Declaration officielle
Autres déclarations de cette vidéo 6 ▾
- □ Google crawle-t-il vraiment le HTML rendu ou seulement le code source ?
- □ Le DOM dynamique modifié par JavaScript est-il vraiment pris en compte par Google ?
- □ Faut-il vraiment abandonner l'inspection de code source au profit de Search Console pour voir ce que Google indexe ?
- □ Pourquoi « Afficher le code source » ne montre-t-il pas ce que Google indexe vraiment ?
- □ Pourquoi le processus de rendu est-il crucial pour le référencement de vos pages ?
- □ Pourquoi l'onglet Elements de Chrome révèle-t-il plus que le code source pour le SEO ?
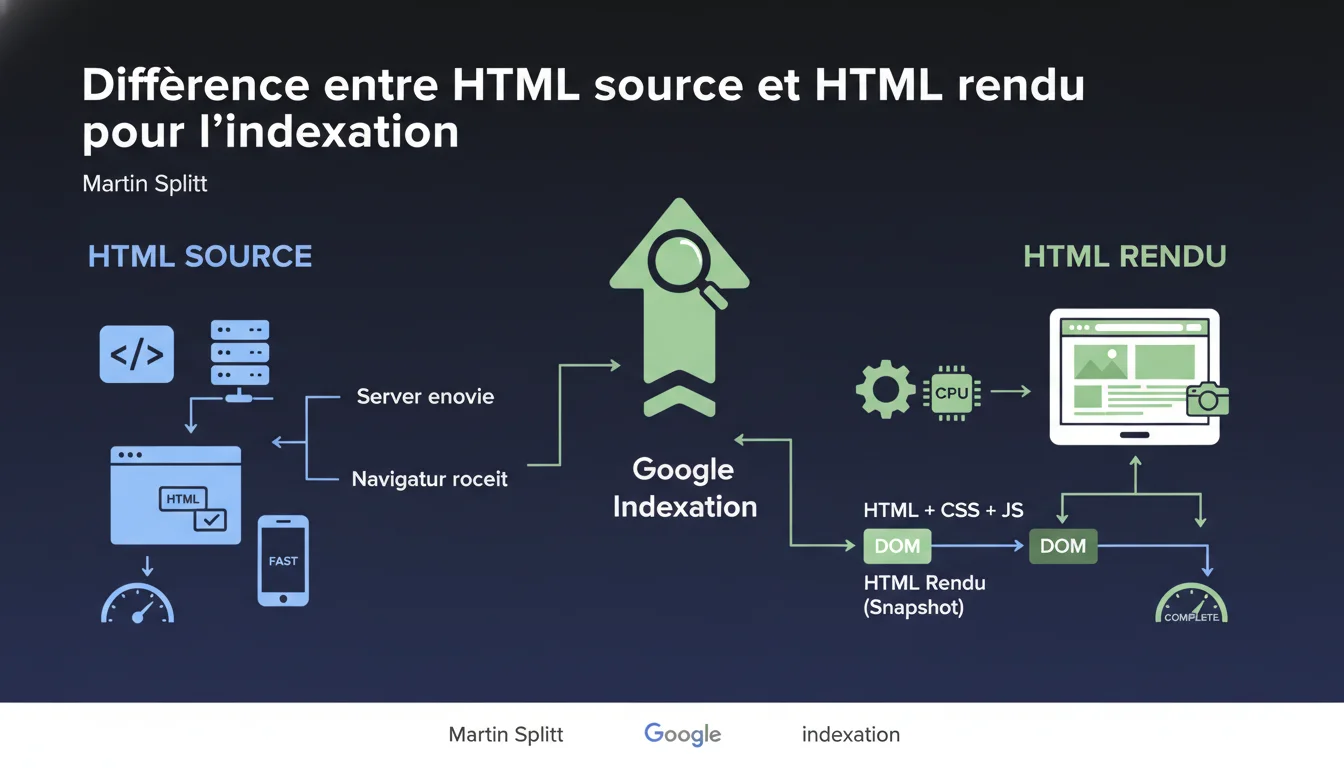
Google indexe l'HTML rendu (le DOM transformé en HTML), pas l'HTML source (ce que le serveur envoie initialement). Cette distinction technique a des conséquences majeures pour tout site utilisant JavaScript pour afficher du contenu. Si ton contenu s'affiche côté client, il faut impérativement vérifier que Googlebot le voit dans le rendu final.
Ce qu'il faut comprendre
Quelle est la différence concrète entre HTML source et HTML rendu ?
L'HTML source correspond au code brut renvoyé par ton serveur lorsqu'un navigateur (ou un bot) effectue une requête. C'est ce que tu vois dans "Afficher la source de la page" de ton navigateur.
L'HTML rendu, c'est l'instantané du DOM après que le JavaScript ait fait son travail : manipulation du contenu, chargement asynchrone, modifications dynamiques. Google prend cet instantané à un moment T — et c'est ça qu'il indexe.
Pourquoi cette distinction pose-t-elle problème en SEO ?
Parce que beaucoup de sites modernes (React, Vue, Angular, Next.js mal configurés) envoient un HTML source quasi vide et construisent tout le contenu côté client. Si ton serveur renvoie un <div id="root"></div> et que le JS se charge du reste, Googlebot doit exécuter ce JavaScript pour voir ton contenu.
Le problème ? L'exécution JavaScript n'est pas instantanée, elle est coûteuse en ressources, et Google ne garantit pas de tout voir si ton JS est lent ou buggé. Entre l'HTML source et l'HTML rendu, il peut y avoir un écart énorme — et c'est cet écart qui tue ton indexation.
Comment Google capture-t-il cet instantané rendu ?
Google utilise un navigateur headless (Chrome) pour exécuter ton JavaScript et générer le rendu. Mais attention : cet instantané est pris à un moment précis, après un délai donné. Si ton contenu se charge tardivement (lazy loading agressif, appels API lents), il peut ne jamais apparaître dans l'instantané indexé.
- HTML source = ce que ton serveur envoie initialement, sans exécution JS
- HTML rendu = instantané du DOM transformé en HTML après exécution du JavaScript
- Google indexe le HTML rendu, pas le source — donc le contenu invisible dans le rendu est invisible pour Google
- L'exécution JavaScript par Googlebot n'est pas garantie instantanée ni exhaustive
- Les sites qui servent du contenu vide en HTML source prennent un risque majeur d'indexation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. On observe régulièrement des sites React ou Vue en CSR (Client-Side Rendering) qui galèrent à se faire indexer correctement. L'outil "Inspection d'URL" dans Search Console montre clairement la différence entre HTML source et rendu — et c'est le rendu qui compte.
Mais il faut nuancer : Google tente d'exécuter le JavaScript, mais ça ne signifie pas qu'il le fait toujours parfaitement. Les timeouts, les erreurs JS, les ressources bloquées (par robots.txt ou CSP), les dépendances externes lentes — tout ça peut empêcher le rendu complet. Et quand ça rate, ton contenu n'existe pas pour Google.
Quels sont les pièges que cette déclaration ne mentionne pas ?
Martin Splitt ne parle pas du délai entre crawl et rendu. Google crawle d'abord l'HTML source, puis met en file d'attente le rendu JavaScript — ça peut prendre plusieurs jours sur un site à faible crawl budget. Pendant ce temps, ton contenu n'est pas indexé.
Autre point occulté : l'instabilité du rendu. Si ton contenu change entre deux snapshots (parce qu'il dépend d'une API externe, d'un A/B test, d'un timestamp), Google peut voir un contenu différent à chaque passage. Résultat : incohérence dans l'indexation, voire désindexation. [À vérifier] : Google ne communique pas clairement sur la fréquence de mise à jour de ces snapshots ni sur leur stabilité dans le temps.
Dans quels cas cette distinction devient-elle critique ?
Trois scénarios à surveiller de près :
- Sites e-commerce en SPA : si tes fiches produits se chargent en JS, Google peut voir des pages vides. J'ai vu des catalogues entiers perdre leur indexation à cause de ça.
- Sites multilingues avec JS : si la langue se switch côté client sans SSR, Google peut indexer la mauvaise langue ou un mélange incohérent.
- Contenu personnalisé/géolocalisé : si ton contenu varie selon l'IP ou le user-agent, l'instantané de Google peut ne pas refléter ce que l'utilisateur voit réellement.
Impact pratique et recommandations
Que faut-il vérifier concrètement sur ton site ?
Première étape : compare l'HTML source et l'HTML rendu. Ouvre ton site, fais "Afficher la source", puis regarde l'onglet "Inspecter l'élément" (DOM live). Si ton contenu principal n'existe que dans le second, tu as un problème.
Deuxième vérification : utilise l'outil d'inspection d'URL de Google Search Console. Regarde la capture d'écran du rendu et le HTML rendu. Compare avec ce que tu vois en navigation normale. Si Google voit une page vide ou incomplète, tu perds de l'indexation.
Quelles solutions adopter pour éviter les problèmes d'indexation ?
Si tu es en CSR pur (Client-Side Rendering), passe au SSR (Server-Side Rendering) ou SSG (Static Site Generation). Next.js, Nuxt, SvelteKit — tous ces frameworks permettent de servir du HTML déjà rendu côté serveur. Ton HTML source contiendra directement le contenu, pas un shell vide.
Si tu ne peux pas migrer immédiatement, implémente du pre-rendering pour les pages critiques : utilise un service comme Prerender.io ou Rendertron pour servir du HTML statique aux bots. Mais attention — cette solution est un pansement, pas une stratégie long terme.
Comment s'assurer que le rendu Google est stable dans le temps ?
Mets en place un monitoring du HTML rendu via des outils comme OnCrawl, Botify ou Screaming Frog (avec rendu JavaScript activé). Crawle ton site régulièrement et compare les snapshots rendus pour détecter les variations de contenu.
Vérifie aussi que ton JavaScript ne génère pas d'erreurs silencieuses qui empêcheraient le rendu complet. Les erreurs dans la console peuvent bloquer l'exécution du JS par Googlebot sans que tu le saches.
- Vérifie que ton contenu principal existe dans l'HTML source, pas seulement dans le rendu JS
- Utilise l'outil d'inspection d'URL de Search Console pour voir ce que Googlebot voit réellement
- Compare régulièrement HTML source et HTML rendu sur tes pages stratégiques
- Si tu es en CSR pur, migre vers du SSR ou SSG pour servir du HTML déjà rendu
- Mets en place un monitoring du rendu JavaScript pour détecter les régressions
- Teste que ton JavaScript s'exécute sans erreur côté bot (pas seulement côté navigateur classique)
- Évite le lazy loading pour le contenu principal visible au-dessus de la ligne de flottaison
❓ Questions frequentes
Est-ce que Google indexe aussi l'HTML source ou uniquement le rendu ?
Combien de temps Google met-il pour rendre le JavaScript après le crawl initial ?
Le pre-rendering pour les bots est-il considéré comme du cloaking par Google ?
Comment vérifier rapidement si mon contenu est visible dans l'HTML rendu par Google ?
Un site en SSR (Server-Side Rendering) a-t-il toujours un avantage SEO sur du CSR ?
🎥 De la même vidéo 6
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/07/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.