Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il vraiment baliser son contenu payant avec la structured data 'paywall' ?
- □ Faut-il vraiment empêcher le contenu paywall de se charger dans le DOM ?
- □ Pourquoi robots.txt ne protège-t-il pas vos contenus privés de l'indexation Google ?
- □ Pourquoi vos pages privées n'apparaissent jamais dans Google malgré leur indexation ?
- □ Faut-il vraiment enrichir vos pages de login pour améliorer leur indexation ?
- □ Faut-il vraiment rediriger vos pages privées vers du contenu marketing plutôt qu'un simple login ?
- □ Pourquoi Google refuse-t-il d'indexer les intranets d'entreprise ?
- □ Pourquoi vos URLs peuvent trahir vos données privées malgré un contenu protégé ?
- □ Faut-il vraiment tester son site en navigation privée pour évaluer sa visibilité SEO ?
- □ Google donne-t-il vraiment des conseils SEO privilégiés à ses propres équipes ?
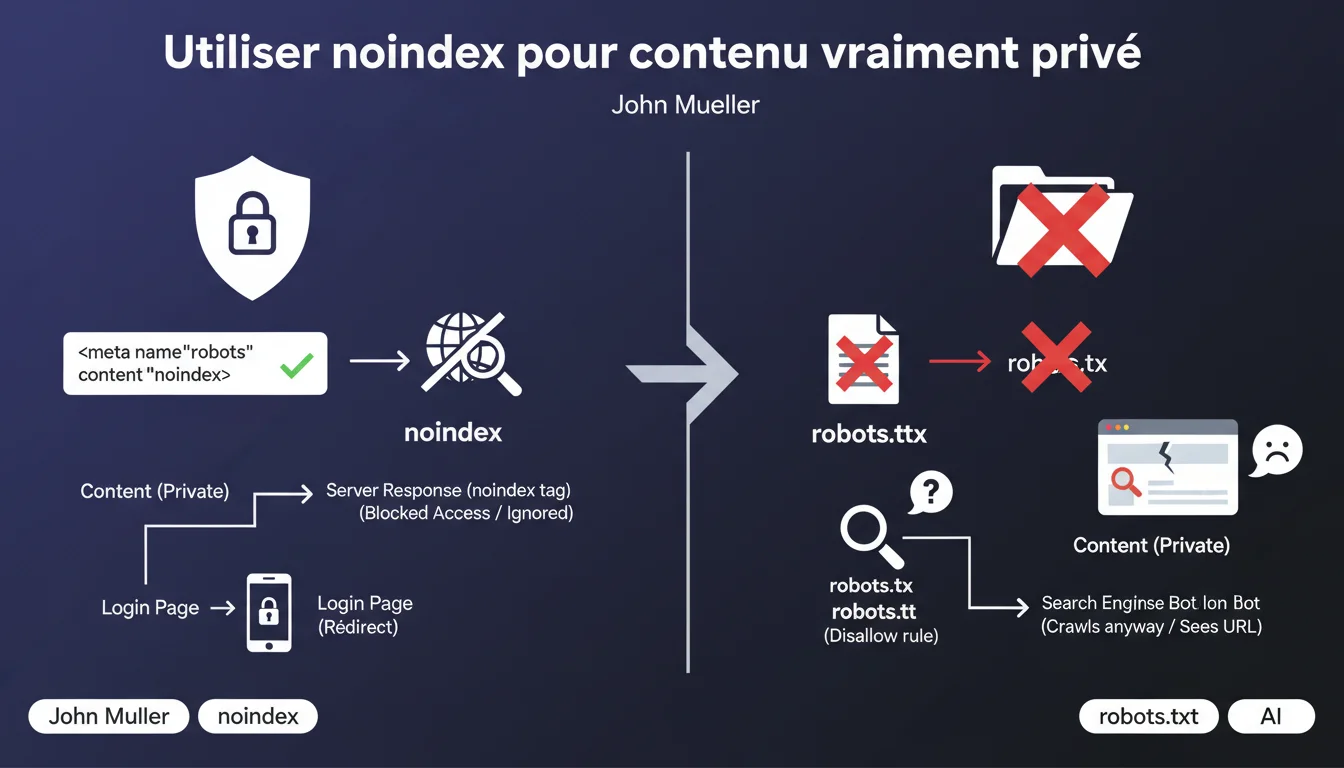
Google rappelle que robots.txt ne sécurise rien — il empêche simplement le crawl. Pour du contenu réellement privé, utilisez la balise noindex ou forcez une authentification. Bloquer via robots.txt laisse vos URLs découvrables et indexables sans contenu.
Ce qu'il faut comprendre
Pourquoi robots.txt ne suffit-il pas pour protéger du contenu confidentiel ?
Le fichier robots.txt indique aux crawlers de ne pas explorer certaines URLs, mais il ne les rend pas invisibles. Google peut toujours découvrir ces URLs via des backlinks, des sitemaps ou des références internes, et les indexer avec un snippet générique du type « Aucune information disponible ».
Résultat ? Vos pages privées apparaissent dans les SERP avec leur URL visible — parfois suffisant pour comprendre ce qu'elles contiennent. Imaginez des URLs comme /admin/users/passwords-reset ou /clients/contrat-confidentiel-2024.pdf qui s'affichent publiquement.
Quelle est la différence entre bloquer le crawl et bloquer l'indexation ?
Bloquer le crawl (robots.txt) empêche Googlebot de lire le contenu, mais ne l'empêche pas d'indexer l'URL si elle est découverte ailleurs. Bloquer l'indexation (balise noindex) autorise le crawl mais ordonne explicitement à Google de ne jamais afficher la page dans ses résultats.
C'est contre-intuitif, mais c'est comme ça que fonctionne le moteur : une URL bloquée en robots.txt peut quand même finir dans l'index. Une URL avec noindex, elle, ne le sera jamais — même si Google la crawle.
Quelle solution technique adopter pour du contenu vraiment sensible ?
Deux approches recommandées par Google : soit vous servez la page avec une balise meta noindex (ou un header HTTP X-Robots-Tag: noindex), soit vous redirigez vers une page de login pour tout utilisateur non authentifié.
La seconde option est la plus propre pour du contenu strictement privé : si l'utilisateur n'est pas connecté, il tombe sur un formulaire d'authentification. Google crawle donc une page de login, pas le contenu sensible lui-même.
- robots.txt bloque le crawl mais n'empêche pas l'indexation de l'URL
- noindex empêche l'indexation mais nécessite que Google puisse crawler la page
- La redirection vers login est la solution la plus étanche pour du contenu strictement confidentiel
- Ne jamais exposer d'URLs sensibles sans protection au niveau applicatif
Avis d'un expert SEO
Cette consigne est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. On voit régulièrement des sites qui bloquent des sections entières en robots.txt et se retrouvent avec des dizaines d'URLs indexées sans contenu. Certains découvrent le problème via Search Console, section Couverture, sous l'étiquette « Bloquée par robots.txt ».
Le problème, c'est que beaucoup de CMS ou de frameworks génèrent automatiquement des règles robots.txt trop larges — pensant bien faire, ils exposent finalement des URLs qu'ils voulaient masquer. Et c'est là que ça coince.
Dans quels cas peut-on quand même utiliser robots.txt ?
Robots.txt reste pertinent pour gérer le budget de crawl : bloquer des facettes inutiles, des paramètres de session, des pages de pagination infinies. Bref, du contenu techniquement public mais sans valeur SEO.
Mais dès qu'on parle de données sensibles — espaces clients, documents confidentiels, backoffice — robots.txt devient une fausse sécurité. Un expert en sécurité informatique vous le confirmera : ce fichier n'est qu'une indication polie, pas un verrou.
Quelle erreur classique voit-on encore trop souvent ?
Des sites qui bloquent leur espace membre en robots.txt, puis ajoutent une balise noindex dans le code HTML. Sauf que Google ne peut jamais lire cette balise puisqu'il ne crawle pas la page — donc elle reste potentiellement indexable.
Autre cas fréquent : des redirections 302 temporaires vers une page de login, alors qu'une 301 ou une gestion propre du statut HTTP (401/403) serait plus claire pour le moteur. Google peut interpréter un 302 comme une page de destination légitime à indexer.
Impact pratique et recommandations
Que faut-il faire concrètement sur un site existant ?
Première étape : auditer Search Console pour repérer les URLs indexées mais bloquées par robots.txt. Elles apparaissent avec un avertissement explicite. Si vous en trouvez, c'est qu'elles sont découvrables — donc potentiellement visibles dans les SERP.
Ensuite, déterminez si ce contenu doit vraiment être privé. Si oui, retirez la ligne correspondante du robots.txt et ajoutez une balise noindex ou une redirection vers login. Attendez quelques semaines que Google re-crawle, puis demandez la suppression via l'outil dédié dans Search Console si nécessaire.
Comment implémenter proprement une protection par noindex ?
Dans le HTML : <meta name="robots" content="noindex, nofollow"> directement dans le <head>. Simple, mais nécessite que la page soit crawlable — donc pas de blocage robots.txt sur cette URL.
Via HTTP header : X-Robots-Tag: noindex dans la réponse serveur. Pratique pour des fichiers PDF, images, ou contenus générés dynamiquement sans <head> HTML classique. Cette méthode est souvent plus propre techniquement et plus difficile à oublier lors de refonte.
Quelles erreurs éviter absolument ?
Ne jamais cumuler robots.txt et noindex sur la même URL — Google ne pourra pas lire la directive noindex s'il est bloqué au crawl. Résultat : l'URL reste indexable.
Autre piège : utiliser noindex sur des pages qu'on veut garder en interne mais pas dans Google. Si ces pages reçoivent du PageRank via des liens internes, le noindex coupe la transmission de jus. Mieux vaut alors une authentification côté serveur.
- Auditer Search Console pour identifier les URLs bloquées en robots.txt mais indexées
- Retirer du robots.txt toute URL contenant des données sensibles
- Implémenter noindex (meta ou HTTP header) ou redirection vers login selon le niveau de confidentialité
- Vérifier que les pages avec noindex restent crawlables (pas de blocage robots.txt)
- Pour les espaces membres ou backoffice, privilégier une vraie authentification applicative (401/403)
- Tester avec un crawler (Screaming Frog, Oncrawl) pour valider que les directives sont bien lues
- Demander la suppression d'URLs déjà indexées via l'outil de suppression temporaire Search Console
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/09/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.