Official statement
Other statements from this video 2 ▾
Google confirms that noindex and robots.txt are two valid approaches to exclude tracking URLs, but each has its limitations. The choice depends on your site architecture, crawl budget, and indexation priorities. No method is universally superior — what matters is understanding their respective impacts.
What you need to understand
Why does this distinction between noindex and robots.txt matter so much for your site?
URLs with tracking parameters (utm_source, fbclid, etc.) can explode the number of crawled pages without providing any SEO value. Google must then choose between crawling thousands of useless variants or focusing on your actual content.
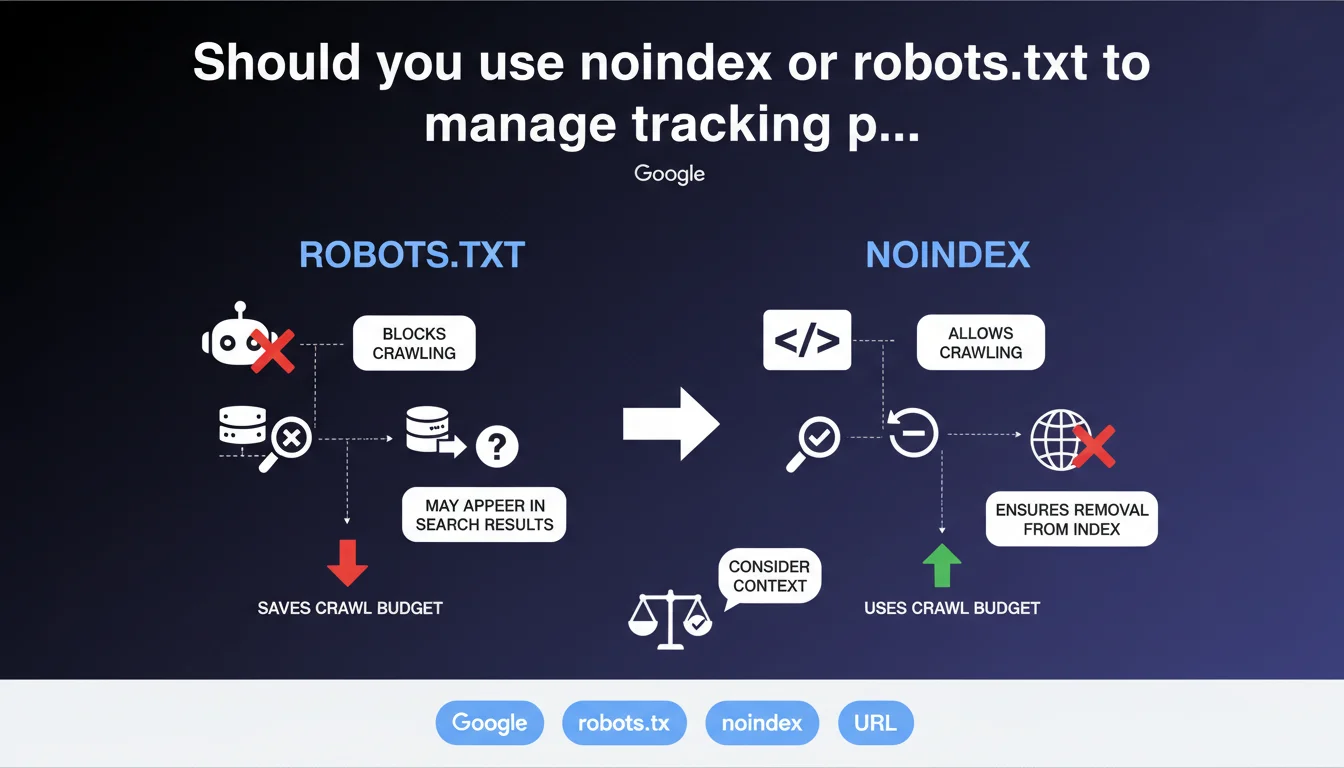
The meta noindex tag allows Googlebot to crawl the page, see the directive, and then skip indexation. The robots.txt file, on the other hand, blocks crawl access entirely. Two completely different philosophies.
What are the real pros and cons of each approach?
With noindex, Googlebot must still crawl each variant to read the directive. This consumes crawl budget, but ensures Google sees the instruction clearly. Backlinks to these URLs pass little to no link juice.
With robots.txt, crawl is blocked upstream — saving server resources and crawl budget. But beware: if external links point to these blocked URLs, Google cannot see that they are duplicates. It might even index the URL without content if it has enough backlinks.
- Noindex: consumes crawl, but clear instruction for Google
- Robots.txt: saves crawl, but risks blind indexation if external backlinks exist
- Context wins: volume of variants, backlink quality, site architecture
When should you prioritize one method over the other?
If your tracking URLs receive many external backlinks (viral campaigns, massive social shares), noindex is safer. Google will see these are variants to ignore, with no risk of orphaned indexation.
If you have a tight crawl budget and thousands of internally generated variants (facets, filters), robots.txt can be more efficient — provided you have no external links pointing to them.
SEO Expert opinion
Is this guidance actually consistent with what we observe in the real world?
Yes, but it remains deliberately vague on one critical point: what happens when a URL blocked by robots.txt receives quality backlinks? Google says it "could" be indexed without content. In practice, we observe that this is common, especially if the domain has authority.
The other issue is that Google never specifies how much crawl budget is actually saved with robots.txt versus noindex. [To verify]: on a site with 10,000 tracking variants, is the crawl budget impact significant or marginal? Google provides no figures, no thresholds. We're flying blind.
What important nuances should you add to this recommendation?
First point: canonical tags don't solve everything. Many SEOs think a canonical tag alone is enough to manage tracking parameters. But if Google crawls all variants anyway to read the canonical, crawl budget explodes just the same. Canonical plus noindex is often more robust.
Second point: Search Console lets you declare parameters to ignore (the old "URL Parameters" feature). This option is underused, yet it can clarify intentions without touching code. But Google has degraded this tool in recent years — yet another gray area.
Are there situations where this rule doesn't apply?
If your tracking parameters change the page's content (sorting, language, currency), they're no longer simple parameters to exclude — they're legitimate variants. Neither noindex nor robots.txt are appropriate here. You need well-thought canonicals, or even hreflang if multilingual.
Another case: very large sites (e-commerce, marketplaces) where variant volume exceeds one million. robots.txt becomes unmanageable, noindex overloads crawl. You must then redesign: disable parameters server-side, use JavaScript for tracking without modifying the URL, or implement 302 redirects to the clean version.
Practical impact and recommendations
What should you actually do right now to manage tracking URLs?
First step: audit your indexed URLs in Search Console. Filter by parameters (utm_, fbclid, gclid) and check how many variants are indexed. If the number exceeds a few dozen, you have a crawl budget problem.
Next, choose your method based on context: noindex if you have external backlinks on these URLs, robots.txt if it's purely internal traffic. When in doubt, start with noindex — it's reversible and has no risk of blind indexation.
- Identify all URLs with tracking parameters (Search Console, server logs)
- Verify if these URLs receive external backlinks (Ahrefs, Majestic)
- If backlinks exist: implement meta noindex via dynamic template
- If zero backlinks: block via robots.txt with Disallow: /*?utm_
- Test on a sample before massive rollout
- Monitor indexation for 4-6 weeks after implementation
What mistakes must you absolutely avoid?
Never block via robots.txt URLs already indexed without first verifying they have no backlinks. You risk leaving them indexed indefinitely with no way to act. Deindex first with noindex, then block if needed.
Another trap: using robots.txt AND noindex simultaneously. Google cannot crawl to see the noindex — robots.txt takes precedence. Choose one or the other, never both on the same URL.
How do you verify your implementation is correct?
Use Search Console's URL inspection tool to test a tracking URL. If you've set noindex, Google should display "Page excluded by noindex tag". If you've blocked via robots.txt, the tool should indicate "Blocked by robots.txt".
Then monitor the evolution of indexed pages in your coverage report. A gradual decline is normal when deindexing variants. A sudden spike signals a problem (uncovered parameters, misconfigured rules).
❓ Frequently Asked Questions
Peut-on utiliser noindex et robots.txt en même temps sur une URL ?
Le canonical suffit-il à gérer les paramètres de tracking ?
Que se passe-t-il si une URL bloquée par robots.txt reçoit des backlinks ?
Comment bloquer tous les paramètres utm en une seule règle robots.txt ?
Faut-il désindexer avant de bloquer par robots.txt ?
🎥 From the same video 2
Other SEO insights extracted from this same Google Search Central video · published on 25/07/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.