Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi la navigation à facettes cause-t-elle la moitié des problèmes de crawl ?
- □ Faut-il vraiment bloquer la navigation à facettes dans robots.txt ?
- □ Les paramètres d'action dans vos URLs sabotent-ils votre crawl budget ?
- □ Pourquoi Google intervient-il directement dans le code des plugins WordPress ?
- □ Les paramètres d'URL courts mettent-ils vraiment votre crawl budget en danger ?
- □ Pourquoi vos paramètres de calendrier WordPress sabotent-ils votre crawl budget ?
- □ Le double encodage d'URLs tue-t-il vraiment votre crawl budget ?
- □ Pourquoi Googlebot doit-il crawler massivement un nouveau site avant de savoir s'il vaut le coup ?
- □ Faut-il attendre 24 heures pour qu'une modification de robots.txt soit prise en compte ?
- □ Faut-il abandonner les paramètres GET pour sécuriser son crawl budget ?
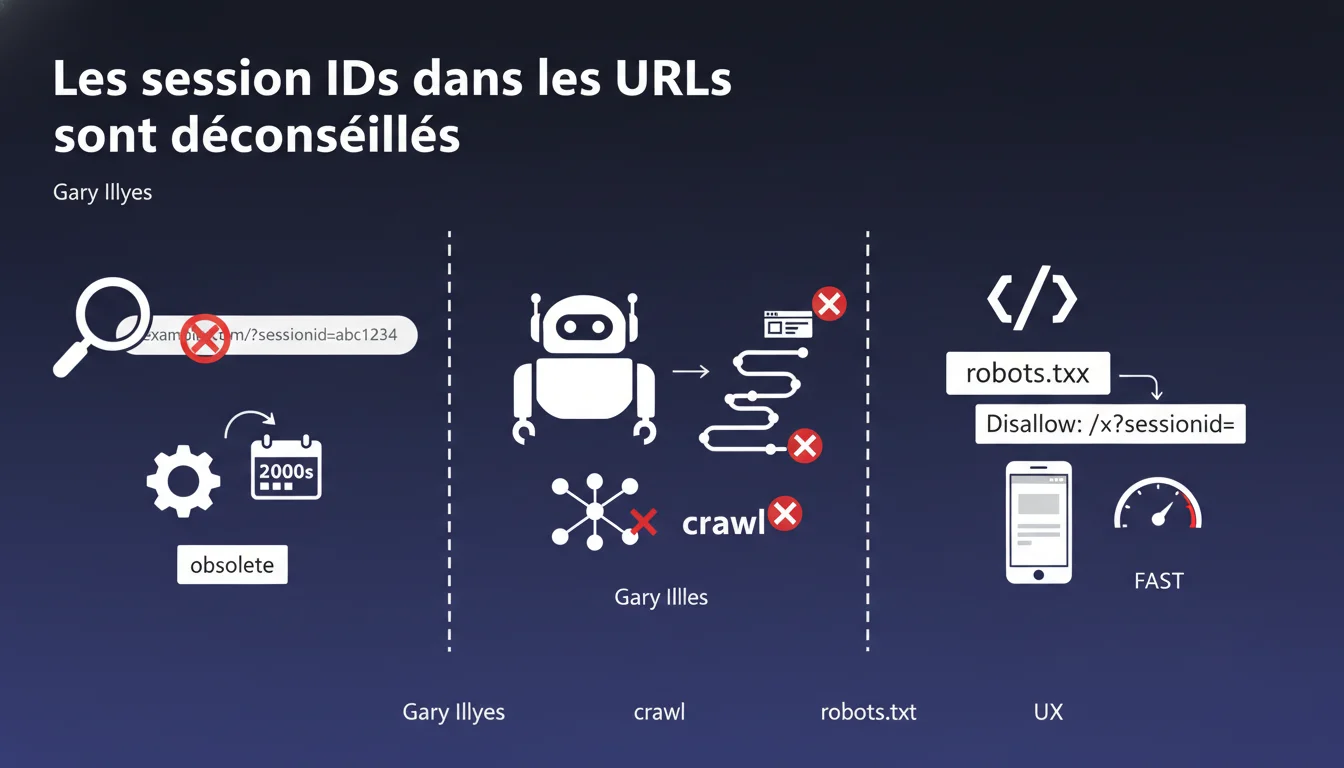
Google confirme que les session IDs dans les URLs sont une pratique obsolète qui ne sert plus à rien pour les crawlers. Ces paramètres peuvent et doivent être bloqués via robots.txt pour éviter de polluer l'index. La recommandation est claire : passez aux cookies ou aux sessions côté serveur.
Ce qu'il faut comprendre
Pourquoi les crawlers n'ont-ils pas besoin des session IDs ?
Les crawlers de Google ne maintiennent pas de persistance de session entre leurs requêtes. Contrairement à un utilisateur humain qui navigue de page en page en conservant son panier ou ses préférences, Googlebot traite chaque URL de manière isolée.
Les session IDs dans les URLs (exemple : ?sessionid=abc123) ont été conçus à une époque où les cookies n'étaient pas fiables. Aujourd'hui, ils ne font que créer des URLs dupliquées pour un même contenu, ce qui dilue le crawl budget et pollue l'index.
Quelle est la différence entre session ID et paramètre de tracking ?
Un session ID identifie une session utilisateur spécifique et change à chaque visite. Un paramètre de tracking (UTM, fbclid, etc.) sert à suivre l'origine du trafic mais reste généralement stable pour une même source.
Les deux posent le même problème SEO : ils génèrent des variantes d'URL inutiles. Mais les session IDs sont pires car ils se multiplient exponentiellement — chaque crawl peut créer une nouvelle session avec un nouvel identifiant.
Comment ces paramètres polluent-ils concrètement l'index ?
Chaque URL avec un session ID différent est techniquement une nouvelle URL pour Google. Si votre site génère des millions de combinaisons, vous forcez Google à crawler et indexer du contenu identique sous des adresses différentes.
Le résultat ? Votre crawl budget est gaspillé sur des doublons, les vraies pages importantes passent à la trappe, et vous risquez des problèmes de contenu dupliqué.
- Les crawlers ne stockent pas de sessions — ils n'ont donc aucune utilité pour ces paramètres
- Les session IDs créent des URLs dupliquées infinies qui diluent l'autorité
- Bloquer ces paramètres via robots.txt ou URL Parameters est la solution recommandée
- Privilégiez les cookies ou les sessions côté serveur pour gérer l'état utilisateur
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques observées ?
Absolument. Sur le terrain, les sites qui laissent traîner des session IDs dans leurs URLs voient régulièrement leur index exploser avec des milliers de variantes d'une même page. La Search Console remonte ces URL comme indexées, mais sans trafic.
Ce que Gary Illyes ne précise pas, c'est que bloquer ces paramètres via robots.txt n'est qu'une partie de la solution. Si vos liens internes pointent vers des URLs avec session IDs, vous créez une navigation fragmentée même pour les utilisateurs. [A verifier] : Google suit-il ces URLs même si elles sont bloquées dans robots.txt si elles apparaissent dans le maillage interne ?
Dans quels cas cette règle ne s'applique-t-elle pas ?
Soyons honnêtes : il existe des architectures legacy où migrer hors des session IDs nécessite un refonte complète. Dans ces cas, la priorité est de canonicaliser agressivement vers la version sans paramètre.
Attention aussi aux sites multi-devises ou multi-langues qui utilisent des paramètres pour gérer les préférences utilisateur. Si vous mélangez session IDs et paramètres fonctionnels (devise, langue), vous risquez de bloquer plus que prévu. La solution : séparer clairement ces deux types de paramètres.
Quelle est la meilleure alternative technique ?
Les cookies HTTP-only restent la solution la plus propre pour gérer les sessions utilisateur sans polluer les URLs. Côté serveur, stockez l'identifiant de session dans un cookie sécurisé et gérez l'état en base de données.
Pour les sites statiques ou les architectures modernes (SPA, JAMstack), le localStorage ou le sessionStorage JavaScript peuvent suffire. L'essentiel est que l'URL reste propre et identique pour tous les visiteurs d'une même page.
Impact pratique et recommandations
Que faut-il faire concrètement sur votre site ?
Commencez par un audit de vos URLs indexées dans la Search Console. Filtrez par les paramètres suspects (sessionid, sid, phpsessid, etc.) et vérifiez combien de variantes sont indexées.
Si vous trouvez des milliers d'URLs avec session IDs, deux actions prioritaires : bloquer ces paramètres dans robots.txt (ou via l'outil URL Parameters de la Search Console, même s'il est moins fiable depuis sa refonte) et implémenter des balises canonical pointant vers la version propre.
Et c'est là que ça coince. Si votre CMS ou votre framework génère automatiquement ces paramètres, vous devrez intervenir au niveau du code. Ce n'est pas toujours trivial, surtout sur des plateformes custom ou des CMS vieillissants.
Comment vérifier que votre configuration est correcte ?
Testez avec le Google URL Inspection Tool : soumettez une URL avec session ID et vérifiez si Google la crawle malgré votre blocage robots.txt. Si oui, le problème vient probablement de liens internes qui forcent le crawl.
Utilisez un crawler comme Screaming Frog pour mapper tous les liens internes contenant des session IDs. Si votre navigation interne génère ces paramètres, vous avez un problème architectural à résoudre en priorité.
- Auditer les URLs indexées dans la Search Console pour repérer les session IDs
- Bloquer ces paramètres via robots.txt (ex :
Disallow: /*?sessionid=) - Implémenter des canonicals strictes vers les URLs propres
- Migrer la gestion de session vers des cookies HTTP-only ou du stockage côté serveur
- Crawler le site pour vérifier qu'aucun lien interne ne génère de session IDs
- Surveiller l'évolution de l'index après le blocage pour confirmer la purge progressive
❓ Questions frequentes
Bloquer les session IDs dans robots.txt suffit-il à résoudre le problème ?
Les session IDs affectent-ils le ranking ou seulement le crawl budget ?
Peut-on utiliser l'outil URL Parameters de la Search Console à la place de robots.txt ?
Les cookies sont-ils toujours la meilleure alternative aux session IDs dans les URLs ?
Faut-il aussi bloquer les paramètres de tracking type UTM ou fbclid ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 03/02/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.