur éditoriale.
Ensuite, soignez la structure technique : balisage HTML sémantique (H1, H2, H3 bien hiérarchisés), temps de chargement rapide, mobile-friendly. Utilisez des sitemaps XML propres pour signaler clairement les URLs prioritaires. Vérifiez que vos fichiers robots.txt n'interdisent pas le crawl de sections importantes.
Enfin, consolidez votre maillage interne. Les pages isolées, sans liens entrants internes, ont moins de chances d'être crawlées régulièrement et donc indexées. Un bon maillage facilite la découverte et renforce la pertinence perçue par Google.
Quelles erreurs courantes bloquent l'indexation sans qu'on s'en rende compte ?
Première erreur classique : des directives noindex oubliées dans les balises meta ou les en-têtes HTTP. Ça arrive plus souvent qu'on ne le croit, surtout après des migrations ou des environnements de staging mal configurés.
Deuxième erreur : le contenu dupliqué interne massif. Google peut décider de ne pas indexer des dizaines de pages qu'il considère comme des copies, même légèrement modifiées. Troisième erreur : des temps de chargement catastrophiques ou une pagination mal gérée, qui frustrent le crawl.
- Vérifier régulièrement la Search Console, section Couverture, pour détecter les pages exclues.
- Utiliser l'outil Inspection d'URL pour diagnostiquer précisément les blocages d'indexation.
- Auditer les balises meta robots et les en-têtes HTTP pour éliminer tout noindex involontaire.
- Produire du contenu unique, approfondi et structuré — la qualité reste le premier critère.
- Optimiser la vitesse de chargement et l'expérience mobile pour faciliter le crawl.
- Soumettre un sitemap XML à jour, listant uniquement les URLs indexables prioritaires.
- Renforcer le maillage interne pour connecter toutes les pages stratégiques.
- Éviter la duplication de contenu interne en canonicalisant ou en fusionnant les pages similaires.
❓ Questions frequentes
Toutes les pages crawlées par Google sont-elles automatiquement indexées ?
Comment savoir si une page est réellement indexée par Google ?
Pourquoi certaines pages restent 'Explorée, actuellement non indexée' dans la Search Console ?
Peut-on forcer Google à indexer une page spécifique ?
Combien de temps faut-il pour qu'une nouvelle page soit indexée ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.