Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il vraiment baliser son contenu payant avec la structured data 'paywall' ?
- □ Faut-il vraiment empêcher le contenu paywall de se charger dans le DOM ?
- □ Pourquoi robots.txt ne protège-t-il pas vos contenus privés de l'indexation Google ?
- □ Pourquoi robots.txt ne protège-t-il pas votre contenu privé ?
- □ Faut-il vraiment enrichir vos pages de login pour améliorer leur indexation ?
- □ Faut-il vraiment rediriger vos pages privées vers du contenu marketing plutôt qu'un simple login ?
- □ Pourquoi Google refuse-t-il d'indexer les intranets d'entreprise ?
- □ Pourquoi vos URLs peuvent trahir vos données privées malgré un contenu protégé ?
- □ Faut-il vraiment tester son site en navigation privée pour évaluer sa visibilité SEO ?
- □ Google donne-t-il vraiment des conseils SEO privilégiés à ses propres équipes ?
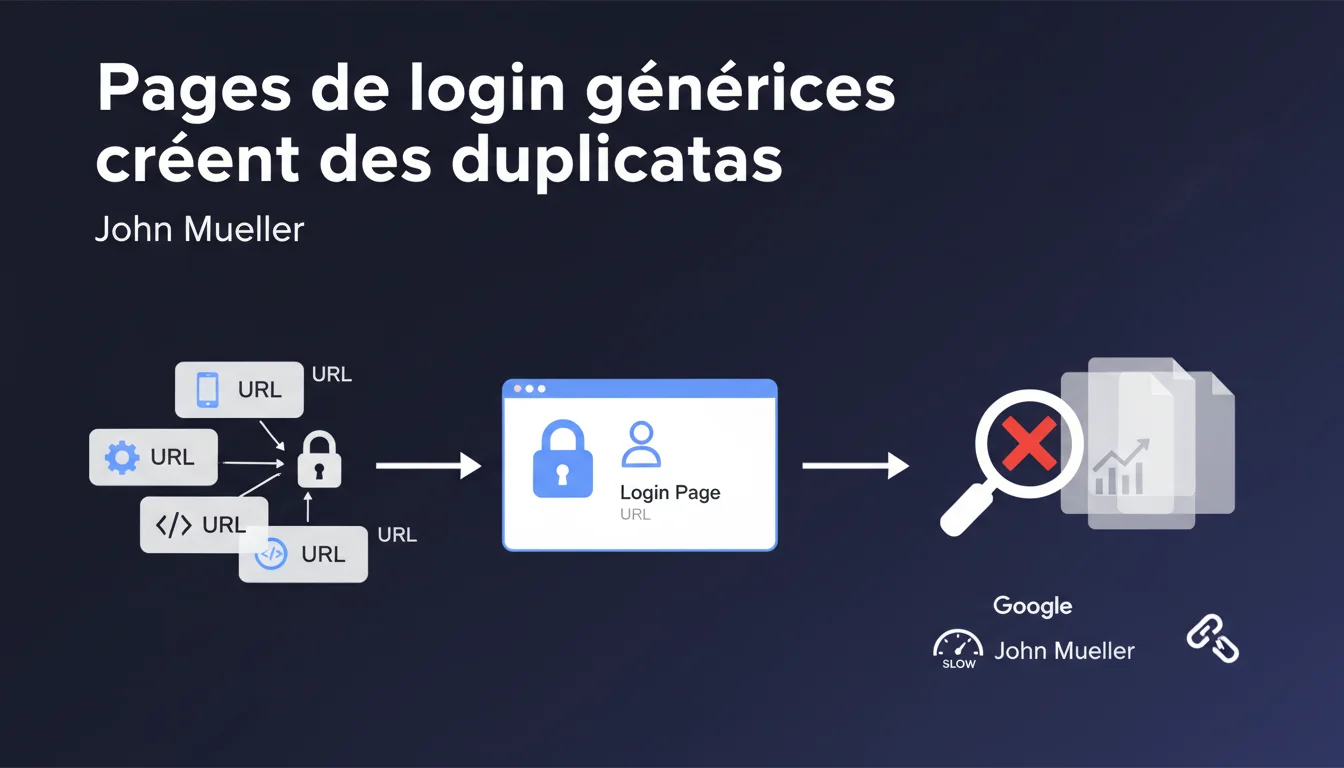
Quand toutes vos URLs privées redirigent vers une seule page de login générique, Google interprète ces URLs comme des duplicatas de la page de connexion. Résultat : c'est cette page de login qui monopolise l'indexation, au détriment du contenu réel que vous cherchiez à protéger. Une situation qui peut sérieusement compromettre votre visibilité si vous ne structurez pas correctement l'accès aux contenus protégés.
Ce qu'il faut comprendre
Comment Google traite-t-il les redirections vers une page de login unique ?
Imaginons un site qui protège 500 URLs différentes — fiches produits, articles premium, espaces membres. Si toutes renvoient vers la même page de connexion générique (disons /login), Google va crawler ces 500 URLs, constater qu'elles affichent toutes le même contenu, et en déduire qu'il s'agit de duplicatas.
Le moteur va alors choisir une URL canonique pour représenter ce contenu dupliqué — et ce sera probablement /login. Les 500 autres URLs ? Elles seront soit désindexées, soit ignorées dans les résultats. Le contenu que vous cherchiez à protéger disparaît purement et simplement de l'index.
Pourquoi cette situation nuit-elle à l'expérience de recherche ?
Mueller parle d'impact sur l'expérience utilisateur — et c'est exactement ça. Un internaute qui cherche "votre produit X premium" tombe sur votre page de login générique dans les SERP. Aucun contexte. Aucune indication sur ce qui se cache derrière. Juste un formulaire de connexion.
Résultat : taux de rebond élevé, frustration, et perte de trafic qualifié. Google détecte ces signaux négatifs et ajuste en conséquence. Vous vous retrouvez pénalisé deux fois : visibilité réduite ET performance dégradée sur ce qui reste indexé.
Quelle différence avec une architecture bien pensée ?
Une structure correcte ne redirige pas. Elle affiche une page intermédiaire contextuelle pour chaque contenu protégé : titre, description, teaser, et invitation à se connecter. Chaque URL garde son identité propre, son contenu unique (même partiel), et peut donc être indexée normalement.
Google comprend qu'il s'agit de pages distinctes avec de la valeur — pas de simples duplicatas d'une porte d'entrée générique. Et l'utilisateur qui arrive dessus sait exactement ce qu'il va débloquer en se connectant.
- Redirection systématique vers /login = toutes les URLs fusionnent en un seul duplicata
- Pages intermédiaires contextuelles = chaque URL conserve son unicité et son potentiel de ranking
- Google privilégie les expériences où l'utilisateur comprend ce qu'il trouvera derrière le login
- Le problème touche aussi les intranets, espaces B2B, contenus payants mal architecturés
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Totalement. On voit régulièrement ce pattern sur des sites SaaS, des plateformes B2B ou des médias avec paywall. Le pire ? Certains ne réalisent même pas que leurs milliers d'URLs protégées ne génèrent aucun trafic organique parce qu'elles sont toutes cannibalisées par la page /login.
Google Search Console peut montrer ces URLs comme "indexées", mais en pratique elles ne rankent jamais — parce qu'elles sont perçues comme des duplicatas. Et quand vous auditez les logs serveur, vous constatez que Googlebot crawle ces pages, mais ne leur accorde aucune importance.
Quelles nuances faut-il apporter à cette recommandation ?
Soyons honnêtes : tous les contenus protégés ne méritent pas d'être indexés. Si vous avez un espace membre strictement privé sans aucun intérêt SEO (tableaux de bord perso, paramètres de compte), bloquer l'indexation via robots.txt ou noindex reste la meilleure option. Pas besoin de créer des pages intermédiaires pour ça.
Le problème surgit quand vous voulez que ces contenus soient découvrables — articles premium, fiches produits réservées, webinaires enregistrés. Là, la redirection générique tue votre stratégie. Et c'est là que la déclaration de Mueller prend tout son sens.
Dans quels cas cette logique ne s'applique-t-elle pas complètement ?
Les sites avec soft paywall (limitation à X articles par mois) échappent généralement au problème s'ils servent le contenu complet à Googlebot via cloaking autorisé (first-click-free, ou schéma Paywall structuré). Google voit le contenu réel, pas la barrière de login.
Mais attention — cette exception fonctionne uniquement si vous suivez les guidelines de Google sur les paywalls. Sinon, vous risquez d'être traité comme du cloaking abusif. Et ça, c'est une pénalité manuelle assurée.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce piège ?
Arrêtez les redirections 302 ou 301 vers une page de login unique dès qu'une URL protégée est appelée. À la place, servez une page intermédiaire avec un code 200 OK, qui contient un aperçu du contenu (titre, meta, introduction, schema markup) et un CTA pour se connecter.
Cette page doit être suffisamment unique pour que Google la distingue des autres. Si vous avez 100 produits premium, vous devez avoir 100 pages intermédiaires différentes — pas 100 clones avec juste le titre qui change.
Pour les contenus vraiment sensibles ou sans valeur SEO ? Bloquez l'accès dès robots.txt ou via balise noindex. Ne laissez pas Google crawler des URLs que vous ne voulez pas voir indexées.
Quelles erreurs éviter absolument ?
Ne créez pas de "fausses" pages intermédiaires avec 3 lignes de texte générique et le même template partout. Google va détecter le thin content et la duplication, et vous n'y gagnerez rien. Pire : vous risquez de diluer votre crawl budget sur des pages sans valeur.
Autre piège : utiliser un paramètre d'URL pour la redirection (genre /login?redirect=/produit-premium). Google peut ignorer le paramètre et considérer toutes ces variantes comme une seule page. Résultat identique : cannibalisation par la page de login.
Comment vérifier que votre site est conforme ?
Crawlez votre site avec Screaming Frog ou Oncrawl en simulant Googlebot. Repérez toutes les URLs qui renvoient un code 3xx vers /login. Si vous en trouvez des dizaines ou centaines, vous avez un problème structurel.
Vérifiez aussi dans Search Console : inspectez quelques URLs protégées et regardez le rendu HTML que Google voit. S'il affiche systématiquement votre formulaire de login sans contexte, c'est que votre architecture échoue le test.
- Auditer toutes les redirections vers des pages de login génériques
- Remplacer les redirections par des pages intermédiaires contextuelles (code 200)
- S'assurer que chaque page intermédiaire contient du contenu unique et pertinent
- Bloquer l'indexation (robots.txt ou noindex) des espaces purement privés sans intérêt SEO
- Implémenter le balisage schema Paywall si vous utilisez un modèle d'abonnement
- Tester le rendu Googlebot via Search Console pour valider que le contenu différencié est bien visible
- Monitorer les performances organiques des URLs protégées pour détecter toute chute suspecte
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/09/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.