Official statement
Other statements from this video 7 ▾
- □ Faut-il encore utiliser rel=next et rel=prev pour la pagination ?
- □ Google rend-il vraiment l'intégralité de vos pages JavaScript ?
- □ Le HTML sémantique renforce-t-il vraiment la confiance de Google dans votre contenu ?
- □ Google lit-il vraiment vos retours sur sa documentation SEO ?
- □ Peut-on vraiment faire confiance à la documentation officielle de Google ?
- □ Pourquoi vos scores PageSpeed Insights changent-ils à chaque test ?
- □ Lighthouse calcule-t-il vraiment ses scores de manière transparente ?
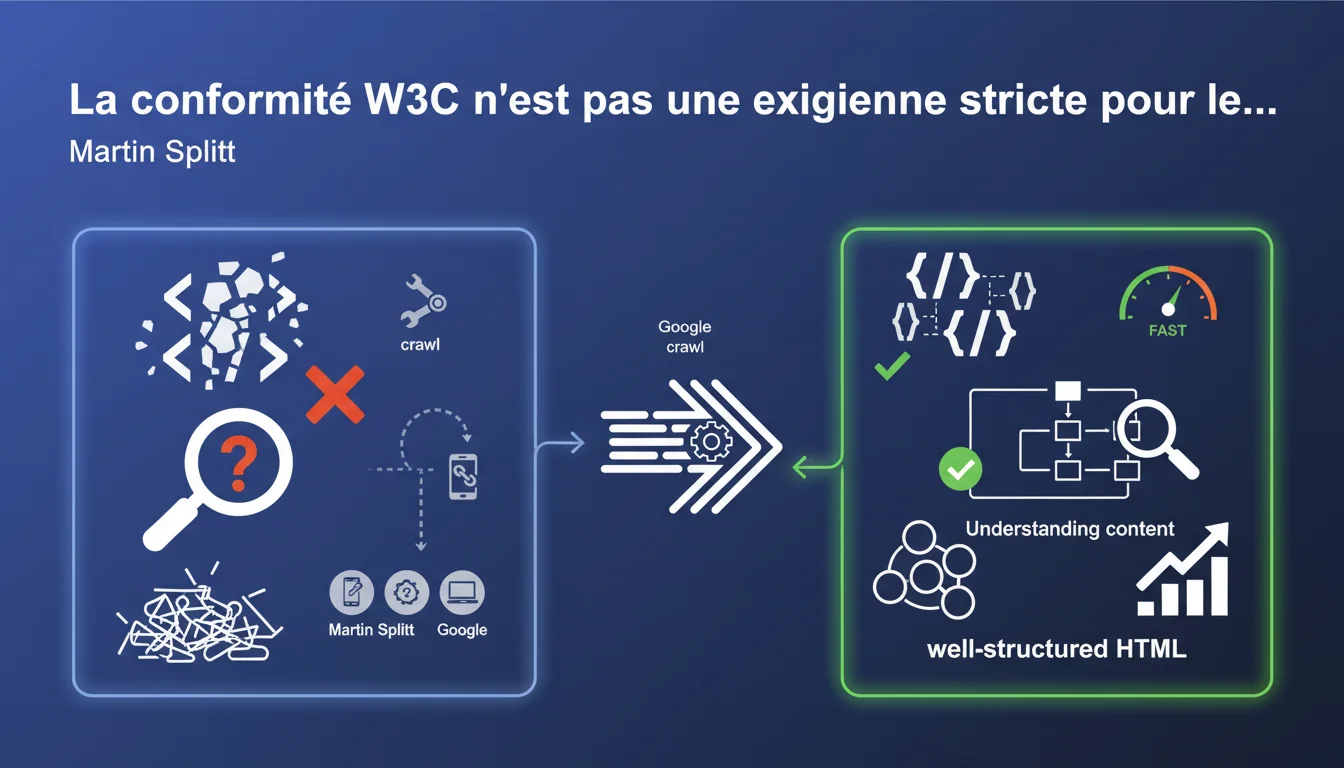
Google does not require strict W3C validation to crawl and understand your pages. The search engine tolerates HTML errors and tries to interpret the content even if the code is not perfect, but clean and semantic markup remains an advantage for facilitating analysis.
What you need to understand
Why doesn’t Google care about perfect W3C validation? <\/h3>
Google designs its crawler to confront the real web, not a theoretical one. The majority of sites contain HTML errors <\/strong> — unclosed tags, misspelled attributes, incorrectly nested structures. If Googlebot required strict W3C compliance, it would reject a massive portion of the indexable web.<\/p> The crawler uses error tolerance <\/strong> mechanisms similar to modern browsers. It rebuilds the DOM tree even when the HTML is shaky, applying inference and automatic correction rules. The goal: to extract meaning, not to penalize imperfect code.<\/p> Splitt mentions semantic and well-structured HTML <\/strong> without precisely defining what this threshold is. In practical terms, this means: appropriate tags for content (H1-H6 headers, lists, paragraphs), correct usage of standard attributes, and absence of errors that block parsing.<\/p> The difference with complete W3C validation? Google tolerates minor errors (obsolete attributes, slightly incorrect tag order) as long as the logical structure remains coherent <\/strong>. A site may fail the W3C validator while being perfectly interpreted by Googlebot.<\/p> Some errors degrade interpretation to the point of affecting understanding. Tags closed in the wrong place <\/strong>, nesting breaking the hierarchy of content, or poorly escaped JavaScript tags cause fragmented DOMs.<\/p> Google tries to correct, but the result is not guaranteed <\/strong>. If the crawler has to guess where a paragraph begins or which element contains the main title, the risk of misinterpretation increases — and with it, the risk of imperfect indexing.<\/p>What does Google consider to be “well-structured” HTML? <\/h3>
What HTML errors really cause issues? <\/h3>
SEO Expert opinion
Is this statement consistent with observed practices? <\/h3>
Yes, largely. Hundreds of field tests confirm that Google indexes and ranks sites with W3C validation errors. E-commerce sites with 200+ errors on the validator <\/strong> continue to perform in SEO as long as the overall structure remains readable.<\/p> It is observed that Google prioritizes semantic consistency <\/strong> over absolute technical compliance. A site with a few W3C errors but a clear content hierarchy outperforms a technically valid site but poorly structured semantically.<\/p> Splitt brushes over the subject by stating that Google “tries to make sense,” without specifying the tolerance threshold <\/strong> or the types of critical errors. This vague wording leaves practitioners in the dark. [To be verified] <\/strong>: to what extent does Google really tolerate? In practice, some types of errors have measurable effects. Poorly closed JavaScript <\/strong> can block client-side rendering and affect dynamic indexing. Malformed Schema.org tags break the Rich Snippet. Google “tries” to correct but does not always succeed.<\/p> Some contexts require stricter code. AMP and Web Stories <\/strong> impose strict validations — an error blocks eligibility. Rich Snippets rely on precise Schema.org markup: a JSON-LD syntax error prevents enhanced results from displaying.<\/p> The JavaScript rendering <\/strong> complicates the equation. If the initial HTML is broken and the JavaScript hydration fails, Google may only see partial or empty content. Error tolerance works better on classic static HTML.<\/p>What nuances should be added to this claim? <\/h3>
In which cases does this rule not apply? <\/h3>
Practical impact and recommendations
What should you actually do regarding W3C validation? <\/h3>
There's no need to aim for 100% W3C perfection. Focus on structural errors <\/strong> that break readability: unclosed tags in critical sections (header, main, article), incorrect nesting of lists or tables, missing attributes on images (alt).<\/p> Use the W3C validator as a diagnostic tool <\/strong>, not as an absolute judge. If an error reported concerns an obsolete attribute but has no impact (e.g., border on an image), ignore it. If it affects the DOM structure or semantic tags, correct it.<\/p> Prioritize errors that affect the content hierarchy <\/strong>: multiple H1s, jumps in heading levels (H2 → H5), paragraph tags closed in the wrong place. These errors disrupt Google’s extraction of relevance signals.<\/p> Systematically correct errors on structured data <\/strong> (JSON-LD, Microdata) and critical tags for indexing (canonical, hreflang, meta robots). Here, Google’s tolerance is zero — a syntax error disables the directive.<\/p> Complete W3C validation is not a prerequisite for Google SEO, but clean and semantically coherent HTML <\/strong> remains a competitive advantage. Focus on the logical structure of content rather than absolute technical compliance.<\/p> These technical optimizations often require thorough analysis of site architecture and advanced expertise to distinguish critical errors from noise. If your team lacks time or resources to audit and correct code quality, support from a specialized SEO agency can be relevant to establish a targeted improvement strategy and measure the real impact on your organic performance.<\/p><\/div>Which HTML errors really deserve correction? <\/h3>
❓ Frequently Asked Questions
Google pénalise-t-il un site qui échoue à la validation W3C ?
Un HTML valide W3C améliore-t-il mon positionnement SEO ?
Quelles erreurs HTML bloquent réellement l'indexation Google ?
Dois-je corriger toutes les erreurs remontées par le validateur W3C ?
Le balisage Schema.org doit-il être strictement valide pour fonctionner ?
🎥 From the same video 7
Other SEO insights extracted from this same Google Search Central video · published on 13/01/2022
🎥 Watch the full video on YouTube →Related statements
Get real-time analysis of the latest Google SEO declarations
Be the first to know every time a new official Google statement drops — with full expert analysis.
💬 Comments (0)
Be the first to comment.