Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Faut-il changer de domaine lors d'une réduction de catalogue ou conserver l'existant ?
- □ Les backlinks vers une page 404 sont-ils définitivement perdus ou récupérables ?
- □ Peut-on vraiment avoir des millions de redirections 301 sans impacter son SEO ?
- □ Faut-il vraiment ignorer les erreurs 404 dans Google Search Console ?
- □ Faut-il vraiment ajouter les pages paginées dans le sitemap XML ?
- □ Google crawle-t-il vraiment les liens dans les menus déroulants au survol ?
- □ Combien de redirections peut-on vraiment mettre sur un site sans pénalité SEO ?
- □ Faut-il privilégier une personne ou une organisation comme auteur d'un article pour le SEO ?
- □ Faut-il vraiment aligner URL, title et H1 pour ranker en SEO ?
- □ Les tirets multiples dans un nom de domaine pénalisent-ils votre SEO ?
- □ Faut-il publier du contenu tous les jours pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner le texte dans les images pour le SEO ?
- □ Désindexer des URLs : Google limite-t-il vraiment les options à deux méthodes ?
- □ Les Core Web Vitals écrasent-ils vraiment la pertinence dans le classement Google ?
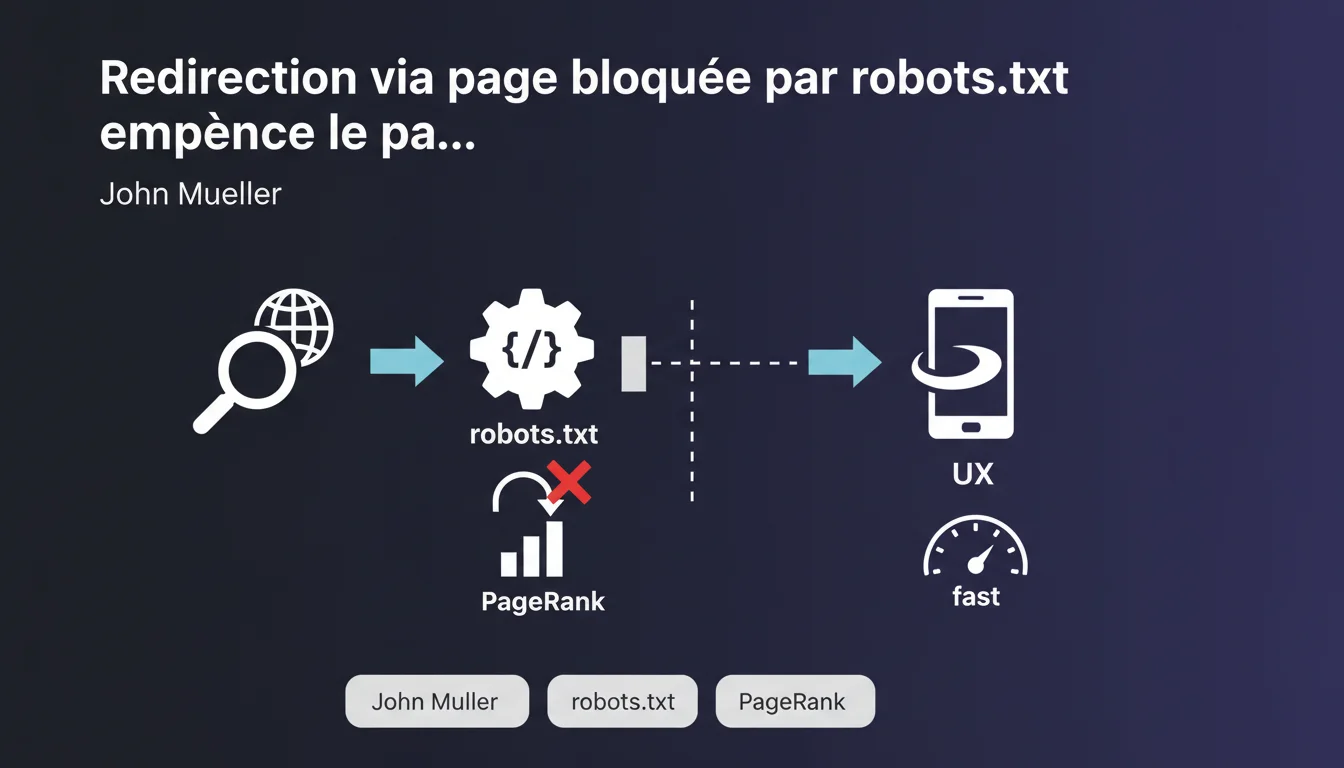
Google confirme qu'une redirection passant par une page bloquée via robots.txt empêche effectivement la transmission des signaux de PageRank. Concrètement, si vous ne voulez pas qu'un lien transmette son jus, intercaler une page intermédiaire bloquée au crawl fait le job. Une technique qui existe depuis des années, maintenant validée officiellement.
Ce qu'il faut comprendre
Pourquoi vouloir bloquer la transmission de PageRank via un lien ?
Les cas de figure ne manquent pas. Vous avez parfois des pages obligatoires d'un point de vue juridique ou fonctionnel — mentions légales générées dynamiquement, pages de connexion multiples, redirections géolocalisées — qui créent des fuites de PageRank inutiles.
Plutôt que de laisser ces URLs consommer du crawl budget et diluer votre budget de liens internes, certains praticiens ont pris l'habitude d'utiliser des pages intermédiaires bloquées pour couper la transmission. Google vient de confirmer que cette pratique fonctionne réellement.
Comment fonctionne concrètement cette technique de blocage ?
Le principe est simple : au lieu de faire pointer un lien directement vers la destination finale, vous le faites passer par une page de redirection intermédiaire. Cette page intermédiaire est ensuite bloquée dans votre robots.txt.
Résultat : Google suit le lien, tombe sur la page intermédiaire, constate qu'elle est bloquée au crawl, et stoppe là. La redirection existe techniquement, mais le bot ne la suit pas — donc aucun signal ne passe.
Cette méthode remplace-t-elle complètement le nofollow ?
Non, et c'est crucial de comprendre la nuance. Le nofollow (ou ugc/sponsored) reste un signal adressé à Google sur la nature du lien. Il est interprété comme une « suggestion » — Google peut choisir de le suivre ou non pour la découverte, mais ne transmettra pas de PageRank.
La technique robots.txt est plus radicale : elle empêche purement et simplement le crawl. Google ne découvre même pas la destination finale via ce chemin. Les deux approches ont des cas d'usage différents.
- Redirection via page bloquée robots.txt = blocage total du passage de signaux
- Technique validée officiellement par John Mueller pour empêcher la transmission de PageRank
- Différent du nofollow qui reste une suggestion interprétable par Google
- Utile pour isoler des sections fonctionnelles qui consomment du budget sans valeur SEO
Avis d'un expert SEO
Cette déclaration correspond-elle aux observations terrain ?
Oui, sans équivoque. Des SEO testent cette technique depuis des années — notamment sur des plateformes e-commerce massives avec des milliers de facettes de navigation ou des systèmes de filtres multi-paramètres. Les résultats terrain montrent effectivement qu'une page bloquée au crawl coupe la chaîne de transmission.
Ce qui change ici, c'est que Google le confirme explicitement. Fini les zones grises : vous pouvez désormais utiliser cette méthode en connaissance de cause, sans craindre une pénalité manuelle pour « tentative de manipulation ».
Quels risques cette approche présente-t-elle en pratique ?
Le principal danger, c'est l'erreur de configuration. Si vous bloquez par erreur une page qui devrait transmettre du PageRank — par exemple une redirection 301 légitime après refonte — vous coupez un flux de signaux précieux. Soyons honnêtes : sur un gros site, ce genre de boulette arrive plus souvent qu'on ne le croit.
Autre point : cette technique peut complexifier sérieusement votre architecture de liens internes. Multiplier les pages intermédiaires bloquées rend le suivi des flux de PageRank beaucoup plus opaque. Vous risquez de perdre la visibilité sur ce qui transite où. [À vérifier] : Google n'a donné aucune indication sur un éventuel seuil au-delà duquel cette pratique pourrait être interprétée comme abusive.
Dans quels cas cette méthode est-elle vraiment pertinente ?
Honnêtement ? Les vrais cas d'usage sont assez limités. Cela devient pertinent sur des architectures très complexes — marketplaces avec des milliers de vendeurs, sites multi-pays avec redirections géolocalisées automatiques, plateformes SaaS avec des dizaines de points d'entrée fonctionnels.
Pour un site classique — même un e-commerce de taille moyenne — vous obtiendrez probablement de meilleurs résultats en optimisant simplement votre maillage interne et en utilisant le nofollow là où c'est pertinent. Pas besoin de sortir l'artillerie lourde si un couteau suisse fait l'affaire.
Impact pratique et recommandations
Comment implémenter cette technique sans se tirer une balle dans le pied ?
Première étape : identifier précisément les pages que vous voulez isoler. Pas de décision au feeling — sortez vos outils d'analyse de crawl (Screaming Frog, OnCrawl, Botify selon votre budget) et repérez les sections qui consomment du budget sans apporter de valeur SEO.
Ensuite, créez vos pages intermédiaires de redirection. Techniquement, ce sont de simples URLs qui redirigent immédiatement (301 ou 302) vers la destination finale. Regroupez-les idéalement dans un répertoire dédié — /redirect/ par exemple — pour simplifier la gestion robots.txt.
Ajoutez la directive Disallow dans votre robots.txt pour bloquer ce répertoire. Testez impérativement avec Google Search Console (outil d'inspection d'URL) pour vérifier que le blocage est bien pris en compte. Et surtout : documentez votre configuration. Dans six mois, vous aurez oublié pourquoi ces URLs sont bloquées.
Quelles erreurs faut-il absolument éviter ?
Ne bloquez JAMAIS une page de redirection qui fait partie d'une migration de site ou d'une refonte d'URLs. Ces redirections doivent impérativement transmettre le PageRank — les bloquer reviendrait à jeter à la poubelle tout le capital de liens accumulé.
Évitez aussi de multiplier les couches. Certains ont la tentation de créer des chaînes de redirections — A vers B (bloquée) vers C vers D — dans l'idée de « mieux contrôler ». Résultat : une usine à gaz incompréhensible qui génère plus de problèmes qu'elle n'en résout.
Comment vérifier que la configuration fonctionne correctement ?
Utilisez Google Search Console pour inspecter vos pages intermédiaires. Si Google indique « Bloquée par le fichier robots.txt », c'est bon signe. Vérifiez également que les pages de destination finale ne remontent pas d'erreurs de crawl liées à des redirections cassées.
Faites un audit régulier — tous les trimestres minimum — pour vous assurer qu'aucune URL bloquée par erreur ne coupe un flux de PageRank important. Un simple export de votre fichier robots.txt couplé à une analyse de logs suffit pour repérer les anomalies.
- Identifier les sections à isoler via analyse de crawl approfondie
- Créer des pages intermédiaires dans un répertoire dédié (/redirect/)
- Bloquer ce répertoire via robots.txt avec directive Disallow
- Tester la configuration avec Google Search Console
- Ne jamais bloquer des redirections 301 post-migration
- Documenter précisément chaque page bloquée et son objectif
- Auditer la configuration tous les 3 mois minimum
❓ Questions frequentes
Bloquer une page de redirection par robots.txt est-il considéré comme du black hat par Google ?
Quelle est la différence entre bloquer une redirection par robots.txt et utiliser un attribut nofollow ?
Peut-on bloquer des redirections 301 légitimes pour économiser du crawl budget ?
Combien de temps faut-il pour que Google prenne en compte le blocage d'une page de redirection ?
Cette technique fonctionne-t-elle aussi pour les autres moteurs de recherche comme Bing ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/12/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.