Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Google crawle-t-il vraiment le HTML rendu ou seulement le code source ?
- □ Pourquoi Google indexe-t-il le HTML rendu plutôt que le HTML source ?
- □ Faut-il vraiment abandonner l'inspection de code source au profit de Search Console pour voir ce que Google indexe ?
- □ Pourquoi « Afficher le code source » ne montre-t-il pas ce que Google indexe vraiment ?
- □ Pourquoi le processus de rendu est-il crucial pour le référencement de vos pages ?
- □ Pourquoi l'onglet Elements de Chrome révèle-t-il plus que le code source pour le SEO ?
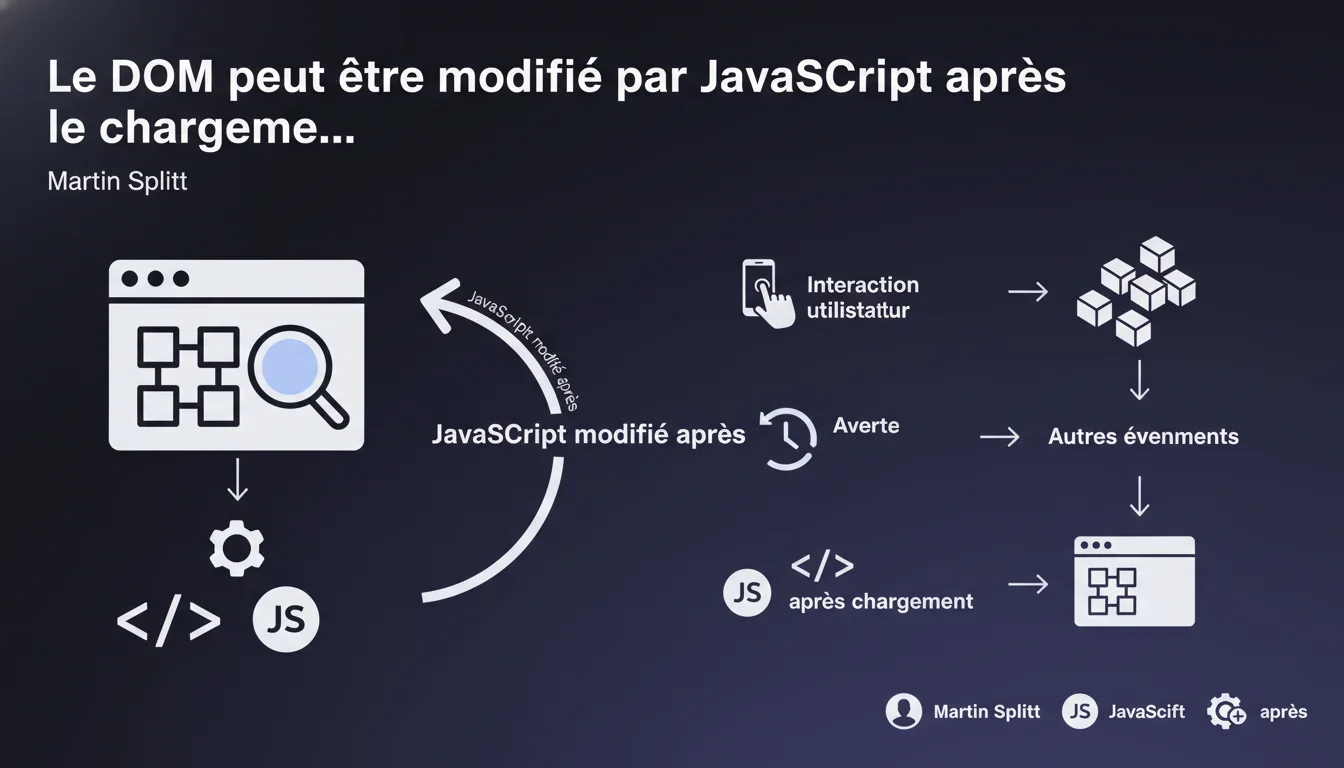
Google reconnaît que le DOM peut changer après le chargement initial via JavaScript. Les modifications ajoutées dynamiquement — contenu, liens, éléments — sont détectées lors du rendering. Mais attention : le timing et la complexité du script influencent directement ce que Google indexe réellement.
Ce qu'il faut comprendre
Qu'est-ce que le DOM et pourquoi Google en parle maintenant ?
Le Document Object Model est la structure arborescente que le navigateur construit à partir du HTML. C'est cette représentation que JavaScript manipule pour ajouter, modifier ou supprimer des éléments.
Quand Martin Splitt précise que le DOM "peut changer", il répond à une inquiétude récurrente des développeurs : est-ce que Google voit le contenu injecté après coup ? La réponse officielle est oui — mais avec des nuances importantes que cette déclaration n'explicite pas.
Quand et comment le DOM est-il modifié ?
Trois moments clés : pendant le chargement (scripts qui s'exécutent avant le rendu complet), lors d'interactions utilisateur (clics, scroll, hover), et lors d'événements déclenchés (timers, websockets, API externes).
Pour Googlebot, seul le premier cas est garanti d'être crawlé. Les deux autres nécessitent que le bot simule l'interaction — ce qu'il ne fait pas systématiquement.
Quels sont les points essentiels à retenir ?
- Google exécute JavaScript et détecte les modifications du DOM après le HTML initial
- Le contenu ajouté dynamiquement peut être indexé, mais ce n'est pas automatique
- Le timing d'exécution du script est critique : trop tard = invisible pour le bot
- Les modifications déclenchées par interaction utilisateur (scroll infini, lazy loading au clic) ne sont pas garanties d'être crawlées
- La complexité technique du JavaScript peut bloquer le rendering complet
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui et non. Google crawle effectivement le DOM après exécution JavaScript — on le vérifie avec des tests d'URL en Search Console ou via le cache. Mais la fiabilité n'est pas de 100%.
Des dizaines de cas réels montrent que certains contenus JS ne sont jamais indexés, même après plusieurs mois. Les raisons ? Budget crawl limité, scripts trop lourds, délais d'exécution trop longs. [À vérifier] : Google n'a jamais donné de seuil clair sur le timeout de rendering ni sur la profondeur d'exécution tolérée.
Quelles nuances faut-il apporter à cette affirmation ?
Splitt reste volontairement vague sur les limites pratiques. Il ne dit pas que tout JavaScript sera exécuté, ni que toutes les modifications seront détectées. Il dit juste que c'est possible.
Concrètement, si ton contenu principal nécessite un scroll infini ou un clic utilisateur pour apparaître, tu joues à la roulette. Google peut le voir, mais rien ne garantit qu'il le fera systématiquement. Les tests montrent une indexation aléatoire dans ces configurations.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Quand le JavaScript est bloqué par robots.txt (cas rare mais encore observé), quand le délai d'exécution dépasse le timeout de Google, ou quand des erreurs JS bloquent le rendering. Le bot n'attend pas indéfiniment.
Autre cas ignoré : les modifications déclenchées par des événements serveur (websockets, Server-Sent Events). Google ne maintient pas de connexion persistante pour attendre ces updates.
Impact pratique et recommandations
Que faut-il faire concrètement pour s'assurer que Google voit le DOM modifié ?
Teste d'abord avec l'outil d'inspection d'URL dans Search Console. Compare le HTML brut (Ctrl+U) et le DOM rendu. Si des éléments critiques manquent dans le rendu Google, ton JS est problématique.
Utilise le rendu côté serveur (SSR) ou la génération statique pour le contenu prioritaire. Réserve le JS dynamique aux éléments secondaires — filtres, animations, fonctionnalités UX.
Quelles erreurs éviter absolument ?
Ne pas confier ton contenu principal uniquement à du JavaScript client-side. Un H1, une meta description, un bloc de texte stratégique doivent être présents dans le HTML initial.
Évite les scripts lourds qui retardent le First Contentful Paint. Google peut abandonner le rendering si ça prend trop longtemps. Surveille les erreurs JS dans la console : une seule erreur critique peut bloquer toute la chaîne d'exécution.
Comment vérifier que mon site est conforme ?
- Compare le HTML source et le DOM rendu dans Search Console (onglet "Tester l'URL en ligne")
- Vérifie que les liens internes importants sont présents dans le DOM rendu par Google
- Contrôle les Core Web Vitals : un LCP retardé = rendering Google potentiellement incomplet
- Utilise un crawler JavaScript (Screaming Frog, OnCrawl) pour simuler le comportement de Googlebot
- Analyse les logs serveurs : si Google crawle peu tes ressources JS, c'est mauvais signe
- Teste en désactivant JavaScript dans le navigateur : le contenu critique doit rester accessible
❓ Questions frequentes
Google indexe-t-il le contenu ajouté par JavaScript après le chargement initial ?
Les modifications du DOM déclenchées par interaction utilisateur sont-elles crawlées ?
Comment vérifier que Google voit mon contenu JavaScript ?
Faut-il abandonner le JavaScript pour le SEO ?
Quel est le délai maximum que Google tolère pour l'exécution JavaScript ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/07/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.