Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il vraiment baliser son contenu payant avec la structured data 'paywall' ?
- □ Faut-il vraiment empêcher le contenu paywall de se charger dans le DOM ?
- □ Pourquoi robots.txt ne protège-t-il pas vos contenus privés de l'indexation Google ?
- □ Pourquoi robots.txt ne protège-t-il pas votre contenu privé ?
- □ Pourquoi vos pages privées n'apparaissent jamais dans Google malgré leur indexation ?
- □ Faut-il vraiment enrichir vos pages de login pour améliorer leur indexation ?
- □ Faut-il vraiment rediriger vos pages privées vers du contenu marketing plutôt qu'un simple login ?
- □ Pourquoi Google refuse-t-il d'indexer les intranets d'entreprise ?
- □ Faut-il vraiment tester son site en navigation privée pour évaluer sa visibilité SEO ?
- □ Google donne-t-il vraiment des conseils SEO privilégiés à ses propres équipes ?
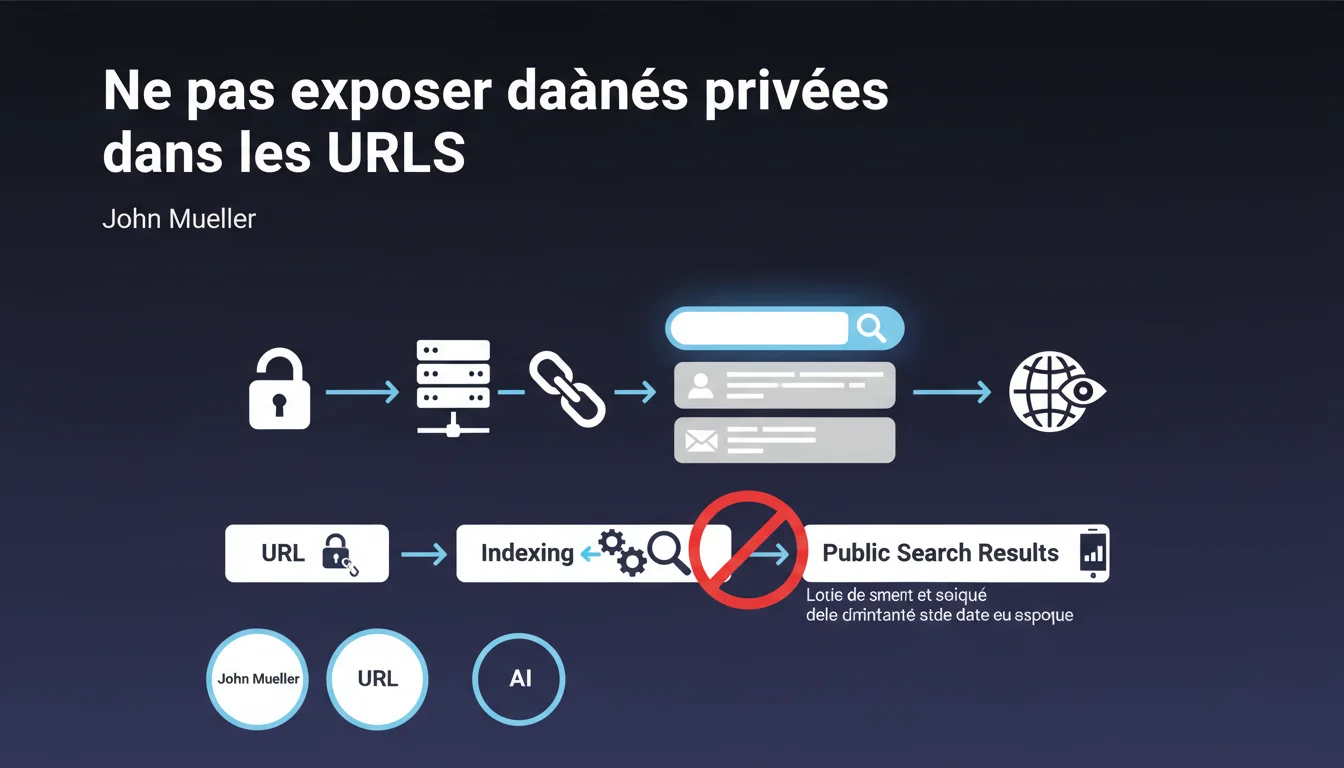
Les URLs contenant des informations privées (usernames, emails, tokens) peuvent être indexées par Google même si le contenu lui-même est protégé. Cette fuite d'information passe souvent inaperçue car les crawlers accèdent aux URLs avant de vérifier les permissions. Résultat : des données sensibles exposées dans les SERP alors que la page elle-même est inaccessible.
Ce qu'il faut comprendre
Comment une URL protégée peut-elle finir dans l'index Google ?
C'est un piège classique. Vous avez beau avoir mis en place une authentification solide, un système de permissions, voire un robots.txt — si l'URL elle-même transite quelque part (logs serveur, referrers, partages accidentels), elle peut être découverte.
Google crawle d'abord, vérifie ensuite. L'URL entre dans l'index, et même si le bot comprend plus tard qu'il n'a pas accès au contenu, l'URL reste visible dans les résultats de recherche. Avec tout ce qu'elle contient : nom d'utilisateur, email, parfois même des tokens de session.
Quels types de données sont concernés par ce risque ?
Tout ce qui identifie une personne ou révèle une information sensible. Les cas les plus fréquents : usernames dans les profils utilisateurs, adresses email en paramètre GET, identifiants de documents confidentiels, tokens de réinitialisation de mot de passe.
Le problème, c'est que ces infos semblent anodines en interne. Personne ne pense à protéger l'URL elle-même — on protège le contenu. Sauf que l'URL, c'est déjà de la donnée.
- Exposition involontaire : même avec un contenu inaccessible, l'URL apparaît dans les SERP
- Risque RGPD : une adresse email dans une URL indexée = donnée personnelle publique
- Surface d'attaque : les URLs révèlent la structure de votre système (patterns d'IDs, formats de tokens)
- Fuites multiples : referrers HTTP, logs analytics, partages involontaires propagent ces URLs
Google bloque-t-il ces URLs si le contenu est en 401 ou 403 ?
Pas automatiquement. Google peut garder une URL dans l'index même si elle retourne un code d'erreur d'authentification. L'URL s'affiche, parfois avec un snippet générique, parfois avec des bribes récupérées ailleurs.
Techniquement, un 401/403 devrait empêcher l'indexation du contenu — mais l'URL, elle, peut persister. Et c'est précisément là que le bât blesse pour les sites qui manipulent des données sensibles dans leurs patterns d'URLs.
Avis d'un expert SEO
Cette recommandation est-elle vraiment appliquée par les sites majeurs ?
Soyons honnêtes : beaucoup de plateformes ignorent ce conseil. Regardez LinkedIn, Twitter, ou même certains CMS d'entreprise — les usernames sont partout dans les URLs. Pourquoi ? Parce que c'est pratique, SEO-friendly pour les profils publics, et que personne n'a pensé au cas limite.
La différence, c'est le contexte de protection. Sur LinkedIn, un profil public avec username dans l'URL, pas de souci. Mais un espace client privé avec /dashboard/user/jean.dupont@entreprise.com/ ? Catastrophe. Le risque se situe dans les zones grises — ces sections semi-privées qu'on croit protégées mais qui laissent fuiter des URLs.
Quelles sont les conséquences réelles d'une telle exposition ?
Au-delà du RGPD (qui peut taper fort), il y a un risque réputationnel. Imaginez un client qui tape son nom dans Google et tombe sur une URL de votre plateforme révélant son email pro. Même s'il ne peut pas accéder à la page, la confiance est rompue.
Côté technique, ces URLs donnent des indices précieux à quiconque veut cartographier votre système. Patterns d'IDs séquentiels, formats de tokens, structure de permissions — tout ça devient visible. C'est du renseignement gratuit pour un attaquant potentiel.
Dans quels cas peut-on quand même utiliser des identifiants dans les URLs ?
Dès que c'est public par conception. Un profil utilisateur destiné à être visible, un article de blog signé, une page entreprise — là, pas de problème. L'identifiant dans l'URL sert même le SEO.
Le critère : est-ce que cette information est censée être publique ? Si oui, l'URL peut la porter. Si non, il faut passer par des identifiants opaques (UUIDs, hashs) et s'assurer que la page elle-même bloque l'indexation via X-Robots-Tag: noindex en HTTP header — pas juste un meta robots, qui nécessite de charger le HTML.
Impact pratique et recommandations
Comment auditer son site pour détecter ces fuites d'URLs ?
Première étape : requête site: dans Google. Cherchez site:votredomaine.com combiné avec des patterns typiques (email, username connus, formats de tokens). Vous serez surpris de ce qui remonte.
Ensuite, vérifiez vos logs serveur. Regardez quelles URLs ont été crawlées par Googlebot dans vos sections privées. Si vous voyez des URLs avec données sensibles et un user-agent Google, vous avez un problème — même si le bot s'est pris un 401.
Enfin, passez en revue vos sitemaps et liens internes. Parfois, c'est votre propre site qui expose ces URLs via un lien mal placé dans une section publique.
Quelles modifications techniques faut-il mettre en place immédiatement ?
- Remplacer les identifiants lisibles (usernames, emails) par des UUIDs ou hashs dans toutes les URLs de sections privées
- Ajouter un X-Robots-Tag: noindex, nofollow en header HTTP sur toutes les pages authentifiées (ne pas compter sur le meta robots)
- Vérifier que les pages protégées retournent bien un 401 ou 403 avant même de servir du HTML
- Configurer le robots.txt pour bloquer les patterns d'URLs sensibles (mais attention : ça empêche le crawl, pas forcément l'indexation d'URLs découvertes ailleurs)
- Implémenter une politique de suppression d'URLs via Google Search Console pour les URLs déjà indexées
- Auditer les referrers et logs analytics pour identifier les fuites potentielles d'URLs privées
Que faire si des URLs sensibles sont déjà dans l'index Google ?
Pas de panique, mais il faut agir vite. Utilisez l'outil de suppression d'URL de Google Search Console pour retirer temporairement ces URLs des résultats. Temporairement, car ça ne dure que 6 mois.
En parallèle, ajoutez le X-Robots-Tag: noindex sur ces URLs et assurez-vous qu'elles retournent un 401. Une fois que Google recrawle et voit le noindex, l'URL disparaîtra définitivement de l'index.
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/09/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.