Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Google crawle-t-il vraiment le HTML rendu ou seulement le code source ?
- □ Le DOM dynamique modifié par JavaScript est-il vraiment pris en compte par Google ?
- □ Pourquoi Google indexe-t-il le HTML rendu plutôt que le HTML source ?
- □ Faut-il vraiment abandonner l'inspection de code source au profit de Search Console pour voir ce que Google indexe ?
- □ Pourquoi le processus de rendu est-il crucial pour le référencement de vos pages ?
- □ Pourquoi l'onglet Elements de Chrome révèle-t-il plus que le code source pour le SEO ?
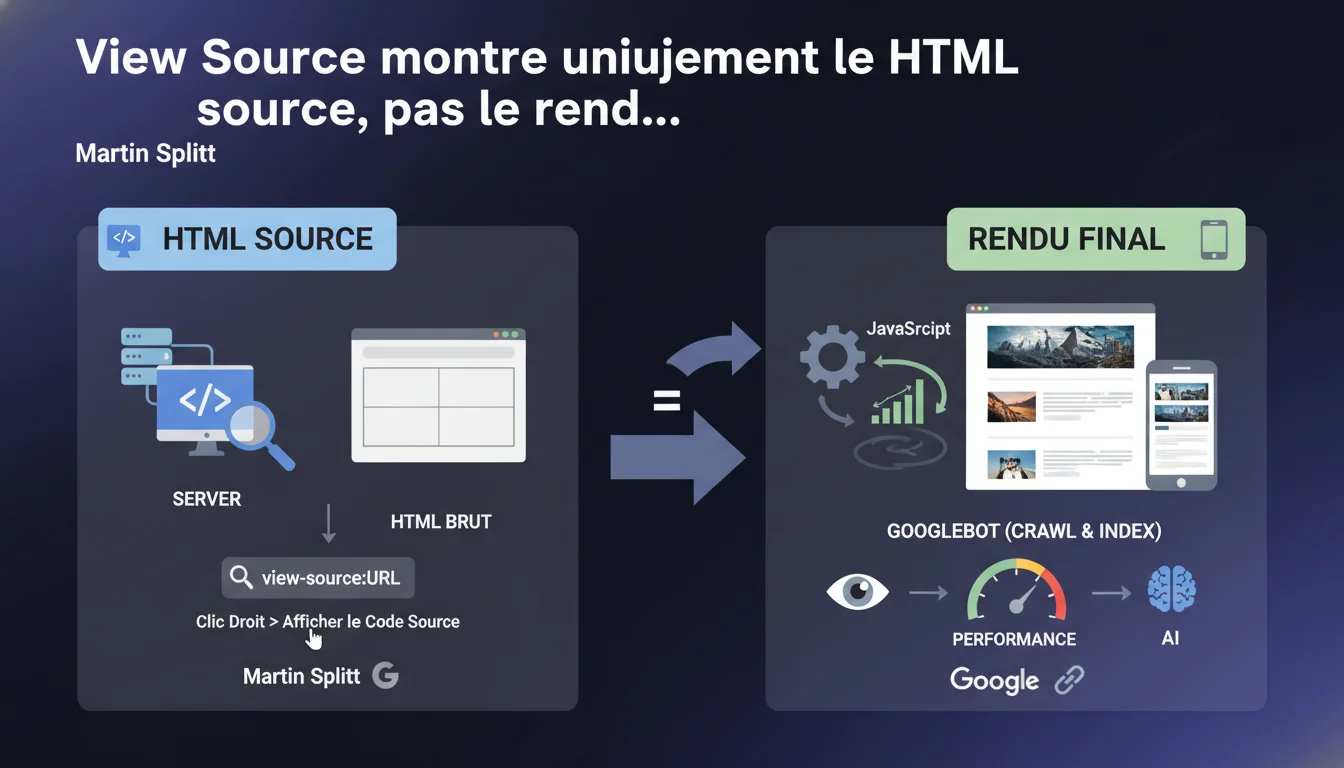
Le HTML brut affiché via « Afficher le code source » ou « view-source: » ne correspond pas au DOM final que Google indexe. Tout contenu injecté par JavaScript après le chargement initial échappe à cette visualisation. Pour diagnostiquer ce que Googlebot voit réellement, il faut se baser sur des outils comme l'outil d'inspection d'URL de la Search Console ou des tests de rendu complets.
Ce qu'il faut comprendre
Quelle différence entre le HTML source et le DOM rendu ?
Le HTML source correspond à la réponse brute envoyée par le serveur au moment de la requête initiale. C'est un instantané figé du code avant toute exécution JavaScript côté client.
Le DOM rendu, lui, est le résultat de toutes les transformations appliquées par le navigateur : exécution de scripts, manipulation du DOM, chargement asynchrone de contenu. C'est cet état final que Google analyse lors de l'indexation, notamment pour les sites JavaScript-heavy (React, Vue, Angular).
Pourquoi cette distinction pose problème en SEO ?
Beaucoup de praticiens se fient encore au « view-source » pour vérifier la présence de balises critiques : title, meta description, balises Hn, contenu textuel. Si ces éléments sont injectés dynamiquement par JavaScript, ils n'apparaissent pas dans le code source — mais Google peut très bien les voir et les indexer.
Inversement, un contenu visible dans le source mais masqué par JavaScript (display:none appliqué après chargement) peut être ignoré ou dévalué par Google. Le décalage entre ces deux visions du site crée des angles morts dans les audits SEO classiques.
Comment Google gère-t-il le rendu JavaScript ?
Googlebot utilise un moteur de rendu basé sur Chromium (anciennement sur une version de Chrome). Il exécute JavaScript, attend que le DOM soit stabilisé, puis indexe le résultat final. Ce processus introduit un délai — la « wave d'indexation » — qui peut retarder la prise en compte de contenus JS par rapport au HTML statique.
Le problème : tous les scripts ne sont pas exécutés de manière fiable. Erreurs JS, timeouts, ressources bloquées par robots.txt, dépendances manquantes… autant de pièges qui peuvent faire échouer le rendu.
- Le HTML source est ce que le serveur envoie immédiatement.
- Le DOM rendu est le résultat après exécution complète du JavaScript.
- Google indexe le DOM rendu, pas le HTML source brut.
- « View-source » ne suffit plus pour diagnostiquer l'indexabilité réelle d'un site moderne.
- Les erreurs JavaScript peuvent empêcher Google de voir des contenus pourtant visibles pour l'utilisateur.
Avis d'un expert SEO
Cette déclaration reflète-t-elle la réalité terrain ?
Oui, mais avec des nuances importantes. Google indexe bien le DOM rendu, mais la qualité du rendu varie selon la complexité du site et les ressources allouées au crawl. Sur des sites e-commerce massifs ou des plateformes SaaS, on observe régulièrement des disparités entre ce que l'outil d'inspection montre et ce qui est effectivement indexé.
Un cas fréquent : un produit affiché correctement dans l'outil d'inspection mais jamais indexé en production, souvent à cause de quotas de rendu ou de timeouts côté Googlebot. [A vérifier] : Google ne communique pas publiquement de limites précises sur le temps alloué au rendu JS par page, ce qui rend le diagnostic empirique.
Quelles erreurs cette méconnaissance provoque-t-elle ?
Beaucoup d'audits SEO passent encore à côté de problèmes critiques parce qu'ils s'appuient sur des crawlers qui ne rendent pas JavaScript — ou mal. Résultat : des recommandations erronées (« ajoutez un title dans le HTML » alors qu'il est injecté en JS et fonctionne) ou, pire, des contenus invisibles ignorés.
Autre piège classique : valider l'indexation d'une page via « view-source » alors que le contenu critique dépend d'un appel API asynchrone qui échoue régulièrement côté Googlebot. Le site fonctionne en apparence, mais Google indexe des coquilles vides.
Faut-il abandonner le HTML statique pour autant ?
Non. Soyons honnêtes : le HTML statique reste l'approche la plus fiable pour garantir une indexation rapide et prévisible. Quand c'est possible, injecter directement les contenus critiques côté serveur (SSR, pre-rendering) élimine toute dépendance au rendu JS et aux aléas associés.
Le JavaScript n'est pas un problème en soi — Google le gère plutôt bien en 2025. Mais il introduit une couche de complexité et des points de défaillance potentiels qu'on peut éviter en revenant à du SSR ou du static site generation (SSG) là où c'est pertinent.
Impact pratique et recommandations
Comment vérifier ce que Google voit réellement ?
Oublie « view-source ». Utilise l'outil d'inspection d'URL dans la Google Search Console. Il simule le rendu complet de Googlebot et affiche le DOM final, captures d'écran incluses. C'est la référence absolue pour diagnostiquer un problème d'indexation lié au JavaScript.
Complète avec des outils tiers capables de rendre JS : Screaming Frog en mode JavaScript, OnCrawl, Botify… Attention toutefois : leur moteur de rendu n'est jamais strictement identique à celui de Google. En cas de doute, la Search Console fait foi.
Quelles erreurs éviter lors de l'audit ?
Ne jamais se fier uniquement à un crawl sans JS pour valider l'indexabilité d'un site moderne. C'est le meilleur moyen de passer à côté de contenus critiques ou, à l'inverse, de recommander des corrections inutiles.
Autre erreur fréquente : tester l'indexation sur un environnement de dev où le JS fonctionne parfaitement, sans vérifier que les mêmes ressources (CDN, API, fichiers JS tiers) sont accessibles à Googlebot en production. Résultat : discordance totale entre ce que vous voyez et ce que Google indexe.
- Utilise l'outil d'inspection d'URL de la Search Console pour voir le DOM rendu par Google.
- Compare le HTML source (view-source) et le DOM final (DevTools > Elements) pour identifier les contenus injectés en JS.
- Vérifie que toutes les ressources JS critiques sont accessibles (pas bloquées par robots.txt ou des en-têtes CORS).
- Teste le rendu avec un crawler JS (Screaming Frog, OnCrawl) en complément de la Search Console.
- Surveille les erreurs JavaScript dans la Search Console (onglet « Couverture » > « Exclues »).
- Pour les sites e-commerce ou à fort trafic, privilégie le SSR ou le pre-rendering sur les pages stratégiques (catégories, fiches produits).
- En cas d'écart persistant entre le rendu attendu et l'indexation réelle, audite les timeouts, quotas de crawl et ressources bloquées.
❓ Questions frequentes
Est-ce que Google indexe toujours le contenu injecté par JavaScript ?
L'outil d'inspection d'URL montre un rendu parfait, mais la page n'est pas indexée. Pourquoi ?
Faut-il bloquer JavaScript dans robots.txt pour forcer Google à indexer le HTML source ?
Le SSR est-il obligatoire pour un site JavaScript ?
Peut-on se fier à Screaming Frog pour vérifier ce que Google indexe ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/07/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.