Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Faut-il vraiment baliser son contenu payant avec la structured data 'paywall' ?
- □ Pourquoi robots.txt ne protège-t-il pas vos contenus privés de l'indexation Google ?
- □ Pourquoi robots.txt ne protège-t-il pas votre contenu privé ?
- □ Pourquoi vos pages privées n'apparaissent jamais dans Google malgré leur indexation ?
- □ Faut-il vraiment enrichir vos pages de login pour améliorer leur indexation ?
- □ Faut-il vraiment rediriger vos pages privées vers du contenu marketing plutôt qu'un simple login ?
- □ Pourquoi Google refuse-t-il d'indexer les intranets d'entreprise ?
- □ Pourquoi vos URLs peuvent trahir vos données privées malgré un contenu protégé ?
- □ Faut-il vraiment tester son site en navigation privée pour évaluer sa visibilité SEO ?
- □ Google donne-t-il vraiment des conseils SEO privilégiés à ses propres équipes ?
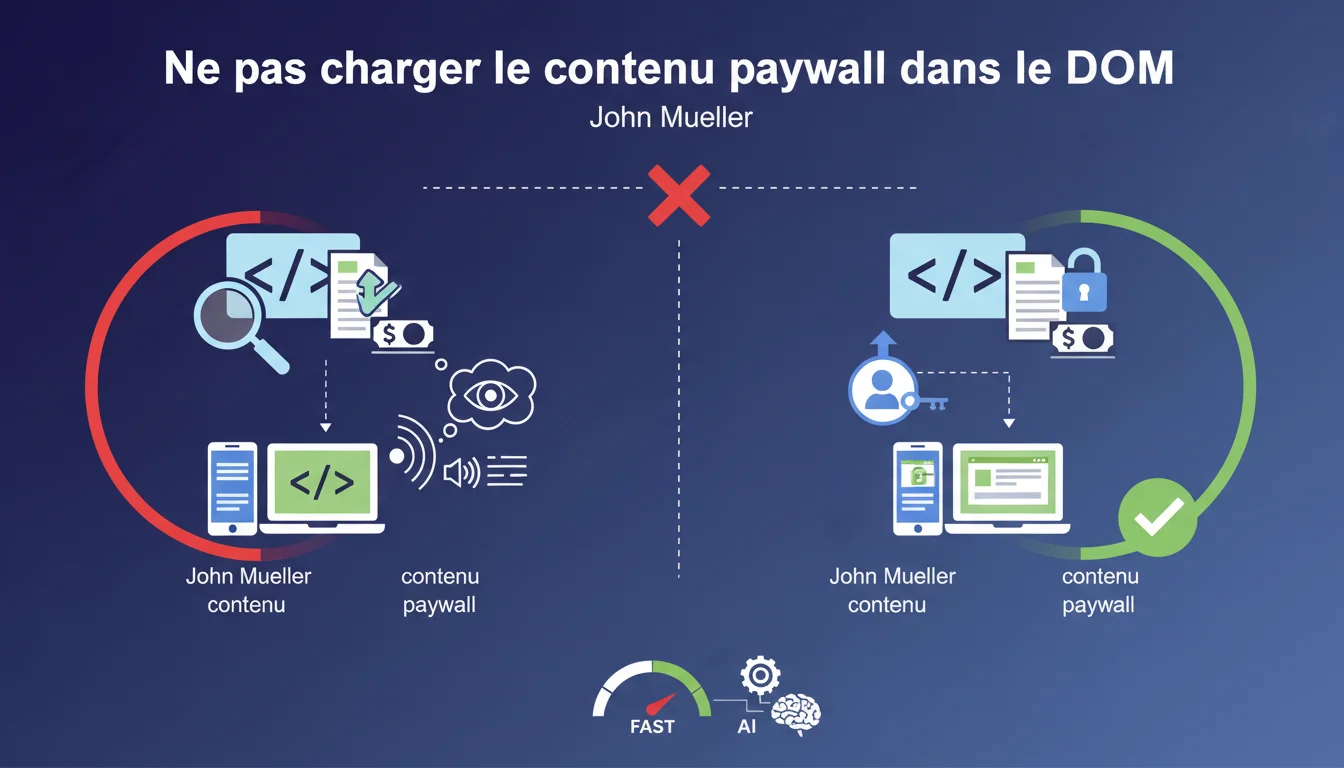
Google demande explicitement de ne pas charger le contenu complet d'un article paywall dans le HTML/DOM de la page. Le contenu protégé ne doit être servi que lorsque l'utilisateur y a effectivement accès, notamment pour éviter que les lecteurs d'écran n'exposent l'intégralité du texte caché. Cette consigne pose des questions techniques et SEO importantes pour tous les sites qui monétisent leur contenu.
Ce qu'il faut comprendre
Pourquoi Google précise-t-il cette règle maintenant ?
Cette déclaration de John Mueller n'est pas nouvelle dans le fond, mais elle clarifie un point technique souvent mal compris. Beaucoup de sites utilisent encore des techniques CSS/JavaScript pour masquer visuellement le contenu paywall, tout en le chargeant entièrement dans le DOM HTML.
Le problème — et Google le dit sans détour — c'est que cette approche expose le contenu aux technologies d'assistance comme les lecteurs d'écran. Un utilisateur malvoyant pourrait ainsi accéder gratuitement à un contenu censé être payant, simplement parce que son lecteur d'écran lit tout ce qui est présent dans le DOM.
Cette consigne vise-t-elle uniquement l'accessibilité ?
Non. L'argument de l'accessibilité est celui mis en avant, mais il y a une dimension SEO directe. Si le contenu complet est dans le DOM, Googlebot peut techniquement y accéder aussi, même si vous tentez de le masquer avec CSS.
Google a toujours eu une position ambiguë sur les paywalls : il veut que les éditeurs puissent monétiser, mais il veut aussi indexer du contenu. La solution officielle reste le balisage structured data pour paywalls, mais cela suppose que le contenu protégé ne soit pas entièrement exposé côté client.
Quelle différence avec le cloaking ?
C'est là que ça devient délicat. Charger du contenu uniquement pour Googlebot serait du cloaking pur et dur, sanctionnable. Mais ne pas charger le contenu paywall dans le DOM pour un utilisateur non-abonné, c'est légitime — à condition que Google puisse quand même comprendre qu'il y a du contenu protégé.
Le balisage schema.org/Article avec la propriété isAccessibleForFree: false est censé gérer ce cas. Mais concrètement, si le contenu n'est jamais dans le HTML, comment Google évalue-t-il sa qualité et sa pertinence pour le classement ?
- Ne jamais charger le contenu complet d'un article paywall dans le DOM HTML
- Utiliser le balisage structured data pour signaler le contenu protégé à Google
- Servir le contenu uniquement après authentification côté serveur, pas via JavaScript côté client
- Les lecteurs d'écran ne doivent pas pouvoir accéder au contenu caché
- Cette règle s'applique aussi bien pour l'accessibilité que pour éviter toute ambiguïté SEO
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Pas vraiment. La majorité des grands médias qui ont des paywalls utilisent encore des techniques hybrides : une partie du contenu visible en clair, le reste chargé dans le DOM mais masqué avec display:none ou via un overlay JavaScript.
Certains — comme The New York Times ou Le Monde — ont des implémentations sophistiquées qui chargent effectivement le contenu côté serveur après authentification. Mais beaucoup de sites de niche ou de presse régionale laissent traîner le HTML complet, en comptant sur l'obscurité technique pour protéger leur contenu. Google vient de leur dire : ça ne passe plus.
Quelles nuances faut-il apporter ?
Google ne dit pas qu'il faut tout bloquer. Le conseil officiel reste de montrer un aperçu suffisant pour que l'utilisateur — et le moteur de recherche — comprenne de quoi parle l'article. C'est le principe du « metered paywall » ou du lead visible.
Mais la limite entre « aperçu légitime » et « contenu complet caché » est floue. Si vous chargez 80% de l'article dans le DOM en pensant que c'est un aperçu, vous êtes hors-jeu. Le vrai critère, c'est : est-ce que quelqu'un pourrait contourner votre paywall en inspectant le code source ? Si oui, Google considère que vous servez le contenu, même s'il est masqué.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous utilisez un système de soft paywall avec un quota d'articles gratuits par mois, la règle s'applique quand même : le contenu ne doit être chargé que si l'utilisateur a encore du quota. Pas de shortcut consistant à tout charger et à décider côté client.
En revanche, si votre modèle est un simple registration wall (inscription gratuite obligatoire), vous pouvez charger le contenu dans le DOM pour tous les utilisateurs inscrits. La distinction clé : est-ce que l'accès est conditionné à un paiement ou à un statut vérifié côté serveur ? Si oui, pas de contenu dans le DOM avant validation.
Impact pratique et recommandations
Que faut-il faire concrètement si mon site a un paywall ?
Première étape : auditer votre implémentation actuelle. Ouvrez un article paywall en navigation privée, sans être connecté, et inspectez le code source HTML. Si le contenu complet apparaît quelque part — même dans un div masqué, même en JSON inline — vous êtes concerné.
Ensuite, modifiez votre architecture pour que le contenu protégé soit servi uniquement après authentification côté serveur. Concrètement : l'utilisateur non-abonné reçoit un HTML avec le lead et un placeholder, et le contenu complet n'est jamais envoyé par le serveur tant qu'il n'a pas payé.
Quelles erreurs éviter absolument ?
Ne tentez pas de contourner la règle en chargeant le contenu via JavaScript asynchrone après le chargement initial. Si le script côté client récupère le texte complet et l'injecte dans le DOM, vous êtes toujours en infraction — et en plus, vous compliquez l'indexation pour Google.
Autre erreur classique : utiliser aria-hidden="true" en pensant que ça suffit à cacher le contenu aux lecteurs d'écran. Non. Si le texte est dans le DOM, les outils d'accessibilité peuvent y accéder. La seule solution vraiment propre, c'est de ne pas envoyer le contenu au client.
Comment vérifier que mon site est conforme ?
- Ouvrir un article paywall en navigation privée (sans être connecté)
- Inspecter le code source HTML brut — pas seulement le rendu visuel
- Vérifier qu'aucun élément DOM ne contient le texte complet de l'article
- Tester avec un lecteur d'écran (NVDA, JAWS) pour confirmer que le contenu protégé n'est pas lu
- S'assurer que le balisage structured data inclut
isAccessibleForFree: false - Contrôler que le contenu complet n'est chargé qu'après authentification serveur validée
- Vérifier que les scripts JavaScript côté client ne récupèrent pas le contenu en clair
Cette consigne de Google impose une refonte technique pour beaucoup de sites qui ont implémenté leur paywall de manière approximative. Le message est clair : le contenu payant ne doit jamais être envoyé au client tant que l'utilisateur n'y a pas légitimement accès.
L'enjeu dépasse l'accessibilité — c'est une question de cohérence entre ce que vous vendez et ce que vous exposez techniquement. Un audit rigoureux de votre implémentation actuelle s'impose.
Ces modifications peuvent être complexes selon votre stack technique, notamment si votre paywall repose sur des solutions tierces ou des CMS avec des plugins généricistes. Dans ce contexte, l'accompagnement par une agence SEO spécialisée peut s'avérer précieux pour diagnostiquer les failles, concevoir une architecture conforme et coordonner les ajustements entre équipes éditoriales et techniques, sans compromettre ni l'indexation ni la monétisation.
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/09/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.