Declaration officielle
Autres déclarations de cette vidéo 4 ▾
- □ Les titres de page sont-ils vraiment le levier SEO prioritaire que Google prétend ?
- □ Faut-il abandonner les accordéons FAQ pour éviter de pénaliser son SEO ?
- □ L'algorithme Google reconnaît-il vraiment le contenu faisant autorité aussi facilement qu'annoncé ?
- □ Pourquoi Google bride-t-il les centres d'aide au niveau SEO technique ?
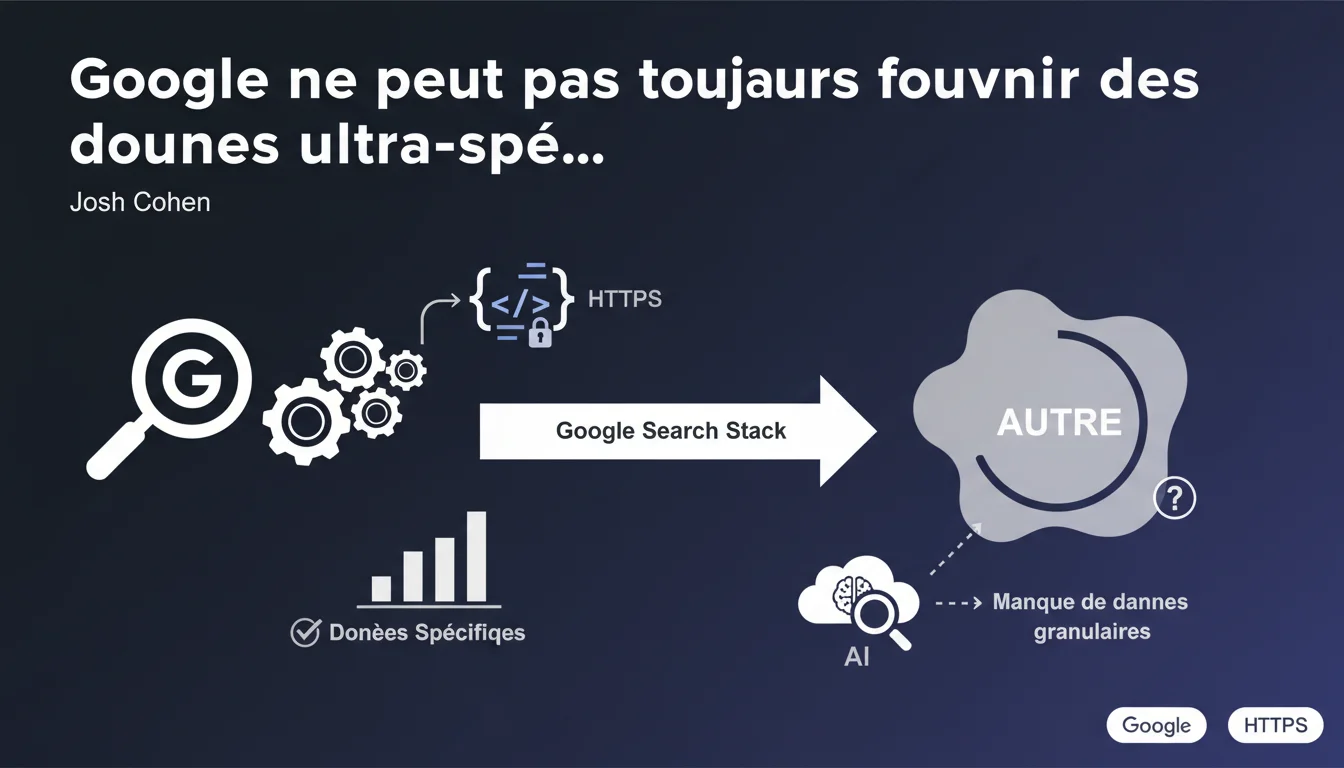
Google admet ouvertement que certaines erreurs regroupées sous 'autre' dans des rapports comme celui sur HTTPS ne résultent pas d'une volonté de rétention d'information, mais d'un accès limité aux données granulaires sur sa propre pile de recherche. L'équipe Search Console ne dispose tout simplement pas toujours des détails techniques précis pour catégoriser finement chaque erreur.
Ce qu'il faut comprendre
Que signifie vraiment cette admission de Google ?
Lorsqu'on consulte les rapports de la Search Console, notamment celui dédié aux URLs HTTPS, on tombe régulièrement sur cette fameuse catégorie 'autre'. Elle rassemble des erreurs non classées, et naturellement, on suppose que Google nous cache volontairement des informations.
Josh Cohen clarifie : ce n'est pas du secret industriel. C'est un manque réel de données granulaires. L'équipe en charge de la Search Console n'a tout simplement pas accès à tous les détails sur les couches internes de la pile de recherche Google.
Comment est-ce possible dans une entreprise comme Google ?
La structure technique de Google est compartimentée. Les équipes qui développent les outils pour webmasters (Search Console, PageSpeed Insights) ne sont pas celles qui codent les algorithmes de crawl, d'indexation ou de ranking.
Concrètement, quand une URL rencontre un problème technique obscur — disons une erreur liée à une couche de protocole particulière — l'équipe Search Console peut recevoir un signal d'erreur sans diagnostic précis. D'où le regroupement sous 'autre'.
Quelles sont les conséquences pour les praticiens SEO ?
- Certaines erreurs resteront opaques, même en contactant le support Google
- Le diagnostic doit se faire côté serveur, via les logs bruts, pas uniquement via la Search Console
- La catégorie 'autre' n'est pas un joker pour ignorer le problème — elle signale une anomalie réelle
- Les outils tiers de monitoring peuvent parfois fournir plus de détails que Google lui-même
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même rassurant. Depuis des années, on suspecte Google de rétention volontaire d'informations. Cohen lève le voile : ce n'est pas toujours de la mauvaise foi, c'est parfois de l'ignorance technique interne.
Sur le terrain, cette fragmentation se vérifie. Quand on compare les données de la Search Console avec les logs serveur analysés via un outil comme OnCrawl ou Screaming Frog Log Analyzer, les écarts sont parfois brutaux. Google ne voit pas tout — ou du moins, ses équipes externes ne voient pas tout ce que ses robots captent.
Faut-il prendre cette explication au pied de la lettre ?
Soyons honnêtes : [A vérifier] dans certains cas, la catégorie 'autre' pourrait aussi servir de cache-misère pour des erreurs que Google préfère ne pas détailler publiquement. Mais le problème de compartimentage interne est documenté.
Ce qui coince — et Cohen ne le dit pas — c'est que cette opacité pénalise les sites qui cherchent à corriger des erreurs. On se retrouve à tâtonner, à croiser plusieurs sources de données, alors qu'un simple accès aux codes d'erreur HTTP bruts résoudrait 80% des cas.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Certains rapports de la Search Console sont extrêmement précis — celui sur les Core Web Vitals, par exemple, ou celui sur les erreurs de couverture d'index. Là, Google fournit des détails chirurgicaux.
La différence ? Ces rapports s'appuient sur des métriques standardisées (Lighthouse pour les CWV) ou des signaux d'indexation directs. Dès qu'on touche à des couches protocolaires obscures (HTTPS, certificats, redirections complexes), le flou s'installe.
Impact pratique et recommandations
Que faut-il faire concrètement face à une erreur classée 'autre' ?
D'abord, ne pas paniquer — mais ne pas ignorer non plus. Cette catégorie signale un problème réel, même si Google ne peut pas le nommer précisément.
Étape 1 : croiser les données. Compare les URLs concernées dans la Search Console avec tes logs serveur. Cherche des patterns : codes d'erreur HTTP, user-agents Googlebot, timing des requêtes. Souvent, le problème saute aux yeux côté serveur alors qu'il reste opaque côté Search Console.
- Exporter les URLs classées 'autre' depuis la Search Console
- Analyser les logs serveur pour ces URLs spécifiques
- Vérifier les certificats SSL, les chaînes de redirection, les en-têtes de sécurité
- Tester manuellement le crawl avec Screaming Frog ou Oncrawl
- Documenter chaque anomalie pour construire un historique
Quelles erreurs éviter dans ce contexte ?
L'erreur la plus fréquente : supposer que 'autre' = négligeable. C'est faux. Une URL bloquée sous cette catégorie peut être une page stratégique qui ne s'indexe pas.
Deuxième erreur : attendre que Google précise. Il ne le fera pas — ou pas avant plusieurs mois. Le diagnostic doit venir de ton côté, en croisant plusieurs sources : Search Console, logs, outils tiers, tests manuels.
Comment monitorer efficacement ces erreurs opaques ?
Mets en place un système de monitoring continu des logs serveur. Les outils comme Splunk, ELK Stack ou même Google BigQuery (pour les gros sites) permettent d'identifier en temps réel les anomalies de crawl.
Automatise des alertes sur les codes HTTP non standards (4xx, 5xx) pour les user-agents Googlebot. Si une URL critique passe en 'autre', tu seras prévenu avant que ça impacte ton trafic.
❓ Questions frequentes
Pourquoi Google ne peut-il pas toujours fournir des détails sur les erreurs ?
Que faire si mes URLs sont classées en 'autre' dans le rapport HTTPS ?
Cette opacité peut-elle pénaliser mon référencement ?
Les outils tiers peuvent-ils compenser ce manque de données Google ?
Faut-il contacter le support Google pour ces erreurs 'autre' ?
🎥 De la même vidéo 4
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/01/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.