Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Pourquoi Google avait-il tant de mal à comprendre les mots de liaison comme 'not' dans les requêtes ?
- □ Comment Google évalue-t-il réellement la qualité de son moteur : mesures globales ou analyse segmentée ?
- □ La pertinence topique est-elle devenue un critère SEO dépassé ?
- □ Google applique-t-il vraiment un principe d'équilibre entre types de sites dans ses résultats ?
- □ Google privilégie-t-il vraiment la promotion plutôt que la pénalité ?
- □ Pourquoi Google a-t-il conçu les Featured Snippets autour de la compréhension sémantique plutôt que du matching de mots-clés ?
- □ Comment Google mesure-t-il vraiment la satisfaction des utilisateurs dans ses résultats de recherche ?
- □ E-E-A-T est-il vraiment un facteur de ranking ou juste un mythe SEO ?
- □ Pourquoi Google se méfie-t-il du volume de requêtes comme indicateur de qualité ?
- □ Les Quality Rater Guidelines sont-elles vraiment un mode d'emploi pour le SEO ?
- □ Comment Google priorise-t-il les bugs de recherche et qu'est-ce que ça change pour le SEO ?
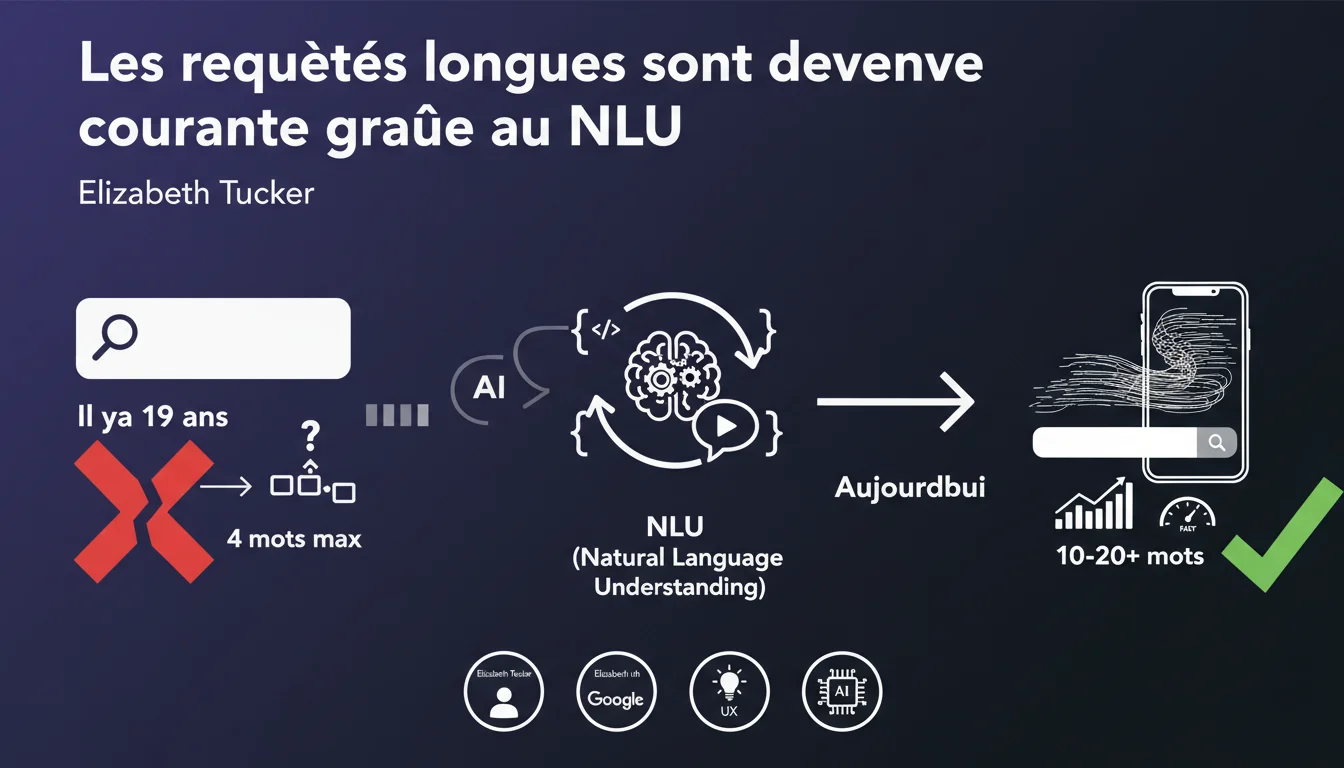
Google traite désormais régulièrement des requêtes de 10 à 20 mots ou plus, contre 4 mots maximum il y a 19 ans. Cette évolution massive, portée par les progrès en compréhension du langage naturel (NLU), redistribue les cartes de la stratégie sémantique. La notion même de « longue traîne » telle qu'on la connaissait devient obsolète.
Ce qu'il faut comprendre
Qu'est-ce qui a changé dans le comportement de recherche des utilisateurs ?
Les utilisateurs ont radicalement modifié leur façon d'interroger Google. La démocratisation de la recherche vocale et l'essor des interfaces conversationnelles ont banalisé les requêtes formulées en langage naturel complet.
Concrètement ? On est passé de « hôtel Paris 15e » à « quel est le meilleur hôtel pas cher dans le 15e arrondissement de Paris avec petit déjeuner inclus ». Ce changement n'est pas marginal — il redéfinit la distribution statistique du trafic organique.
Comment le NLU de Google gère-t-il ces requêtes longues ?
Le Natural Language Understanding permet à Google de décomposer et interpréter des phrases complexes. L'algorithme identifie l'intention, les entités, les modificateurs contextuels et les relations entre concepts.
MUM et BERT ont accéléré cette capacité. Google ne cherche plus simplement des correspondances de mots-clés — il reconstruit le sens de la requête pour matcher avec le contenu le plus pertinent, même si la formulation diffère.
Quelle est la définition actuelle d'une requête « longue » ?
La barre a drastiquement monté. Ce qui constituait autrefois une longue traîne classique (4-5 mots) relève aujourd'hui du standard. Les vraies longues traînes se situent désormais entre 10 et 20 mots, voire au-delà.
Cette inflation sémantique fragmente encore davantage le volume de recherche. La courbe longue traîne s'étire, avec une proportion croissante de requêtes uniques ou quasi-uniques qui ne seront jamais répétées à l'identique.
- Evolution comportementale : passage du keyword stuffing aux phrases conversationnelles complètes
- Rôle du NLU : compréhension contextuelle et intentionnelle plutôt que matching lexical
- Redéfinition de la longue traîne : seuil passé de 4 à 10-20 mots ou plus
- Fragmentation accrue : augmentation des requêtes uniques impossibles à anticiper
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment ce qu'on observe sur le terrain ?
Oui, mais avec des nuances sectorielles importantes. Dans les verticales B2C grand public (tourisme, santé, e-commerce), la tendance est nette : les requêtes conversationnelles longues dominent, surtout sur mobile et via assistants vocaux.
En revanche, dans certains secteurs B2B techniques ou sur desktop, les requêtes courtes et précises restent majoritaires. Un ingénieur cherchant de la doc technique tapera « API GraphQL pagination » plutôt qu'une phrase de 15 mots. [A vérifier] : Google ne fournit aucune donnée chiffrée sur la répartition sectorielle de cette évolution.
Peut-on encore optimiser pour des requêtes courtes de manière efficace ?
Absolument. Soyons honnêtes : la majorité du volume de recherche reste concentrée sur des requêtes de 2 à 5 mots dans de nombreuses verticales. Abandonner cette base serait une erreur stratégique.
Le problème, c'est que cette déclaration pousse implicitement vers une approche « tout sémantique conversationnel ». Or, les requêtes courtes à fort volume génèrent toujours l'essentiel du trafic qualifié dans beaucoup de cas. L'arbitrage reste donc à faire au cas par cas, selon vos analytics réels.
Faut-il revoir toute sa stratégie de contenu suite à cette évolution ?
Pas nécessairement tout revoir, mais ajuster la balance. Si votre stratégie actuelle repose uniquement sur l'optimisation de mots-clés courts et moyens, vous laissez une part croissante du trafic sur la table.
Et c'est là que ça coince : produire du contenu qui répond efficacement à des requêtes ultra-longues et variées demande une approche radicalement différente. On parle de couverture thématique exhaustive, de clusters sémantiques, de FAQ étendues — bref, un investissement content non négligeable.
Impact pratique et recommandations
Comment adapter concrètement sa production de contenu ?
Première étape : analyser vos Search Console data pour identifier la proportion réelle de requêtes longues dans votre trafic actuel. Filtrez par nombre de mots, croisez avec les taux de clics et positions — vous verrez où se situe votre gisement.
Ensuite, structurez votre contenu en clusters thématiques plutôt qu'en pages isolées. Une page pilier couvre l'intention générale, des pages satellites répondent aux variations longues et spécifiques. Le maillage interne devient critique pour signaler ces relations à Google.
Quels formats privilégier pour capter ces requêtes conversationnelles ?
Les FAQ structurées en schema.org restent un levier puissant. Chaque question-réponse peut matcher une requête longue spécifique tout en renforçant votre topical authority globale.
Les contenus « guide complet », listes détaillées et comparatifs exhaustifs fonctionnent également bien — à condition d'être réellement exhaustifs, pas juste des agrégations superficielles de 800 mots.
Faut-il abandonner la recherche classique de mots-clés ?
Non, il faut la compléter. Les outils keywords traditionnels restent utiles pour le socle, mais ils ne capturent qu'une fraction des requêtes longues réelles. Complétez avec :
- Analyse des données Search Console pour identifier les requêtes longues réelles générant des impressions
- Exploitation des suggestions « People Also Ask » et « Related Searches »
- Utilisation d'outils NLP pour cartographier les entités et relations sémantiques de votre thématique
- Intégration de sections FAQ basées sur les vraies questions utilisateurs (support client, forums, réseaux sociaux)
- Structuration du contenu en clusters thématiques avec maillage interne cohérent
- Monitoring continu des performances par longueur de requête pour ajuster la stratégie
Ces ajustements représentent un changement méthodologique profond. La recherche sémantique avancée, l'architecture d'information en clusters et l'optimisation pour des intentions conversationnelles complexes demandent une expertise pointue et des ressources dédiées. Si votre équipe interne manque de bande passante ou de compétences NLP/sémantique, s'appuyer sur une agence SEO rompue à ces nouvelles approches peut accélérer significativement vos résultats tout en évitant les erreurs coûteuses de transition.
❓ Questions frequentes
Les requêtes de 10 à 20 mots représentent-elles vraiment un volume significatif de trafic ?
Faut-il réécrire tout mon contenu existant en langage conversationnel ?
Le NLU de Google comprend-il toutes les nuances des requêtes longues ?
Comment mesurer l'impact réel de l'optimisation pour requêtes longues ?
Les outils de recherche de mots-clés classiques deviennent-ils obsolètes ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 27/06/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.