Official statement
Other statements from this video 6 ▾
- □ Les Core Web Vitals sont-ils vraiment un facteur de classement Google ?
- □ Faut-il vraiment passer des mois à optimiser les Core Web Vitals ?
- □ Les Core Web Vitals sont-ils vraiment un facteur de classement SEO ?
- □ Google est-il vraiment patient avec le rendering JavaScript ou faut-il s'inquiéter de la vitesse ?
- □ Une page ultra-rapide mais vide peut-elle ranker grâce aux Core Web Vitals ?
- □ Les Core Web Vitals ont-ils vraiment transformé l'écosystème web comme le prétend Google ?
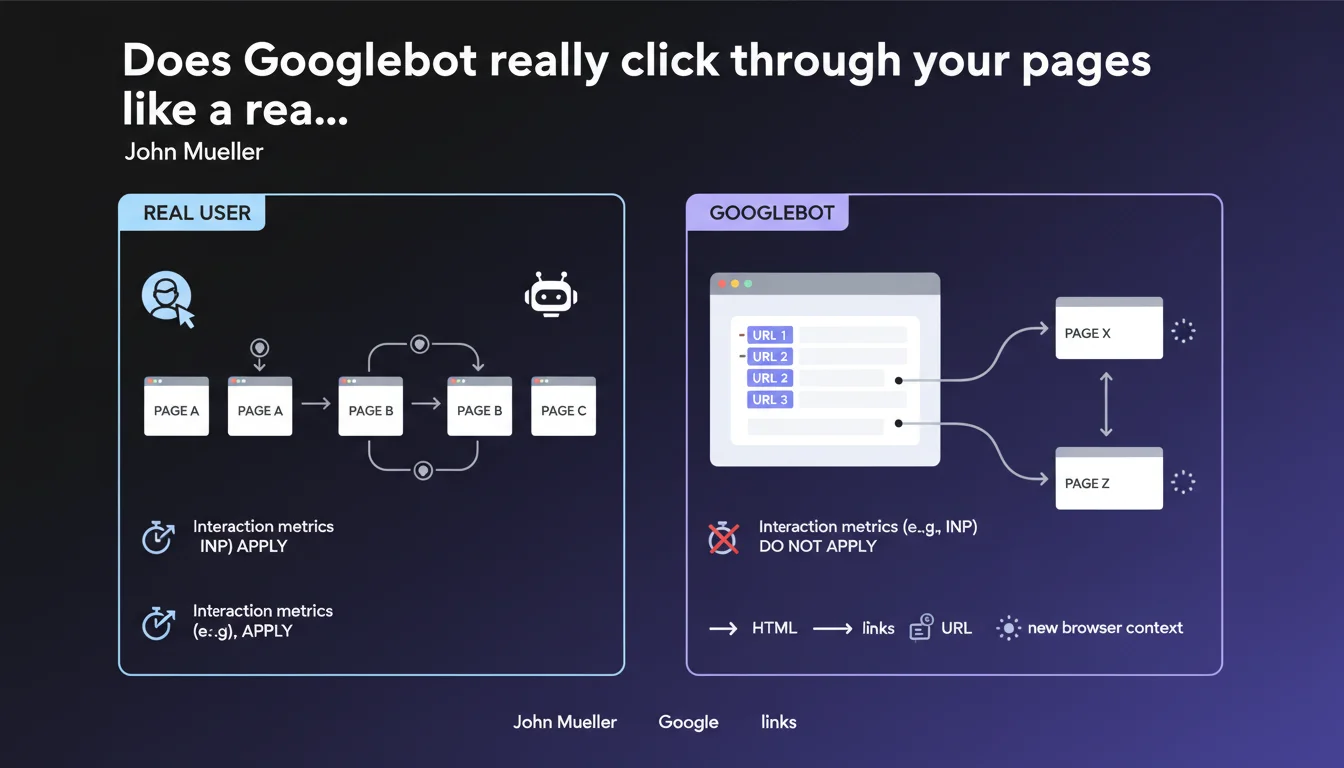
Googlebot does not navigate from page to page by clicking like a real user does. Each URL is loaded in an isolated browser context after link extraction. User interaction metrics like INP therefore do not reflect what the crawler actually experiences.
What you need to understand
How does Googlebot actually explore a website in practice?
Googlebot's behavior differs radically from that of a human visitor. No clicks are simulated — the bot first extracts all links present in the HTML code, then loads each discovered URL in a completely fresh rendering environment.
Each crawled page starts in a fresh browser context, with no navigation history or persistent session state. Concretely, Googlebot does not maintain cookies between two URLs, does not keep active JavaScript cache from one page to another, and does not simulate any DOM interactions the way a Selenium script would.
Why does this distinction impact Core Web Vitals?
INP (Interaction to Next Paint) measures responsiveness to user interactions — clicks, keyboard presses, touch events. Yet Googlebot generates no interactions during crawling. It passively loads the rendered content, period.
This metric comes exclusively from CrUX data (Chrome User Experience Report), meaning real Chrome users navigating your site. The crawler itself never contributes to these interaction statistics. It observes the final render, but does not evaluate the smoothness of interactions.
What are the key takeaways?
- Complete isolation: each crawled URL starts in a new rendering environment
- No simulated clicks: Googlebot extracts links from HTML/JavaScript then loads URLs directly
- INP not measured by the crawler: only real user data (CrUX) counts for this metric
- No session persistence: cookies, localStorage, JavaScript cache do not carry over from one crawled page to another
- Rendering remains important: even without clicks, Googlebot executes JavaScript and waits for DOM stability
SEO Expert opinion
Is this statement consistent with field observations?
Absolutely. Server logs show that Googlebot loads URLs in parallel, without respecting the order of appearance in the DOM or simulating a user journey. Two pages linked to each other may be crawled hours apart, or even by different Googlebot instances.
Tests with JavaScript-triggered links confirm the bot does not simulate any interaction. It extracts URLs from the source code (initial HTML + rendered JavaScript), but never triggers onclick, onmouseover, or touch events. If your link only appears after a hover or click, Googlebot will not find it.
In which cases does this isolation cause problems?
Poorly designed Single Page Applications (SPAs) suffer greatly. If your navigation relies on JavaScript transitions that modify the app's global state without updating the URL, Googlebot will only see the entry page. Each URL must be crawlable independently.
Sites with progressive authentication or dynamic paywalls also need to reconsider their approach. Googlebot does not maintain sessions — if your content reveals itself after a sequence of interactions, the crawler will never access it. [To verify]: some sites report strange behavior with lazy-loaded content triggered by scroll, but Google remains unclear on the exact level of vertical scroll simulation.
Should you still optimize INP for SEO?
Of course — but not for Googlebot. INP is part of the Core Web Vitals used as a ranking signal, so it directly impacts your positioning. Simply put, this metric comes from CrUX, not from the crawler itself.
The distinction matters: optimizing INP improves the real user experience, which can indirectly boost SEO through behavioral signals (bounce rate, time on site, etc.). But don't waste time trying to "fool" Googlebot with interactions — it never clicks, so it measures nothing.
Practical impact and recommendations
What should you verify immediately on your site?
Test the accessibility of your links without interaction. Open your site with JavaScript disabled or in a headless rendering tool — all critical links must appear in the initial HTML or after JS execution, but without requiring a prior click.
Audit your Single Page Applications: each route must correspond to a unique crawlable URL. Client-side-only transitions that modify the DOM without updating the URL are invisible to Googlebot. Implement SSR (Server-Side Rendering) or pre-rendering if necessary.
What common mistakes should you absolutely avoid?
Never hide strategic content behind event triggers — onclick, onhover, undetectable infinite onscroll. Googlebot extracts links present in the code, period. If a link doesn't exist before interaction, it doesn't exist for the crawler.
Stop relying on session persistence across crawled pages. Cookies do not follow Googlebot from one URL to another — each context is fresh. If your architecture assumes shared state (global JS variable, localStorage), it will break during crawling.
How should you adapt your technical SEO strategy?
- Ensure all important links exist in the rendered HTML without requiring interaction
- Implement unique URLs for each page/application state — eliminate purely JavaScript transitions
- Optimize INP for real users (CrUX), not for a hypothetical "interactive crawl"
- Test your site with headless tools (Puppeteer, Playwright) to simulate Googlebot's isolated behavior
- Audit server logs: if linked pages are crawled at different times, that's normal — adjust your crawl budget accordingly
- Verify that critical content loads without depending on session state or persistent cookies
❓ Frequently Asked Questions
Googlebot exécute-t-il le JavaScript même sans cliquer ?
Les métriques INP impactent-elles le SEO si Googlebot ne clique pas ?
Mon site SPA avec routing client-side est-il crawlable correctement ?
Les cookies fonctionnent-ils d'une page crawlée à l'autre ?
Faut-il optimiser les interactions pour améliorer le crawl ?
🎥 From the same video 6
Other SEO insights extracted from this same Google Search Central video · published on 28/03/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.