Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Comment Google découvre-t-il réellement vos pages via le crawling et les liens ?
- □ Comment Google construit-il réellement son index et pourquoi ça change tout pour votre SEO ?
- □ Comment Google classe-t-il réellement les résultats pour une requête donnée ?
- □ Google personnalise-t-il vraiment tous les résultats selon l'utilisateur ?
- □ Les résultats organiques Google reposent-ils vraiment uniquement sur la pertinence du contenu ?
- □ Peut-on vraiment payer Google pour améliorer son positionnement organique ?
- □ Google distingue-t-il vraiment ses annonces des résultats organiques de manière efficace ?
- □ Les ressources officielles Google suffisent-elles vraiment à optimiser votre visibilité SEO ?
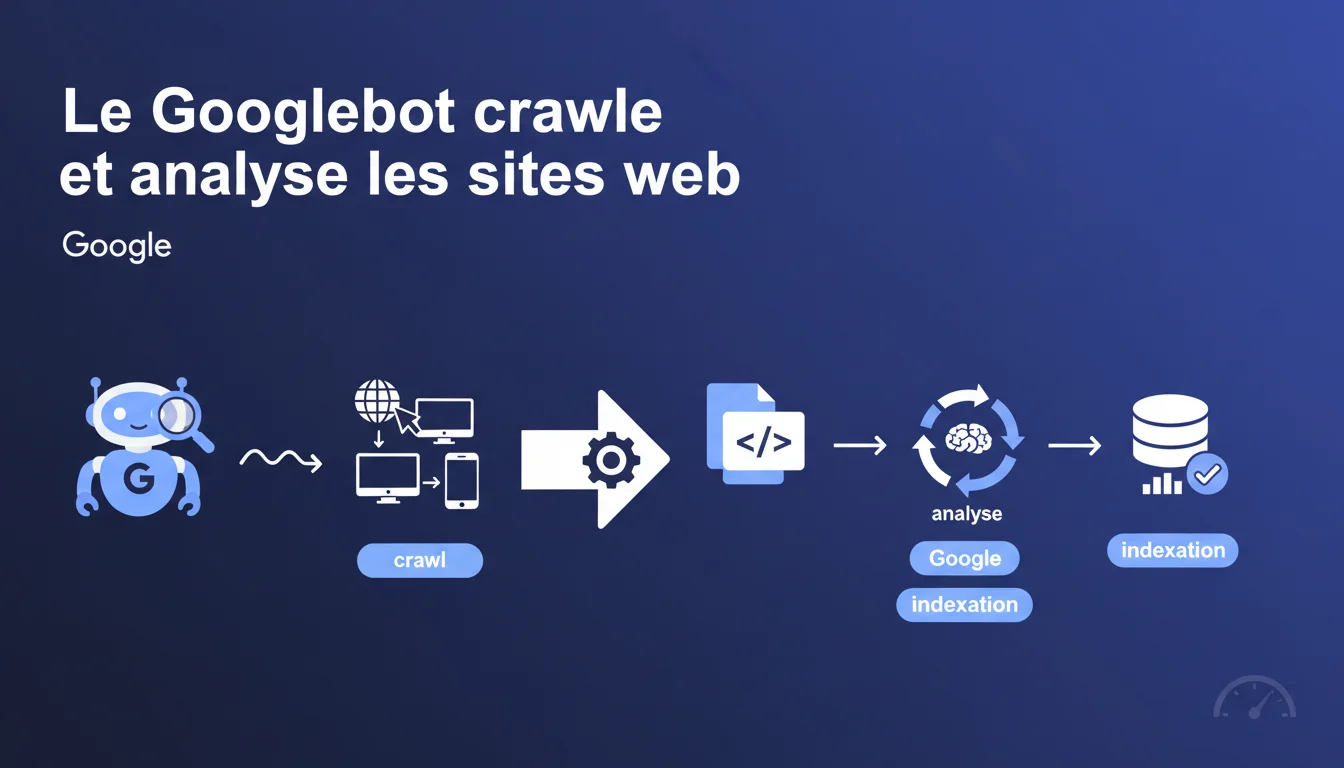
Le Googlebot explore les sites web via un processus de crawl, puis analyse leur contenu pendant la phase d'indexation pour le stocker dans l'index Google. Cette distinction entre crawl et indexation est fondamentale : un site peut être crawlé sans être indexé, ce qui explique pourquoi certaines pages n'apparaissent jamais dans les résultats de recherche malgré des visites régulières du bot.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation ?
Le crawl désigne le moment où le Googlebot visite vos pages et récupère leur contenu brut — HTML, CSS, JavaScript, ressources. C'est la première étape, purement technique.
L'indexation, elle, intervient après : Google analyse ce contenu, le comprend, l'évalue, puis décide s'il mérite une place dans son index. Une page crawlée n'est pas forcément indexée — et c'est là que beaucoup de sites perdent du trafic sans comprendre pourquoi.
Pourquoi Google sépare-t-il ces deux processus ?
Parce que crawler coûte des ressources, mais indexer engage la qualité des résultats de recherche. Google peut visiter des millions de pages par jour, mais il ne stocke que celles qui apportent une valeur unique, pertinente, et techniquement exploitable.
Si votre contenu est dupliqué, trop fin, ou techniquement inaccessible (JavaScript mal rendu, balises meta noindex, canonicals mal configurées), le crawl aura lieu — mais l'indexation sera refusée.
Quels sont les signaux qui déclenchent le crawl ?
Le Googlebot découvre de nouvelles pages via plusieurs canaux : liens internes et externes, sitemaps XML, flux RSS, soumissions via la Search Console. Plus une page reçoit de liens de qualité, plus elle sera crawlée fréquemment.
Mais attention : un crawl intensif ne garantit rien. Ce qui compte, c'est la fréquence de crawl pertinente — pas le volume brut de visites du bot.
- Le crawl est la visite technique du Googlebot sur vos pages
- L'indexation est la décision de Google de stocker (ou non) ce contenu dans son index
- Un site peut être crawlé sans être indexé — et c'est souvent le cas pour du contenu de faible qualité
- Les signaux de crawl incluent liens, sitemaps, historique de fraîcheur du site
- Le crawl budget n'est pas infini : Google priorise les pages qu'il juge importantes
Avis d'un expert SEO
Cette déclaration est-elle vraiment complète ?
Soyons honnêtes : Google simplifie beaucoup. La phrase "le Googlebot explore et indexe" laisse croire à un processus linéaire et automatique. En réalité, il y a une zone grise massive entre les deux étapes.
Le rendering JavaScript, la gestion du crawl budget, les signaux de qualité évalués avant indexation (E-E-A-T, utilité du contenu, duplication) — tout ça est passé sous silence. Google ne dit pas non plus que certaines pages peuvent rester en crawl limbo pendant des semaines, visitées mais jamais indexées. [À vérifier] sur vos propres sites via la Search Console.
Quelles nuances faut-il apporter sur le terrain ?
Premier point : le Googlebot ne "comprend" pas toujours votre contenu du premier coup. Si vous utilisez du JavaScript côté client sans pré-rendering ou SSR, le bot doit d'abord exécuter le JS — ce qui rallonge le délai et consomme du crawl budget. Et si le rendu échoue ? Pas d'indexation.
Deuxième point : Google ne crawle pas toutes vos pages avec la même intensité. Il priorise selon la popularité (backlinks), la fraîcheur, la profondeur de lien interne. Une page orpheline ou à 5 clics de la home sera marginalisée, peu importe sa qualité intrinsèque.
Dans quels cas ce processus échoue-t-il ?
J'ai vu des sites parfaitement crawlés — logs serveur en attestent — mais avec des taux d'indexation catastrophiques. Les causes ? Contenu dupliqué en interne, balises canonical en conflit, pages trop fines (moins de 150 mots), ou JavaScript mal géré.
Autre piège : les soft 404. Google crawle, ne trouve rien d'exploitable, et classe la page comme "Exclue" sans vous dire pourquoi. Résultat : vous pensez que tout va bien parce que le bot passe, mais vos pages ne rankeront jamais.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser crawl et indexation ?
Commencez par auditer vos logs serveur — c'est la seule façon de voir ce que le Googlebot crawle réellement, à quelle fréquence, et quelles ressources il charge. Comparez ensuite avec le rapport de couverture de la Search Console pour identifier les pages crawlées mais non indexées.
Nettoyez votre maillage interne : assurez-vous que vos pages stratégiques sont accessibles en 2-3 clics maximum depuis la home. Supprimez les liens vers des pages inutiles (mentions légales, CGV) depuis votre navigation principale — ils consomment du crawl budget sans valeur SEO.
Quelles erreurs éviter absolument ?
Ne bloquez jamais CSS ou JavaScript dans le robots.txt — c'est une erreur classique qui empêche le rendering correct de vos pages. Google a besoin de ces ressources pour comprendre votre contenu.
Évitez aussi les chaînes de redirections (301 → 302 → 200) et les redirections JavaScript : elles ralentissent le crawl et diluent le PageRank interne. Une redirection, c'est une étape de crawl en plus — et chaque étape coûte.
Comment vérifier que mon site est correctement indexé ?
Utilisez la commande site:votredomaine.com dans Google pour voir combien de pages sont indexées. Comparez ce chiffre avec le nombre de pages que vous souhaitez indexer. Si l'écart est important, creusez dans la Search Console.
Testez vos pages stratégiques avec l'outil "Inspection d'URL" : il simule le crawl et le rendering, et vous dit exactement ce que Google voit. Si le HTML rendu diffère de votre source, vous avez un problème de JavaScript à régler.
- Auditez vos logs serveur pour identifier les pages crawlées mais non indexées
- Optimisez votre maillage interne : 2-3 clics max depuis la home pour vos pages clés
- Ne bloquez jamais CSS/JS dans le robots.txt — Google en a besoin pour le rendering
- Éliminez les chaînes de redirections et privilégiez des 301 directes
- Vérifiez le rapport de couverture Search Console chaque semaine
- Testez le rendu de vos pages avec l'outil "Inspection d'URL"
- Supprimez ou désindexez les pages à faible valeur ajoutée (archives, tags, filtres e-commerce)
- Soumettez un sitemap XML propre — uniquement les URLs que vous voulez indexer
❓ Questions frequentes
Quelle est la différence entre être crawlé et être indexé ?
Pourquoi certaines de mes pages sont crawlées mais pas indexées ?
Comment savoir si le Googlebot visite mon site ?
Le crawl budget est-il un problème pour les petits sites ?
Comment forcer Google à indexer une page rapidement ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 24/02/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.