Official statement
Other statements from this video 4 ▾
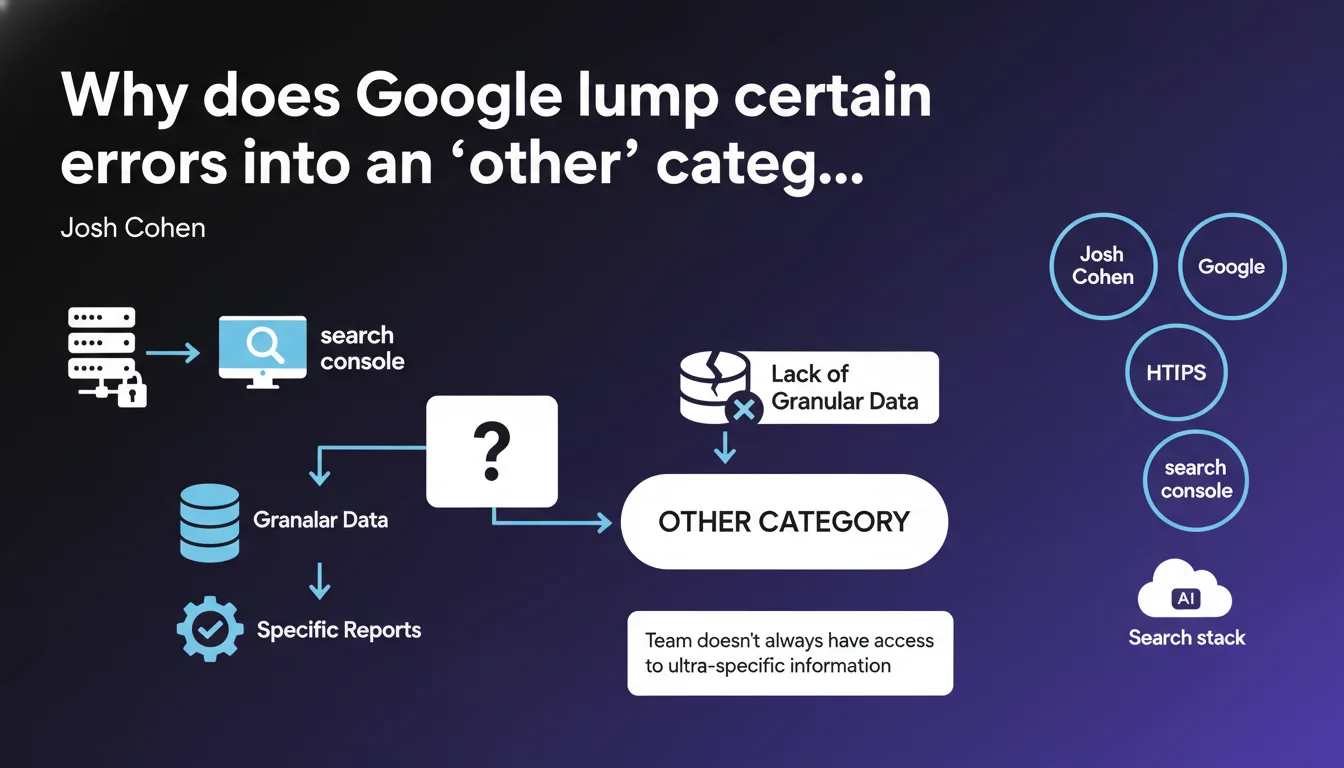
Google openly admits that certain errors grouped under 'other' in reports like the HTTPS one do not result from a willingness to withhold information, but rather from limited access to granular data on its own search stack. The Search Console team simply doesn't always have the precise technical details to finely categorize each error.
What you need to understand
What does this admission from Google really mean?
When you consult Search Console reports, particularly the one dedicated to HTTPS URLs, you regularly come across this famous 'other' category. It brings together unclassified errors, and naturally, we assume Google is deliberately hiding information from us.
Josh Cohen clarifies: it's not trade secret. It's a real lack of granular data. The team in charge of Search Console simply doesn't have access to all the details about the internal layers of Google's search stack.
How is this even possible at a company like Google?
Google's technical structure is compartmentalized. The teams that develop webmaster tools (Search Console, PageSpeed Insights) are not the ones coding the crawl, indexing, or ranking algorithms.
Concretely, when a URL encounters an obscure technical problem — say an error related to a particular protocol layer — the Search Console team may receive an error signal without precise diagnosis. Hence the grouping under 'other'.
What are the consequences for SEO practitioners?
- Some errors will remain opaque, even when contacting Google support
- Diagnosis must be done server-side, via raw logs, not solely through Search Console
- The 'other' category is not a wildcard to ignore the problem — it signals a real anomaly
- Third-party monitoring tools can sometimes provide more detail than Google itself
SEO Expert opinion
Is this statement consistent with field observations?
Yes, and it's actually reassuring. For years, we've suspected Google of deliberate information retention. Cohen lifts the veil: it's not always bad faith, sometimes it's internal technical ignorance.
In the field, this fragmentation checks out. When you compare Search Console data with server logs analyzed via a tool like OnCrawl or Screaming Frog Log Analyzer, the gaps can be brutal. Google doesn't see everything — or at least, its external teams don't see everything its robots capture.
Should we take this explanation at face value?
Let's be honest: [To verify] in some cases, the 'other' category could also serve as a smokescreen for errors that Google prefers not to detail publicly. But the internal compartmentalization problem is documented.
What's stuck — and Cohen doesn't say it — is that this opacity penalizes sites trying to fix errors. You end up fumbling, cross-referencing multiple data sources, when simple access to raw HTTP error codes would resolve 80% of cases.
In which cases does this rule not apply?
Some Search Console reports are extremely precise — the one on Core Web Vitals, for example, or the one on index coverage errors. There, Google provides surgical detail.
The difference? These reports rely on standardized metrics (Lighthouse for CWV) or direct indexing signals. As soon as you touch obscure protocol layers (HTTPS, certificates, complex redirects), things get murky.
Practical impact and recommendations
What should you concretely do when facing an error classified as 'other'?
First, don't panic — but don't ignore it either. This category signals a real problem, even if Google can't name it precisely.
Step 1: cross-reference the data. Compare the URLs in question in Search Console with your server logs. Look for patterns: HTTP error codes, Googlebot user-agents, request timing. Often, the problem jumps out on the server side while remaining opaque on the Search Console side.
- Export URLs classified as 'other' from Search Console
- Analyze server logs for these specific URLs
- Check SSL certificates, redirect chains, security headers
- Manually test crawling with Screaming Frog or Oncrawl
- Document each anomaly to build a history
What errors should you avoid in this context?
The most common mistake: assuming 'other' = negligible. That's wrong. A URL blocked under this category could be a strategic page that isn't indexing.
Second mistake: waiting for Google to clarify. It won't — or not for several months. The diagnosis must come from your side, by cross-referencing multiple sources: Search Console, logs, third-party tools, manual tests.
How do you effectively monitor these opaque errors?
Set up a continuous monitoring system for your server logs. Tools like Splunk, ELK Stack, or even Google BigQuery (for large sites) allow you to identify crawl anomalies in real time.
Automate alerts on non-standard HTTP codes (4xx, 5xx) for Googlebot user-agents. If a critical URL falls into 'other', you'll be notified before it impacts your traffic.
❓ Frequently Asked Questions
Pourquoi Google ne peut-il pas toujours fournir des détails sur les erreurs ?
Que faire si mes URLs sont classées en 'autre' dans le rapport HTTPS ?
Cette opacité peut-elle pénaliser mon référencement ?
Les outils tiers peuvent-ils compenser ce manque de données Google ?
Faut-il contacter le support Google pour ces erreurs 'autre' ?
🎥 From the same video 4
Other SEO insights extracted from this same Google Search Central video · published on 12/01/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.