Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- 5:33 Peut-on vraiment contrôler quelle image apparaît dans les résultats de recherche texte ?
- 7:30 Pourquoi vos rapports Search Console se contredisent-ils constamment ?
- 8:40 Faut-il vraiment uploader sa liste de désaveu uniquement sur le domaine actuel ?
- 10:06 Pourquoi Google classe-t-il vos pages internes au-dessus de votre page catégorie ?
- 13:33 Pourquoi Google privilégie-t-il la qualité du contenu sur la technique face au statut 'Crawlé - non indexé' ?
- 15:15 Est-ce que des pages « Crawlé - non indexé » pénalisent tout votre site ?
- 16:27 Pourquoi Google détecte-t-il mes pages catégories e-commerce comme du contenu dupliqué ?
- 18:55 Comment Google interprète-t-il réellement l'intention derrière vos requêtes ?
- 21:21 Les URLs simples influencent-elles vraiment le classement Google ?
- 22:22 Pourquoi Google peut-il ignorer votre JavaScript si vous placez un noindex dans le head ?
- 24:24 Les iframes dans le <head> sabotent-elles vraiment votre SEO ?
- 26:06 Comment vérifier précisément le comportement des redirections pour Googlebot ?
- 28:06 Une redirection 301 mal configurée peut-elle bloquer l'indexation de vos pages ?
- 30:28 Comment contrôler la date affichée dans les résultats de recherche Google ?
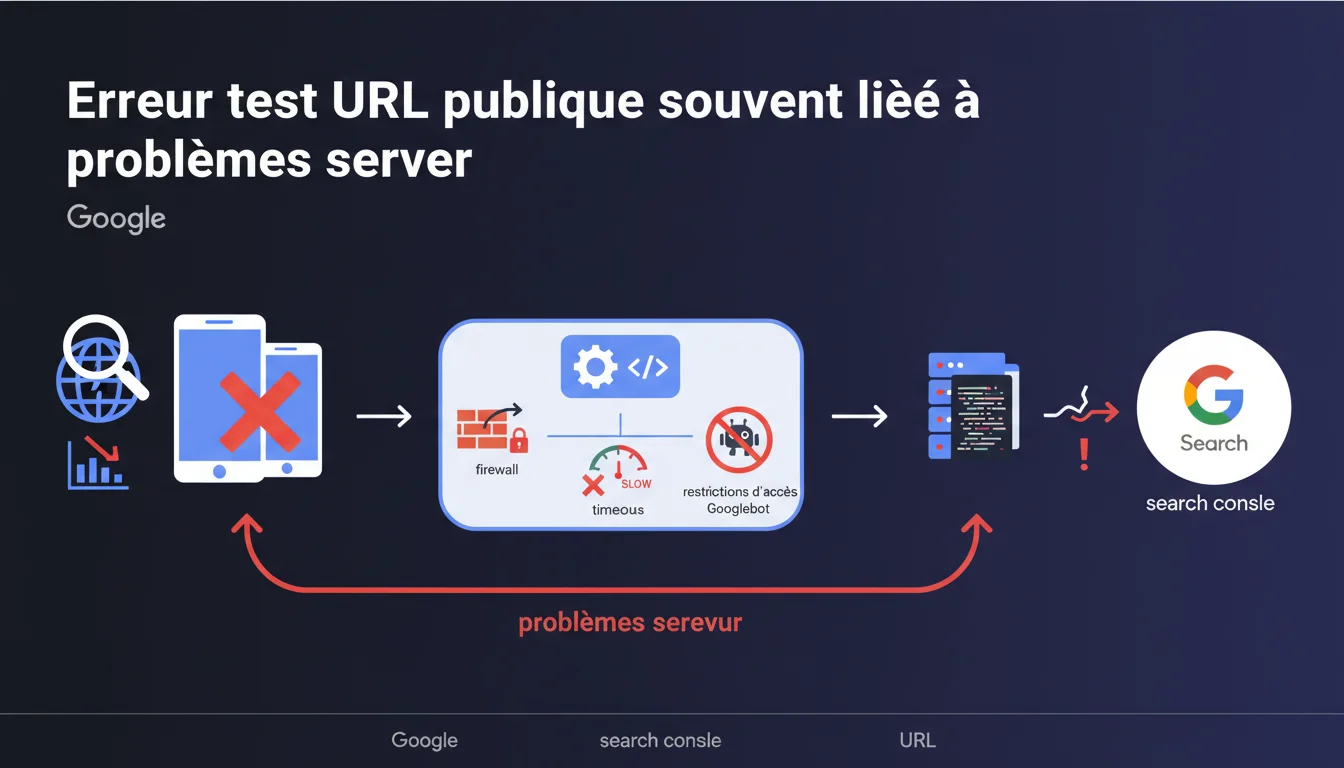
Quand le test d'URL publique génère une erreur dans Search Console, c'est généralement que Googlebot ne peut pas récupérer ou rendre le contenu complètement. Google recommande de vérifier les logs serveur pour identifier les blocages par firewall, les timeouts ou les restrictions d'accès spécifiques à son crawler.
Ce qu'il faut comprendre
Que signifie concrètement cette erreur de test d'URL publique ?
L'outil de test d'URL publique dans Search Console simule le comportement de Googlebot face à une page donnée. Quand il génère une erreur, cela signale que le robot rencontre un obstacle technique l'empêchant de récupérer ou d'interpréter le contenu comme il le ferait lors d'un crawl normal.
Cette erreur n'est pas anodine — elle indique que Google pourrait ne jamais indexer correctement la page concernée, ou qu'il la perçoit différemment de ce que vous voyez dans votre navigateur. Le problème se situe rarement côté Google, mais quasi systématiquement dans la configuration serveur ou les règles de sécurité qui bloquent son accès.
Pourquoi les logs serveur sont-ils la première piste à explorer ?
Les logs serveur enregistrent toutes les requêtes HTTP reçues, y compris celles de Googlebot. Ils révèlent précisément ce qui s'est passé au moment du test : un code erreur 403, un timeout après X secondes, une IP bloquée par le pare-feu.
Google pointe explicitement vers cette vérification parce que les causes les plus fréquentes sont invisibles depuis votre navigateur. Un firewall peut autoriser les IP « normales » mais bloquer celles de Google. Un CDN peut imposer des règles de rate limiting trop strictes qui pénalisent Googlebot. Les logs sont la seule source de vérité.
Quels types de blocages provoquent cette erreur ?
Google mentionne trois familles de problèmes : les blocages par firewall, les timeouts et les restrictions d'accès spécifiques à Googlebot. Chacun renvoie à une configuration serveur distincte qu'il faut auditer méthodiquement.
- Firewall : règles IP trop strictes, WAF (Web Application Firewall) qui bloque les user-agents suspects
- Timeouts : serveur trop lent, temps de réponse > 10-15 secondes, ressources bloquantes qui ralentissent le rendu
- Restrictions Googlebot : règles robots.txt mal configurées, blocage via .htaccess, CDN qui challenge le bot comme un humain
- Problèmes de rendu : JavaScript qui ne s'exécute pas correctement, ressources critiques bloquées empêchant l'affichage final
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même une constante frustrante. La majorité des erreurs de test d'URL publique que nous rencontrons proviennent de configurations serveur restrictives pensées pour bloquer les bots malveillants, mais qui frappent aussi Googlebot. Les équipes infra ne font pas toujours la distinction entre un scraper agressif et un crawler légitime.
Le réflexe « vérifier les logs » est le bon — mais encore faut-il y avoir accès. Sur des hébergements mutualisés ou certains SaaS, c'est parfois impossible. Dans ce cas, il faut passer par des tests indirects : outils de crawl externes, monitoring synthétique, comparaison entre user-agents. [À vérifier] : Google ne précise pas si certaines catégories d'hébergement sont plus souvent concernées, mais empiriquement, les infra « sécurité maximale » sont surreprésentées.
Quelles nuances faut-il apporter à cette recommandation ?
Google parle de « récupérer ou rendre complètement le contenu », ce qui mélange deux étapes distinctes du crawl. La récupération concerne le HTTP brut (fetch), le rendu concerne l'exécution JavaScript et la construction du DOM final. Une erreur peut survenir à l'une ou l'autre étape, et les solutions diffèrent radicalement.
Si le fetch échoue, c'est un problème réseau/accès classique. Si le rendu échoue, c'est souvent lié à des ressources JavaScript tierces qui timeout, des API qui ne répondent pas au bot, ou des frameworks front mal configurés. La déclaration de Google reste vague sur cette distinction — elle aurait gagné à séparer les deux scénarios.
Dans quels cas cette règle ne suffit-elle pas ?
Parfois, les logs ne montrent rien d'anormal : pas de 4xx, pas de 5xx, des temps de réponse corrects. Pourtant, le test échoue. C'est là que ça coince.
Les causes moins évidentes incluent : des redirections infinies invisibles dans les logs sommaires, des certificats SSL/TLS qui posent problème à certaines IP de Google, des configurations nginx/Apache qui renvoient des réponses vides sous certaines conditions de charge. Dans ces cas, il faut croiser plusieurs sources : logs applicatifs, monitoring APM, traces réseau complètes.
Impact pratique et recommandations
Que faut-il faire concrètement quand cette erreur apparaît ?
La première action est de récupérer les logs serveur correspondant à la date et l'heure exacte du test d'URL. Search Console affiche un timestamp — utilisez-le pour filtrer les lignes où le user-agent contient « Googlebot ». Identifiez le code HTTP retourné, le temps de réponse, l'URL exacte appelée.
Ensuite, reproduisez le test avec un user-agent Googlebot via curl ou un outil de crawl (Screaming Frog, OnCrawl, etc.) en ciblant la même URL. Comparez le résultat avec ce que vous obtenez via un navigateur standard. Si les deux diffèrent, vous avez confirmé un traitement spécifique du bot.
Quelles erreurs éviter dans le diagnostic ?
Ne vous fiez pas uniquement à ce que vous voyez dans votre navigateur. Un site peut s'afficher parfaitement pour vous mais être totalement inaccessible à Googlebot à cause d'une règle firewall, d'une géo-restriction IP ou d'un challenge JavaScript obligatoire.
Évitez aussi de corriger « au hasard » sans avoir identifié la cause racine. Désactiver un WAF entier pour résoudre le problème crée un risque de sécurité. Mieux vaut whitelister les IP de Googlebot de manière ciblée, ou ajuster les règles de rate limiting pour exempter les user-agents légitimes.
- Récupérer les logs serveur au moment exact du test (timestamp Search Console)
- Filtrer les requêtes avec user-agent « Googlebot » et analyser les codes HTTP retournés
- Reproduire le test avec curl en utilisant le user-agent de Googlebot
- Vérifier les règles firewall, WAF et CDN pour identifier les blocages IP ou user-agent
- Contrôler les timeouts serveur (doit répondre en < 10 secondes)
- Tester le rendu JavaScript via l'outil de test d'URL et comparer avec le HTML brut
- Vérifier robots.txt et les directives X-Robots-Tag pour exclure un blocage volontaire
- Whitelister les plages IP officielles de Googlebot si nécessaire
Comment s'assurer que le problème est résolu durablement ?
Une fois la correction appliquée, relancez le test d'URL publique dans Search Console. Attendez quelques minutes — le cache peut jouer. Si le test passe, demandez une réindexation de l'URL via l'interface.
Mais ne vous arrêtez pas là. Vérifiez que les autres pages du site ne rencontrent pas le même souci en croisant les rapports de couverture et les logs sur plusieurs jours. Un problème de timeout intermittent peut ne se manifester que sous charge, ou à certains moments de la journée.
❓ Questions frequentes
Le test d'URL publique a échoué, mais mon site s'affiche normalement dans mon navigateur. Pourquoi ?
Où trouver les plages IP officielles de Googlebot pour les whitelister ?
Un timeout de combien de secondes fait échouer le test d'URL publique ?
Faut-il corriger toutes les erreurs de test d'URL ou seulement celles des pages importantes ?
Le test passe maintenant, mais Google n'a toujours pas réindexé ma page. Que faire ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.