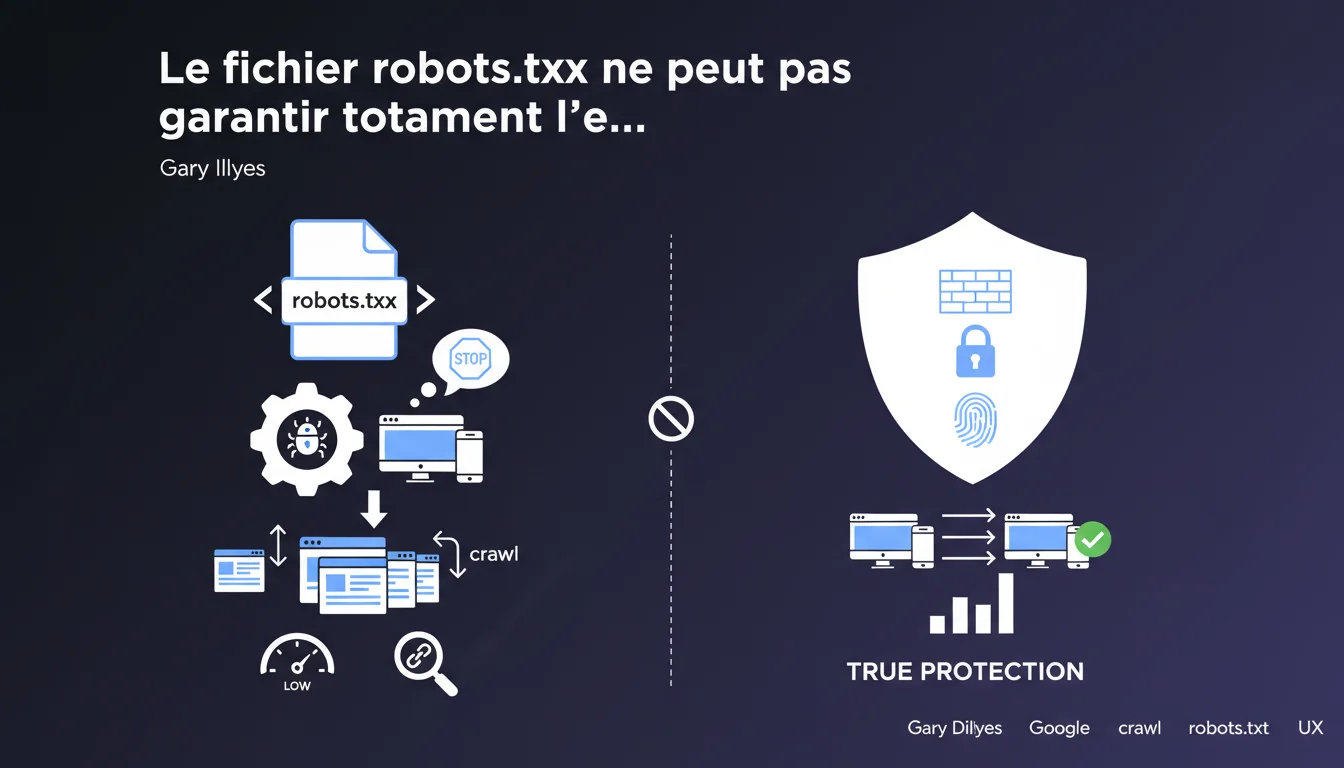
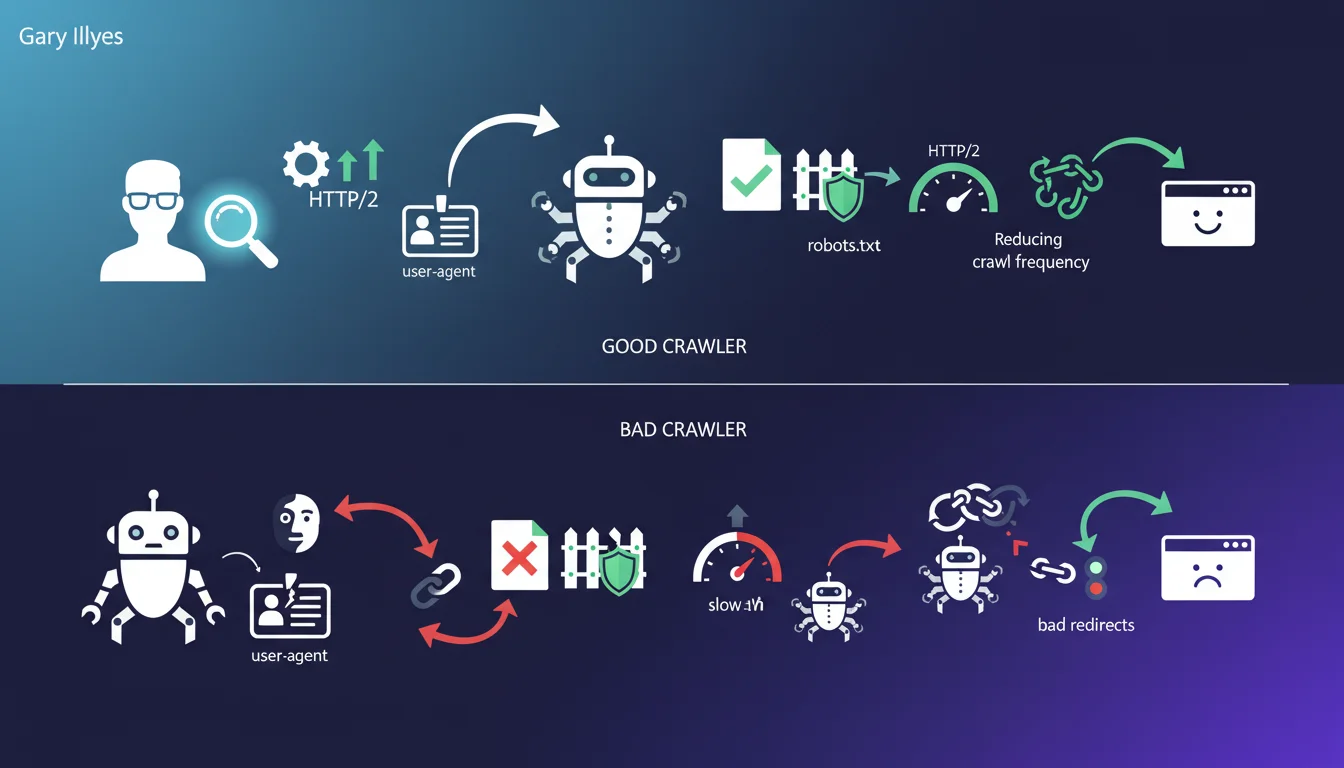
Déclarations dans les mêmes thématiques, pouvant enrichir votre compréhension du sujet.
Soyez le premier informé à chaque nouvelle déclaration officielle Google SEO, avec l'analyse complète incluse.