Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- 5:33 Peut-on vraiment contrôler quelle image apparaît dans les résultats de recherche texte ?
- 7:30 Pourquoi vos rapports Search Console se contredisent-ils constamment ?
- 8:40 Faut-il vraiment uploader sa liste de désaveu uniquement sur le domaine actuel ?
- 10:06 Pourquoi Google classe-t-il vos pages internes au-dessus de votre page catégorie ?
- 11:21 Pourquoi le test d'URL publique échoue-t-il si souvent dans Search Console ?
- 13:33 Pourquoi Google privilégie-t-il la qualité du contenu sur la technique face au statut 'Crawlé - non indexé' ?
- 15:15 Est-ce que des pages « Crawlé - non indexé » pénalisent tout votre site ?
- 16:27 Pourquoi Google détecte-t-il mes pages catégories e-commerce comme du contenu dupliqué ?
- 18:55 Comment Google interprète-t-il réellement l'intention derrière vos requêtes ?
- 21:21 Les URLs simples influencent-elles vraiment le classement Google ?
- 24:24 Les iframes dans le <head> sabotent-elles vraiment votre SEO ?
- 26:06 Comment vérifier précisément le comportement des redirections pour Googlebot ?
- 28:06 Une redirection 301 mal configurée peut-elle bloquer l'indexation de vos pages ?
- 30:28 Comment contrôler la date affichée dans les résultats de recherche Google ?
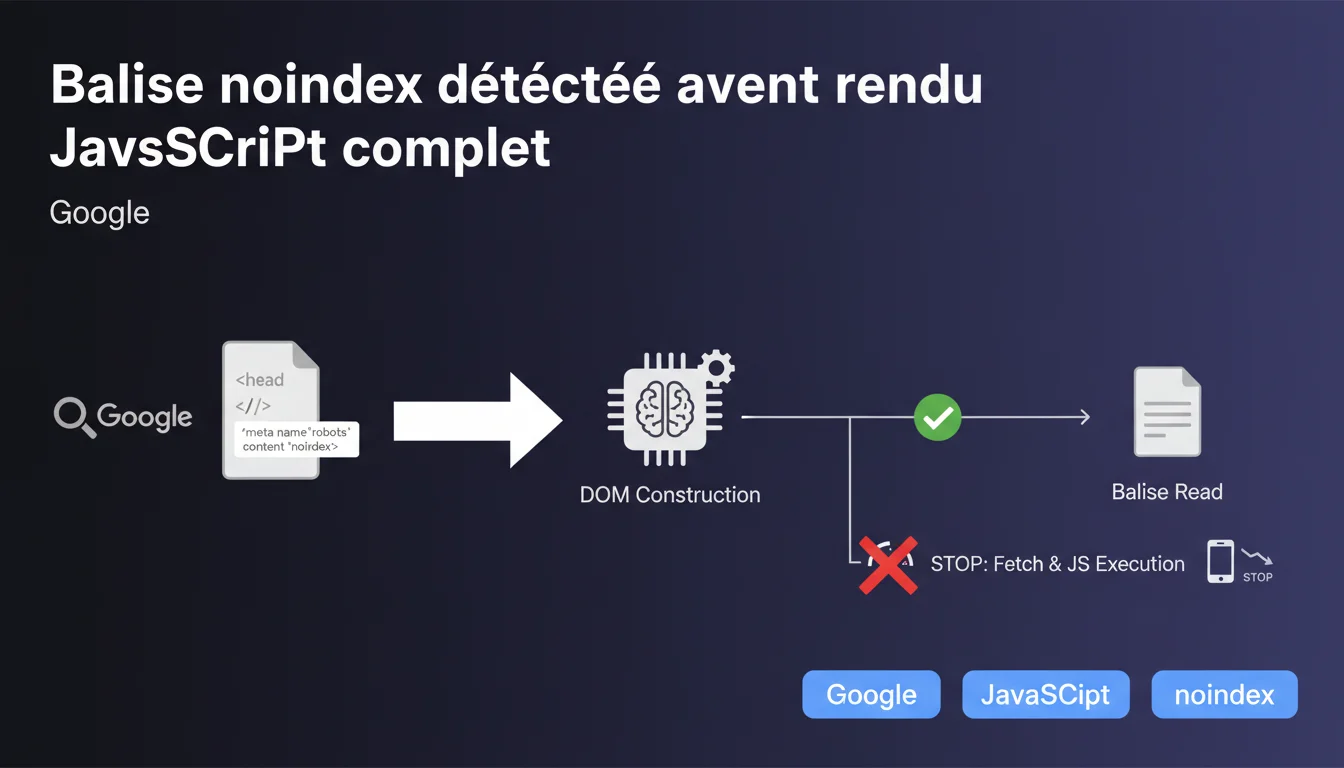
Googlebot détecte la balise noindex dès l'analyse du head HTML, avant l'exécution complète du JavaScript. Si elle est présente, Google peut interrompre le fetch de ressources et le rendu JS. La construction initiale du DOM est nécessaire pour cette lecture, donc une partie du JavaScript s'exécute quand même.
Ce qu'il faut comprendre
À quel moment précis Googlebot lit-il la balise noindex ?
Googlebot analyse la balise noindex au moment où il parcourt la section <head> du HTML brut. Pas besoin d'attendre le rendu complet de la page ou l'exécution de tous vos scripts.
Concrètement, si votre noindex est injecté côté serveur dans le HTML initial, Googlebot le voit immédiatement. Si elle est ajoutée via JavaScript, c'est plus nuancé — la construction initiale du DOM est nécessaire pour que le bot lise cette directive.
Google arrête-t-il vraiment tout traitement quand il voit un noindex ?
Oui, mais avec une subtilité. Google peut arrêter le fetch de ressources supplémentaires et l'exécution complète du JavaScript une fois la balise détectée. Le mot-clé ici, c'est "peut" — ce n'est pas systématique.
La construction initiale du DOM est généralement exécutée, ce qui signifie qu'une partie du JS tourne quand même. Google ne coupe pas brutalement au premier octet du head, il construit le DOM minimal pour lire les balises critiques.
Quelle est la différence entre HTML statique et JavaScript pour le noindex ?
Dans un HTML statique, la balise noindex est immédiatement visible. Googlebot la lit sans ambiguïté, aucun rendu nécessaire. Cas le plus fiable.
Avec du JavaScript, ça dépend de la phase d'injection. Si votre framework SPA ajoute le noindex après le premier rendu, Google va probablement le détecter lors de la construction du DOM initial. Mais si votre JS met trop de temps ou plante, vous créez une zone d'incertitude.
- Le noindex est détecté dans le head HTML, pas après un rendu complet
- Google peut interrompre le fetch de ressources et l'exécution JS complète une fois le noindex trouvé
- La construction initiale du DOM s'exécute généralement, donc une partie du JS tourne
- Un noindex côté serveur est plus fiable qu'un noindex injecté tard en JavaScript
- Si le noindex apparaît uniquement après plusieurs secondes de JS, vous prenez un risque
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Globalement, oui. Les tests montrent que Googlebot détecte bien les balises noindex présentes dans le HTML initial, même sur des sites JavaScript. Mais la formulation "peut arrêter" est volontairement floue.
On observe régulièrement des pages noindex qui apparaissent quand même dans les rapports de crawl, avec des ressources chargées. Google ne précise pas les critères qui déclenchent cet arrêt ou non. [À vérifier] : dans quels cas précis Google continue-t-il à tout charger malgré le noindex ?
Quelles nuances faut-il apporter à cette affirmation ?
La phrase "la construction initiale du DOM est nécessaire" est cruciale. Ça veut dire que si votre noindex est injecté par un script externe lourd qui met 3 secondes à charger, Google risque de ne pas attendre.
Deuxième point : Google parle du "fetch de ressources". Concrètement, ça signifie que même avec un noindex détecté tôt, une partie du budget crawl a déjà été consommée pour charger le HTML et démarrer le DOM. Ce n'est pas un arrêt immédiat au sens strict.
Soyons honnêtes — cette déclaration laisse trop de zones grises pour des cas edge. Si votre site est un SPA complexe avec hydratation progressive, vous ne savez pas exactement à quelle milliseconde Google lit le noindex.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre noindex est ajouté uniquement après une interaction utilisateur ou un événement asynchrone tardif, Google ne le verra probablement jamais. Cas classique : un noindex ajouté après un appel API qui prend du temps.
Autre cas problématique : les Single Page Applications où le head est reconstruit dynamiquement après le premier rendu. Si le noindex n'est pas dans le HTML initial envoyé par le serveur, vous jouez avec le feu.
Impact pratique et recommandations
Que faut-il faire concrètement pour sécuriser un noindex ?
Injectez la balise côté serveur dans le HTML brut. C'est la méthode la plus fiable, sans dépendance au JavaScript. Votre noindex est là dès le premier octet reçu par Googlebot.
Si vous utilisez un framework JavaScript (Next.js, Nuxt, etc.), assurez-vous que le noindex est rendu lors du Server-Side Rendering ou du Static Site Generation. Pas en client-side uniquement.
Testez systématiquement avec la Search Console : outil d'inspection d'URL, onglet "HTML". Vérifiez que Google voit bien votre noindex dans le code source retourné.
Quelles erreurs éviter absolument ?
Ne comptez jamais sur un noindex ajouté par un script tiers (tag manager, plugin WordPress mal configuré) si celui-ci charge en différé. Google peut passer à côté.
Évitez les configurations hybrides où le noindex apparaît parfois en HTML statique, parfois en JavaScript selon la route. Ça crée des incohérences que Googlebot ne pardonne pas.
Ne mélangez pas les directives : un noindex dans le head et un robots.txt qui bloque le crawl, c'est contre-productif. Google a besoin de crawler la page pour lire le noindex.
- Privilégier un noindex côté serveur dans le HTML initial
- Tester avec l'outil d'inspection d'URL de la Search Console
- Vérifier que le noindex est présent dans le code source brut, pas seulement après rendu
- Éviter les scripts tiers tardifs pour injecter le noindex
- Ne pas bloquer le crawl via robots.txt si vous voulez que Google lise le noindex
- Documenter les pages noindex pour éviter les erreurs lors des déploiements
Comment vérifier que votre configuration fonctionne ?
Utilisez curl ou un outil de fetch HTTP brut pour récupérer le HTML initial. Si le noindex n'apparaît pas dans cette réponse, c'est qu'il arrive trop tard.
Comparez ensuite avec le rendu JavaScript dans la Search Console. Si vous voyez un écart, c'est un signal d'alarme. Google devrait voir le noindex dans les deux cas si votre implémentation est correcte.
❓ Questions frequentes
Googlebot exécute-t-il tout le JavaScript avant de lire le noindex ?
Un noindex ajouté uniquement en JavaScript est-il fiable ?
Faut-il bloquer le crawl via robots.txt si une page a un noindex ?
Comment tester si Google détecte bien mon noindex ?
Peut-on mettre un noindex uniquement dans les X-Robots-Tag HTTP ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.