Declaration officielle
Autres déclarations de cette vidéo 2 ▾
Google confirme que noindex et robots.txt sont deux approches valables pour exclure les URLs de tracking, mais chacune a ses limites. Le choix dépend de votre architecture, de votre crawl budget et de vos priorités d'indexation. Aucune méthode n'est universellement supérieure — l'important est de comprendre leurs impacts respectifs.
Ce qu'il faut comprendre
Pourquoi cette distinction entre noindex et robots.txt est-elle importante ?
Les URLs avec paramètres de tracking (utm_source, fbclid, etc.) peuvent exploser le nombre de pages crawlées sans apporter aucune valeur SEO. Google doit alors choisir entre crawler des milliers de variantes inutiles ou se concentrer sur votre contenu réel.
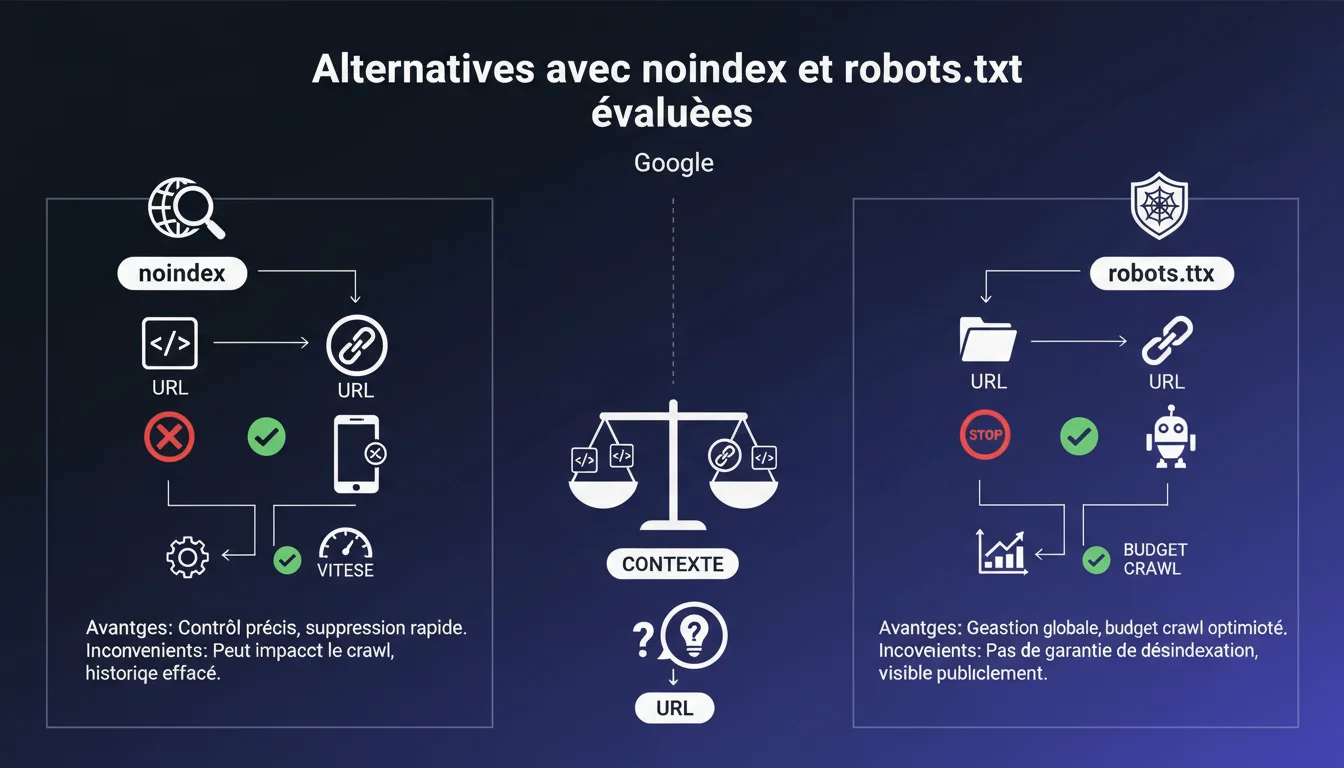
La balise meta noindex permet à Googlebot de crawler la page, de voir la directive, puis de ne pas l'indexer. Le fichier robots.txt, lui, bloque carrément l'accès au crawl. Deux philosophies radicalement différentes.
Quels sont les avantages et inconvénients de chaque méthode ?
Avec noindex, Googlebot doit quand même crawler chaque variante pour lire la directive. Cela consomme du crawl budget, mais garantit que Google voit bien l'instruction. Les backlinks vers ces URLs ne transmettent pas de jus (ou très peu).
Avec robots.txt, le crawl est bloqué en amont — économie de ressources serveur et de crawl budget. Mais attention : si des liens externes pointent vers ces URLs bloquées, Google ne peut pas voir qu'elles sont des doublons. Il pourrait même indexer l'URL sans contenu si elle a assez de backlinks.
- Noindex : consomme du crawl, mais instruction claire pour Google
- Robots.txt : économise du crawl, mais risque d'indexation aveugle si backlinks externes
- Le contexte prime : volume de variantes, qualité des backlinks, architecture du site
Dans quels cas privilégier l'une ou l'autre ?
Si vos URLs de tracking reçoivent beaucoup de backlinks externes (campagnes virales, partages sociaux massifs), noindex est plus sûr. Google verra que ce sont des variantes à ignorer, sans risque d'indexation orpheline.
Si vous avez un crawl budget serré et des milliers de variantes générées en interne (facettes, filtres), robots.txt peut être plus efficace — à condition de ne pas avoir de liens externes pointant dessus.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, mais elle reste volontairement vague sur un point crucial : que se passe-t-il quand une URL bloquée par robots.txt reçoit des backlinks de qualité ? Google dit qu'elle « pourrait » être indexée sans contenu. Dans les faits, on observe que c'est fréquent, surtout si le domaine a de l'autorité.
L'autre problème, c'est que Google ne dit pas combien de crawl budget est réellement économisé avec robots.txt vs noindex. [À vérifier] : sur un site avec 10 000 variantes de tracking, l'impact sur le crawl budget est-il significatif ou marginal ? Google ne donne aucun chiffre, aucun seuil. On navigue à vue.
Quelles nuances faut-il apporter à cette recommandation ?
Premier point : canonical ne résout pas tout. Beaucoup de SEO pensent qu'une balise canonical suffit pour gérer les paramètres de tracking. Mais si Google crawle quand même toutes les variantes pour lire le canonical, le crawl budget explose pareil. Canonical + noindex est souvent plus robuste.
Deuxième point : la Search Console permet de déclarer des paramètres à ignorer (anciennes « URL Parameters »). Cette option est sous-utilisée, alors qu'elle peut clarifier les intentions sans toucher au code. Mais Google a dégradé cet outil ces dernières années — encore une zone floue.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vos paramètres de tracking changent le contenu de la page (tri, langue, devise), ce ne sont plus de simples paramètres à exclure — ce sont des variantes légitimes. Là, ni noindex ni robots.txt ne sont appropriés. Il faut des canonicals bien pensées, voire du hreflang si c'est multilingue.
Autre cas : les sites de très grande taille (e-commerce, marketplaces) où le volume de variantes dépasse le million. Robots.txt devient ingérable, noindex surcharge le crawl. Il faut alors revoir l'architecture : désactiver les paramètres côté serveur, utiliser du JavaScript pour le tracking sans modifier l'URL, ou passer par un système de redirections 302 vers la version propre.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer les URLs de tracking ?
Première étape : auditer vos URLs indexées dans la Search Console. Filtrez par paramètres (utm_, fbclid, gclid) et vérifiez combien de variantes sont indexées. Si le nombre dépasse quelques dizaines, vous avez un problème de crawl budget.
Ensuite, choisissez votre méthode selon le contexte : noindex si vous avez des backlinks externes sur ces URLs, robots.txt si c'est du trafic purement interne. Dans le doute, commencez par noindex — c'est réversible et sans risque d'indexation aveugle.
- Identifier toutes les URLs avec paramètres de tracking (Search Console, logs serveur)
- Vérifier si ces URLs reçoivent des backlinks externes (Ahrefs, Majestic)
- Si backlinks : implémenter meta noindex via template dynamique
- Si zéro backlink : bloquer via robots.txt avec Disallow: /*?utm_
- Tester sur un échantillon avant déploiement massif
- Surveiller l'indexation pendant 4-6 semaines post-implémentation
Quelles erreurs éviter absolument ?
Ne jamais bloquer par robots.txt des URLs déjà indexées sans avoir d'abord vérifié qu'elles n'ont pas de backlinks. Vous risquez de les laisser indexées indéfiniment, sans pouvoir agir. Désindexez d'abord avec noindex, puis bloquez si nécessaire.
Autre piège : utiliser robots.txt ET noindex simultanément. Google ne pourra pas crawler pour voir le noindex — le robots.txt prend le dessus. Choisissez l'un ou l'autre, jamais les deux sur la même URL.
Comment vérifier que la mise en œuvre est correcte ?
Utilisez l'outil d'inspection d'URL de la Search Console pour tester une URL de tracking. Si vous avez mis noindex, Google doit afficher « Page exclue par la balise noindex ». Si vous avez bloqué par robots.txt, l'outil doit indiquer « Bloqué par robots.txt ».
Surveillez ensuite l'évolution du nombre de pages indexées dans le rapport de couverture. Une baisse progressive est normale si vous désindexez des variantes. Une hausse soudaine signale un problème (paramètres non couverts, règles mal appliquées).
❓ Questions frequentes
Peut-on utiliser noindex et robots.txt en même temps sur une URL ?
Le canonical suffit-il à gérer les paramètres de tracking ?
Que se passe-t-il si une URL bloquée par robots.txt reçoit des backlinks ?
Comment bloquer tous les paramètres utm en une seule règle robots.txt ?
Faut-il désindexer avant de bloquer par robots.txt ?
🎥 De la même vidéo 2
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 25/07/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.