Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Faut-il changer de domaine lors d'une réduction de catalogue ou conserver l'existant ?
- □ Les backlinks vers une page 404 sont-ils définitivement perdus ou récupérables ?
- □ Peut-on vraiment avoir des millions de redirections 301 sans impacter son SEO ?
- □ Faut-il vraiment ignorer les erreurs 404 dans Google Search Console ?
- □ Google crawle-t-il vraiment les liens dans les menus déroulants au survol ?
- □ Combien de redirections peut-on vraiment mettre sur un site sans pénalité SEO ?
- □ Faut-il privilégier une personne ou une organisation comme auteur d'un article pour le SEO ?
- □ Faut-il vraiment aligner URL, title et H1 pour ranker en SEO ?
- □ Bloquer une page de redirection par robots.txt peut-il vraiment empêcher le passage du PageRank ?
- □ Les tirets multiples dans un nom de domaine pénalisent-ils votre SEO ?
- □ Faut-il publier du contenu tous les jours pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner le texte dans les images pour le SEO ?
- □ Désindexer des URLs : Google limite-t-il vraiment les options à deux méthodes ?
- □ Les Core Web Vitals écrasent-ils vraiment la pertinence dans le classement Google ?
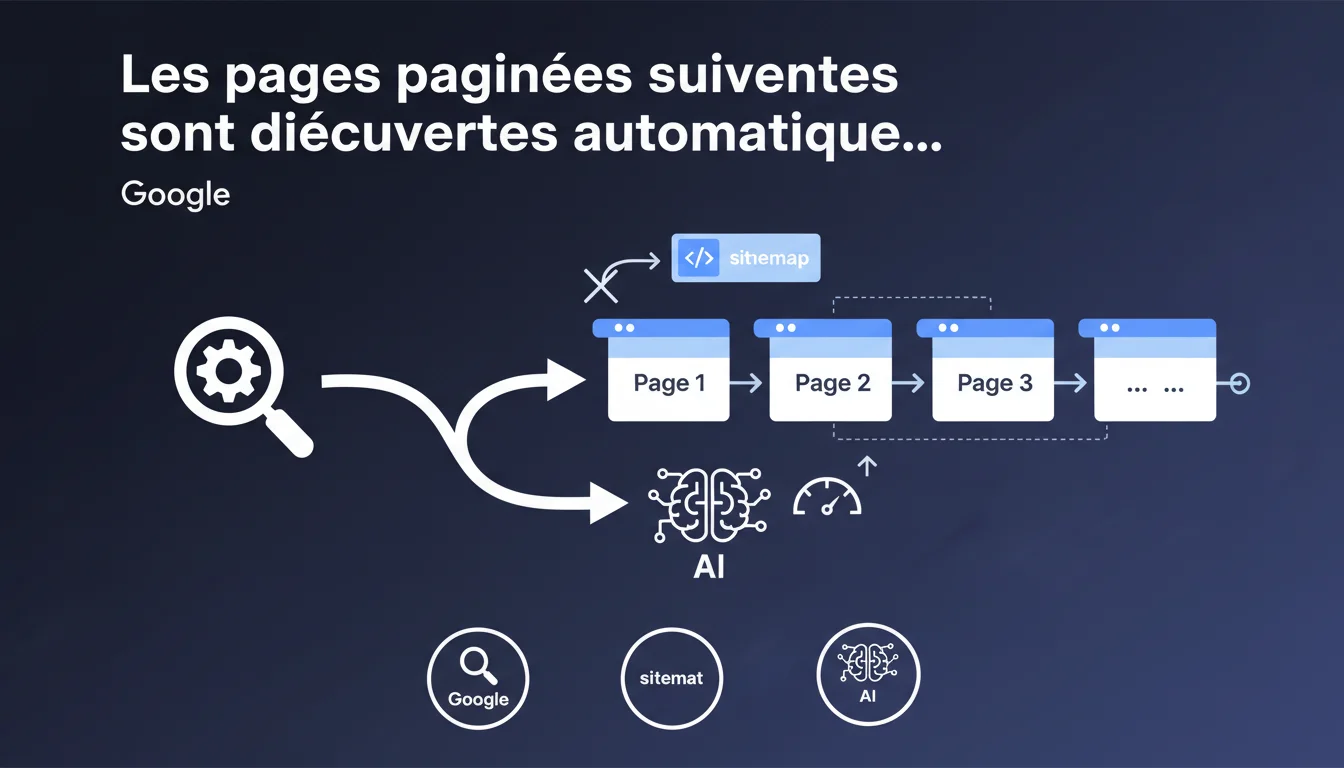
Google découvre automatiquement les pages paginées si chaque page de catégorie a un lien vers la page suivante. L'ajout au sitemap XML n'apporte donc pas d'avantage significatif dans ce cas de figure. La structure de liens internes classique suffit pour le crawl de la pagination.
Ce qu'il faut comprendre
Quel est le mécanisme de découverte des pages paginées par Google ?
Google s'appuie sur le maillage interne pour suivre les liens de pagination. Concrètement, si votre page 1 contient un lien vers la page 2, qui elle-même pointe vers la page 3, Googlebot va naturellement explorer cette chaîne.
Cette déclaration confirme que le sitemap XML n'est pas indispensable pour ce type de contenu. Google fait confiance à la structure de navigation — à condition qu'elle soit logique et crawlable.
Dans quels contextes cette logique s'applique-t-elle ?
Ce principe vaut essentiellement pour les pages de catégories e-commerce ou les listings paginés classiques. Le schéma type : une page 1 avec un bouton "Suivant" qui mène à la page 2, et ainsi de suite.
En revanche, si votre pagination est gérée en JavaScript côté client ou si les liens ne sont pas détectables au crawl initial, la situation change. Google ne peut pas "automatiquement" découvrir ce qu'il ne voit pas dans le HTML brut.
Pourquoi Google précise-t-il "peut-être pas beaucoup d'avantage" ?
Cette formulation prudente traduit une réalité : dans certains cas, le sitemap peut quand même accélérer la découverte ou servir de filet de sécurité. Google ne dit pas "inutile", mais plutôt "redondant".
La nuance est importante. Si votre crawl budget est serré ou que votre architecture est complexe, le sitemap reste un outil de contrôle — même pour la pagination.
- Crawl naturel : Google suit les liens de pagination automatiquement si la structure est claire
- Sitemap XML : Utile comme filet de sécurité, mais pas indispensable dans un cas standard
- Condition sine qua non : Chaque page doit pointer vers la suivante via un lien HTML classique
- Exceptions : Pagination JS, architecture complexe, crawl budget limité
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, dans l'ensemble. Les tests montrent que Google crawle effectivement les pages paginées via les liens internes, sans avoir besoin du sitemap. Soyons honnêtes : la majorité des sites e-commerce avec une pagination classique voient leurs pages 2, 3, 4... indexées sans souci.
Mais — et c'est là que ça coince — cette déclaration reste vague sur les délais. "Découvre automatiquement" ne veut pas dire "indexe rapidement". [À vérifier] selon votre crawl budget et la profondeur de pagination.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Premier cas évident : la pagination infinie ou les boutons "Charger plus" en JavaScript. Si le lien vers la page suivante n'existe pas en HTML statique, Google ne peut rien découvrir automatiquement.
Deuxième cas : les sites avec un crawl budget serré. Si votre site compte des millions de pages et que Googlebot limite ses passages, miser uniquement sur le crawl naturel peut retarder l'indexation de pages profondes. Le sitemap devient alors un signal de priorisation.
Troisième cas : les architectures où la pagination est accessible via plusieurs chemins (filtres croisés, facettes multiples). La déclaration de Google suppose une structure linéaire simple — la réalité est souvent plus bordélique.
Quelle est la meilleure approche selon mon expérience ?
Concrètement ? Gardez les pages paginées dans le sitemap, même si Google dit que ce n'est pas nécessaire. Ça ne coûte rien et ça peut servir de parachute en cas de problème de crawl.
L'argument du "pas beaucoup d'avantage" ne signifie pas "désavantage". À moins d'avoir un sitemap XML gigantesque qui dépasse les limites techniques, il n'y a aucune raison de retirer ces URLs. C'est une optimisation marginale pour un gain… marginal.
Impact pratique et recommandations
Que faut-il faire concrètement avec votre pagination ?
D'abord, vérifiez que chaque page paginée contient bien un lien HTML classique vers la page suivante. Inspectez le code source — pas juste l'affichage visuel. Si le lien est généré en JS après chargement, c'est un red flag.
Ensuite, testez le crawl avec un outil comme Screaming Frog ou Sitebulb. Lancez un crawl depuis votre page 1 et vérifiez que toutes les pages paginées sont découvertes. Si certaines ne remontent pas, c'est que votre structure pose problème.
Enfin, consultez vos logs serveur. Regardez la fréquence de passage de Googlebot sur vos pages 5, 10, 20. Si le bot ne va jamais au-delà de la page 3, le sitemap peut effectivement servir à pousser ces URLs.
Quelles erreurs éviter absolument ?
Ne supprimez pas massivement vos pages paginées du sitemap sans surveillance. Cette déclaration ne justifie pas un nettoyage radical — surtout sur un gros site.
Évitez aussi de vous reposer uniquement sur le crawl naturel si votre pagination dépasse 50 pages. Au-delà, la probabilité que Google explore tout sans aide externe diminue, surtout si le crawl budget est limité.
Autre piège : croire que "découverte automatique" = "indexation garantie". Google peut très bien crawler une page paginée et décider de ne pas l'indexer (contenu dupliqué, faible valeur ajoutée). Ce sont deux étapes distinctes.
- Vérifier que chaque page paginée contient un lien HTML vers la suivante
- Tester le crawl de la pagination avec un outil dédié (Screaming Frog, Sitebulb)
- Analyser les logs serveur pour mesurer la fréquence de passage de Googlebot sur les pages profondes
- Conserver les pages paginées dans le sitemap XML par précaution, sauf contrainte technique
- Surveiller l'indexation réelle (Search Console) après toute modification de stratégie
- Ne pas confondre crawl et indexation : Google peut découvrir sans indexer
❓ Questions frequentes
Dois-je supprimer les pages paginées de mon sitemap XML ?
Et si ma pagination est gérée en JavaScript ?
Comment savoir si Google crawle bien toutes mes pages paginées ?
Faut-il utiliser rel="next" et rel="prev" pour la pagination ?
Le crawl budget peut-il limiter l'indexation de mes pages paginées ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/12/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.