Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Pourquoi la navigation à facettes cause-t-elle la moitié des problèmes de crawl ?
- □ Faut-il vraiment bloquer la navigation à facettes dans robots.txt ?
- □ Pourquoi Google intervient-il directement dans le code des plugins WordPress ?
- □ Les paramètres d'URL courts mettent-ils vraiment votre crawl budget en danger ?
- □ Faut-il vraiment se débarrasser des session IDs dans vos URLs ?
- □ Pourquoi vos paramètres de calendrier WordPress sabotent-ils votre crawl budget ?
- □ Le double encodage d'URLs tue-t-il vraiment votre crawl budget ?
- □ Pourquoi Googlebot doit-il crawler massivement un nouveau site avant de savoir s'il vaut le coup ?
- □ Faut-il attendre 24 heures pour qu'une modification de robots.txt soit prise en compte ?
- □ Faut-il abandonner les paramètres GET pour sécuriser son crawl budget ?
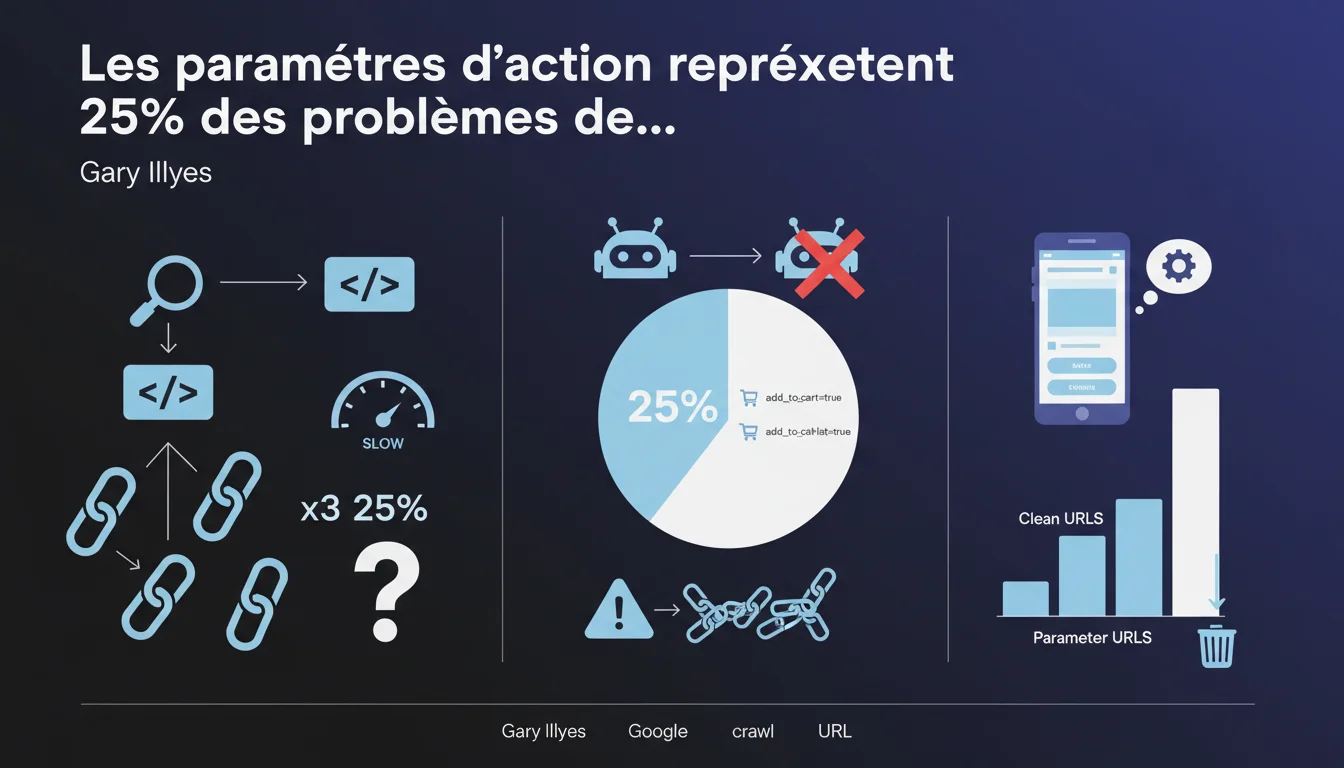
Les paramètres d'action comme add_to_cart=true représentent 25% des problèmes de crawl signalés à Google. Ces URLs inutiles doublent ou triplent l'espace crawlable sans apporter de valeur, car Googlebot n'achète pas de produits. Bloquer ces paramètres libère du crawl budget pour vos pages stratégiques.
Ce qu'il faut comprendre
Pourquoi ces paramètres posent-ils un problème de crawl ?
Les paramètres d'action génèrent des URLs distinctes pour chaque interaction utilisateur — ajouter au panier, créer une wishlist, partager un produit. Chaque variante crée une nouvelle URL que Googlebot tente de crawler, alors qu'elle affiche souvent le même contenu qu'une page produit standard.
Concrètement ? Un site avec 10 000 produits peut générer 30 000 URLs crawlables si chaque produit a trois variantes d'action. Googlebot perd du temps sur des pages sans valeur SEO pendant que des contenus stratégiques restent sous-crawlés.
Quelle est l'ampleur réelle du problème ?
Gary Illyes indique que ces paramètres représentent 25% des rapports de problèmes de crawl. C'est colossal. Un quart des signalements reçus par Google concernent ce type de pollution d'URLs.
Cette statistique révèle que beaucoup de sites e-commerce n'ont jamais pris le temps d'auditer leurs paramètres d'URL. Les plateformes e-commerce génèrent ces paramètres par défaut, et personne ne pense à les nettoyer.
Comment Google distingue-t-il ces URLs inutiles ?
Googlebot repère les paramètres d'action par leur structure : add_to_cart, add_to_wishlist, share, compare. Ces patterns sont identifiables car ils déclenchent des actions utilisateur plutôt que d'afficher du contenu unique.
Le problème : Google crawle quand même ces URLs avant de réaliser qu'elles sont inutiles. Le crawl budget est déjà consommé — le mal est fait.
- 25% des problèmes de crawl proviennent de paramètres d'action selon Google
- Ces paramètres doublent ou triplent l'espace d'URLs crawlable sans valeur SEO
- Googlebot ne peut pas acheter de produits ni créer de wishlists — ces pages lui sont inutiles
- Le crawl budget gaspillé sur ces URLs ralentit l'indexation des pages stratégiques
- Les plateformes e-commerce génèrent ces paramètres par défaut, créant une pollution invisible
Avis d'un expert SEO
Cette déclaration change-t-elle vraiment la donne pour les praticiens ?
Soyons honnêtes : les pros du SEO savent depuis des années qu'il faut nettoyer les paramètres d'URL. La vraie nouveauté, c'est le chiffre de 25% — il quantifie enfin l'ampleur du problème et légitime le temps passé sur ce sujet auprès des clients.
Ce qui manque ici ? [À vérifier] Gary ne précise pas si Google ignore automatiquement certains patterns de paramètres d'action ou si chaque URL est effectivement crawlée. La nuance compte : si Googlebot les filtre en amont, le problème est moindre que si chaque URL consomme réellement du budget.
Les observations terrain confirment-elles ce diagnostic ?
Absolument. Les audits de crawl montrent systématiquement des pics de requêtes Googlebot sur des URLs avec paramètres d'action. Les logs Apache/Nginx ne mentent pas — ces pages sont crawlées, parfois plusieurs fois par jour.
Un cas récurrent : les sites qui utilisent des liens de partage avec paramètres (utm_source, share_via) voient Googlebot suivre ces liens depuis des réseaux sociaux. Résultat : des milliers d'URLs identiques avec des paramètres de tracking différents.
Quelles situations échappent à cette règle générale ?
Certains paramètres d'action peuvent avoir une valeur SEO légitime. Exemple : un comparateur de produits qui génère des URLs /compare?product1=X&product2=Y avec du contenu unique (tableau comparatif, avis croisés). Dans ce cas, bloquer ces URLs serait contre-productif.
Et c'est là que ça coince. La déclaration de Gary est trop binaire. Elle suggère de bloquer tous les paramètres d'action, mais certains sites monétisent justement ces pages de comparaison ou de wishlist publiques. Une analyse cas par cas s'impose — pas de règle universelle.
Impact pratique et recommandations
Comment identifier les paramètres d'action qui polluent votre crawl ?
Première étape : analysez vos logs serveur. Cherchez les patterns récurrents avec add_to_cart, wishlist, share, compare dans les URLs crawlées par Googlebot. Les outils comme Screaming Frog Log File Analyser ou OnCrawl automatisent cette détection.
Deuxième étape : vérifiez dans Google Search Console, section Couverture, les URLs exclues avec mention "Détectée, actuellement non indexée". Si vous voyez des centaines de pages avec paramètres d'action, c'est un signal clair de pollution.
Quelle méthode utiliser pour bloquer ces URLs efficacement ?
Plusieurs options, du plus simple au plus robuste. Le robots.txt permet de bloquer des patterns complets : Disallow: /*add_to_cart= empêche Googlebot de crawler toute URL contenant ce paramètre.
L'alternative plus fine : configurez les paramètres d'URL dans Google Search Console. Indiquez que add_to_cart, add_to_wishlist ne changent pas le contenu de la page. Google ajustera son comportement de crawl en conséquence.
Troisième option : utilisez la balise canonical pour pointer toutes les variantes vers l'URL propre sans paramètre. Cela demande un développement côté serveur, mais c'est la solution la plus propre techniquement.
Quelles erreurs éviter absolument dans cette optimisation ?
Ne bloquez jamais un paramètre sans avoir vérifié son impact sur le trafic. Certains sites génèrent du trafic organique sur des pages de wishlist publiques ou des comparaisons produits. Un blocage brutal peut tuer des positions acquises.
Autre piège : bloquer en robots.txt sans gérer les liens internes. Si vos pages continuent de générer ces URLs dans le maillage, vous créez des liens morts. Nettoyez d'abord le code qui génère ces paramètres, puis bloquez.
- Auditez vos logs serveur pour quantifier le crawl sur paramètres d'action
- Listez tous les paramètres d'action utilisés sur votre site (panier, wishlist, share, compare)
- Vérifiez dans Search Console si ces URLs génèrent du trafic organique
- Bloquez via robots.txt les patterns sans valeur SEO :
Disallow: /*add_to_cart= - Configurez les paramètres d'URL dans Search Console pour affiner le comportement de crawl
- Implémentez des canonicals vers les URLs propres si nécessaire
- Nettoyez le code source pour arrêter la génération de liens avec paramètres d'action
- Surveillez les évolutions de crawl dans Search Console après mise en œuvre
❓ Questions frequentes
Faut-il bloquer tous les paramètres d'URL pour optimiser le crawl budget ?
Le robots.txt suffit-il pour bloquer les paramètres d'action ?
Comment vérifier si mes paramètres d'action consomment du crawl budget ?
Les paramètres UTM de tracking posent-ils le même problème ?
Si Google ignore ces URLs, pourquoi s'en préoccuper ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 03/02/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.