Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- 5:33 Peut-on vraiment contrôler quelle image apparaît dans les résultats de recherche texte ?
- 7:30 Pourquoi vos rapports Search Console se contredisent-ils constamment ?
- 8:40 Faut-il vraiment uploader sa liste de désaveu uniquement sur le domaine actuel ?
- 10:06 Pourquoi Google classe-t-il vos pages internes au-dessus de votre page catégorie ?
- 11:21 Pourquoi le test d'URL publique échoue-t-il si souvent dans Search Console ?
- 15:15 Est-ce que des pages « Crawlé - non indexé » pénalisent tout votre site ?
- 16:27 Pourquoi Google détecte-t-il mes pages catégories e-commerce comme du contenu dupliqué ?
- 18:55 Comment Google interprète-t-il réellement l'intention derrière vos requêtes ?
- 21:21 Les URLs simples influencent-elles vraiment le classement Google ?
- 22:22 Pourquoi Google peut-il ignorer votre JavaScript si vous placez un noindex dans le head ?
- 24:24 Les iframes dans le <head> sabotent-elles vraiment votre SEO ?
- 26:06 Comment vérifier précisément le comportement des redirections pour Googlebot ?
- 28:06 Une redirection 301 mal configurée peut-elle bloquer l'indexation de vos pages ?
- 30:28 Comment contrôler la date affichée dans les résultats de recherche Google ?
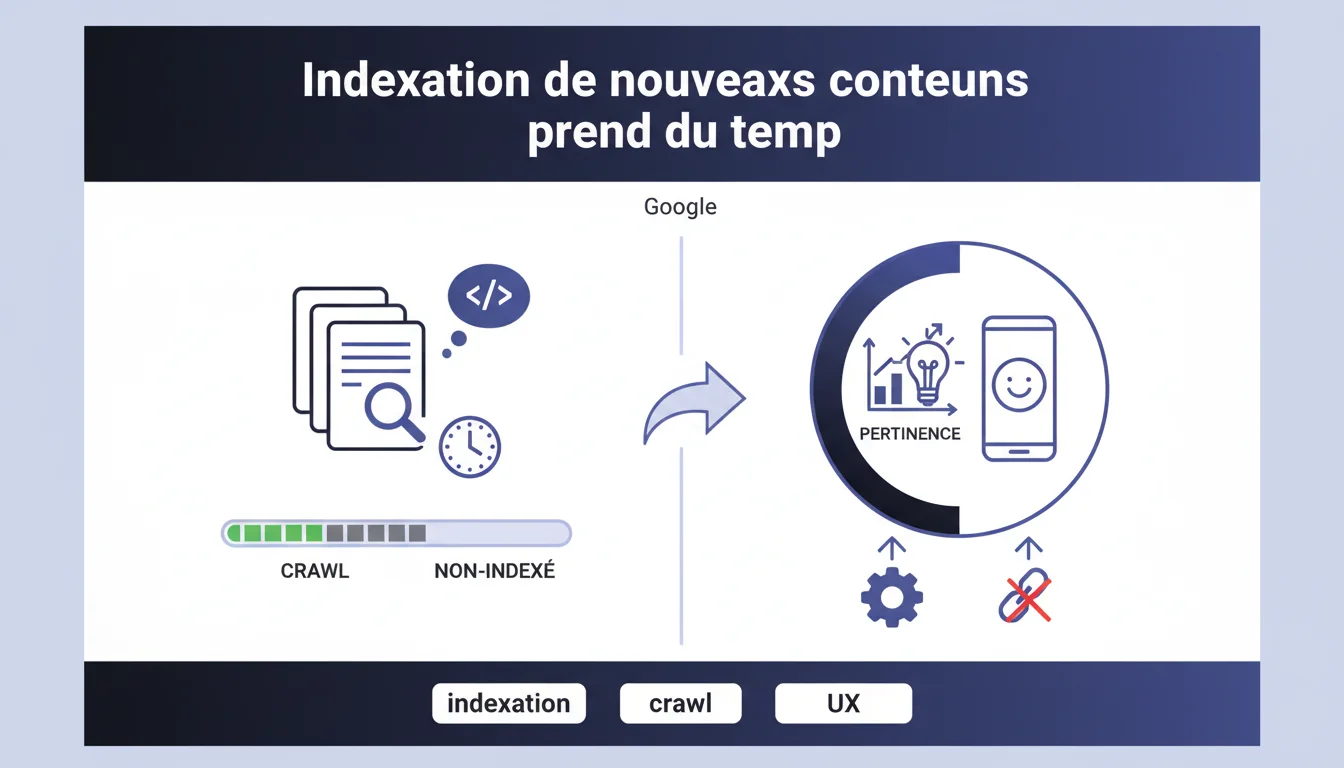
Google affirme que l'indexation de nouveaux contenus demande du temps et que le statut 'Crawlé - non indexé' relève davantage d'un problème de pertinence et de qualité éditoriale que d'une question technique. La priorité doit donc se porter sur l'amélioration du contenu lui-même plutôt que sur des ajustements techniques de crawl ou de sitemap.
Ce qu'il faut comprendre
Que signifie réellement ce statut 'Crawlé - non indexé' ?
Ce statut apparaît dans la Search Console quand Googlebot a visité une URL sans pour autant l'intégrer à l'index. La page est connue, analysée, mais jugée non prioritaire ou insuffisamment distinctive pour mériter une place dans les résultats de recherche.
Contrairement à d'autres statuts d'indexation, celui-ci n'indique pas un blocage technique — pas de robots.txt, pas de balise noindex, pas d'erreur serveur. Le crawl s'est déroulé normalement. Le problème se situe ailleurs.
Pourquoi Google insiste-t-il sur la notion de temps ?
L'indexation n'est pas instantanée, même pour des contenus de qualité. Google doit évaluer la pertinence, comparer avec l'existant, allouer des ressources. Un nouveau contenu peut rester en attente plusieurs jours, voire semaines, avant d'être indexé — surtout sur des sites à faible autorité ou avec un historique de contenu médiocre.
Cette déclaration rappelle qu'il faut patienter avant de diagnostiquer un problème structurel. Beaucoup de praticiens paniquent dès qu'une page reste non indexée 48h après publication, alors que c'est parfaitement normal dans la plupart des cas.
En quoi la qualité prime-t-elle sur la technique ici ?
Google oriente clairement le diagnostic : si vos pages sont crawlées mais pas indexées, le premier réflexe ne doit pas être de bricoler le sitemap XML ou d'ajouter des balises canonical. Il faut questionner la valeur éditoriale : ce contenu apporte-t-il quelque chose d'unique ? Répond-il à une intention de recherche claire ?
Cette hiérarchisation est cohérente avec les guidelines qualité de Google — l'algorithme privilégie la pertinence perçue avant tout. Un contenu techniquement parfait mais sans substance restera hors index.
- Le statut 'Crawlé - non indexé' n'est pas un bug technique dans la majorité des cas
- L'indexation prend du temps, surtout sur des sites récents ou à faible autorité
- La qualité éditoriale et la pertinence sont les premiers leviers à actionner
- Google pousse à penser contenu avant infrastructure
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Sur des sites établis avec une bonne fréquence de crawl, les nouveaux contenus de qualité s'indexent souvent en quelques heures. Le délai évoqué par Google s'observe surtout sur des sites neufs, peu autoritaires, ou ayant un historique de contenu faible.
Là où ça coince : beaucoup de cas 'Crawlé - non indexé' persistent malgré une qualité éditoriale correcte. On voit des pages uniques, bien structurées, avec un angle original, rester bloquées pendant des mois. Dans ces situations, des actions techniques — ajustement du maillage interne, suppression de contenus zombies, consolidation de pages similaires — débloquent souvent l'indexation. [A vérifier] : Google simplifie probablement pour éviter que les webmasters s'éparpillent, mais la réalité est plus nuancée.
Quelles nuances faut-il apporter à cette recommandation ?
Premièrement, « améliorer la qualité » reste flou. Google ne donne aucun critère objectif — longueur ? profondeur ? expertise démontrée ? Cette imprécision laisse les praticiens dans le brouillard. Un contenu « de qualité » pour Google n'est pas toujours celui qu'un expert métier considérerait comme tel.
Deuxièmement, ignorer totalement les aspects techniques est risqué. Si ton site génère massivement des URLs crawlées mais non indexées — des milliers de pages produits avec descriptions génériques, des filtres à facettes mal gérés — le problème n'est pas juste éditorial. C'est aussi un sujet d'architecture et de crawl budget. Consolider, noindexer, canonicaliser devient indispensable.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Sur les sites e-commerce volumineux, l'indexation sélective est souvent voulue par Google pour ne pas saturer son index avec des pages quasi-identiques. Améliorer la qualité de 10 000 fiches produits similaires ne changera rien — il faut plutôt travailler la différenciation, le maillage, et parfois accepter que toutes les pages ne seront jamais indexées.
Même chose sur les sites d'actualité : un article publié à 18h peut être crawlé à 18h05 et indexé à 18h10 si le site a une bonne autorité et un crawl fréquent. Le « temps » évoqué par Google ne s'applique pas uniformément — il dépend fortement du profil du site.
Impact pratique et recommandations
Que faut-il faire concrètement face à ce statut ?
Première étape : attendre. Si la page a été publiée il y a moins de deux semaines, ne paniquez pas. Vérifiez qu'elle est bien crawlable, qu'elle apparaît dans votre sitemap, et laissez Google travailler.
Si le statut persiste au-delà de trois semaines, passez à l'analyse éditoriale : cette page apporte-t-elle une valeur unique ? Est-elle mieux documentée que les contenus concurrents déjà indexés ? Répond-elle à une intention de recherche précise ?
Ensuite, renforcez le maillage interne vers cette page depuis des pages déjà bien indexées et autoritaires. Google suit les liens — si votre nouveau contenu est orphelin ou relégué à trois clics de la home, son indexation sera retardée.
Quelles erreurs éviter dans ce contexte ?
Ne tombez pas dans le piège du sur-optimisation technique : ajouter frénétiquement des canonical, multiplier les demandes d'indexation via la Search Console, modifier le sitemap toutes les heures. Ça ne sert à rien et ça peut même dégrader le signal envoyé à Google.
Évitez aussi de publier en masse du contenu médiocre pour « tester ». Google apprend de l'historique de votre site — si vous avez un pattern de contenus faibles régulièrement crawlés mais non indexés, l'algorithme sera plus sélectif sur vos futures publications.
Comment vérifier que votre contenu mérite l'indexation ?
Comparez votre page avec les 10 premiers résultats Google sur la requête ciblée. Posez-vous la question franchement : est-ce que mon contenu apporte quelque chose de différent, plus complet, mieux structuré ? Si la réponse est non, Google n'a aucune raison de l'indexer.
Utilisez les outils d'analyse sémantique pour vérifier la couverture thématique : abordez-vous les sous-sujets attendus ? Répondez-vous aux questions connexes que se posent les utilisateurs ?
- Vérifier que la page est techniquement crawlable (pas de noindex, robots.txt OK)
- Patienter au minimum 2 semaines avant de diagnostiquer un problème
- Analyser la valeur éditoriale : unicité, profondeur, pertinence
- Renforcer le maillage interne depuis des pages déjà indexées
- Comparer avec les contenus concurrents déjà en SERP
- Si taux élevé de pages crawlées-non indexées : auditer l'architecture globale
- Éviter les demandes d'indexation répétées ou les modifications techniques compulsives
❓ Questions frequentes
Combien de temps faut-il attendre avant de considérer qu'une page crawlée ne sera jamais indexée ?
Faut-il supprimer les pages en statut 'Crawlé - non indexé' ?
Le statut 'Crawlé - non indexé' affecte-t-il le crawl budget ?
Demander l'indexation manuelle via la Search Console aide-t-il vraiment ?
Un bon maillage interne peut-il suffire à débloquer l'indexation ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.