Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Faut-il changer de domaine lors d'une réduction de catalogue ou conserver l'existant ?
- □ Les backlinks vers une page 404 sont-ils définitivement perdus ou récupérables ?
- □ Peut-on vraiment avoir des millions de redirections 301 sans impacter son SEO ?
- □ Faut-il vraiment ignorer les erreurs 404 dans Google Search Console ?
- □ Faut-il vraiment ajouter les pages paginées dans le sitemap XML ?
- □ Google crawle-t-il vraiment les liens dans les menus déroulants au survol ?
- □ Combien de redirections peut-on vraiment mettre sur un site sans pénalité SEO ?
- □ Faut-il privilégier une personne ou une organisation comme auteur d'un article pour le SEO ?
- □ Faut-il vraiment aligner URL, title et H1 pour ranker en SEO ?
- □ Bloquer une page de redirection par robots.txt peut-il vraiment empêcher le passage du PageRank ?
- □ Les tirets multiples dans un nom de domaine pénalisent-ils votre SEO ?
- □ Faut-il publier du contenu tous les jours pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner le texte dans les images pour le SEO ?
- □ Les Core Web Vitals écrasent-ils vraiment la pertinence dans le classement Google ?
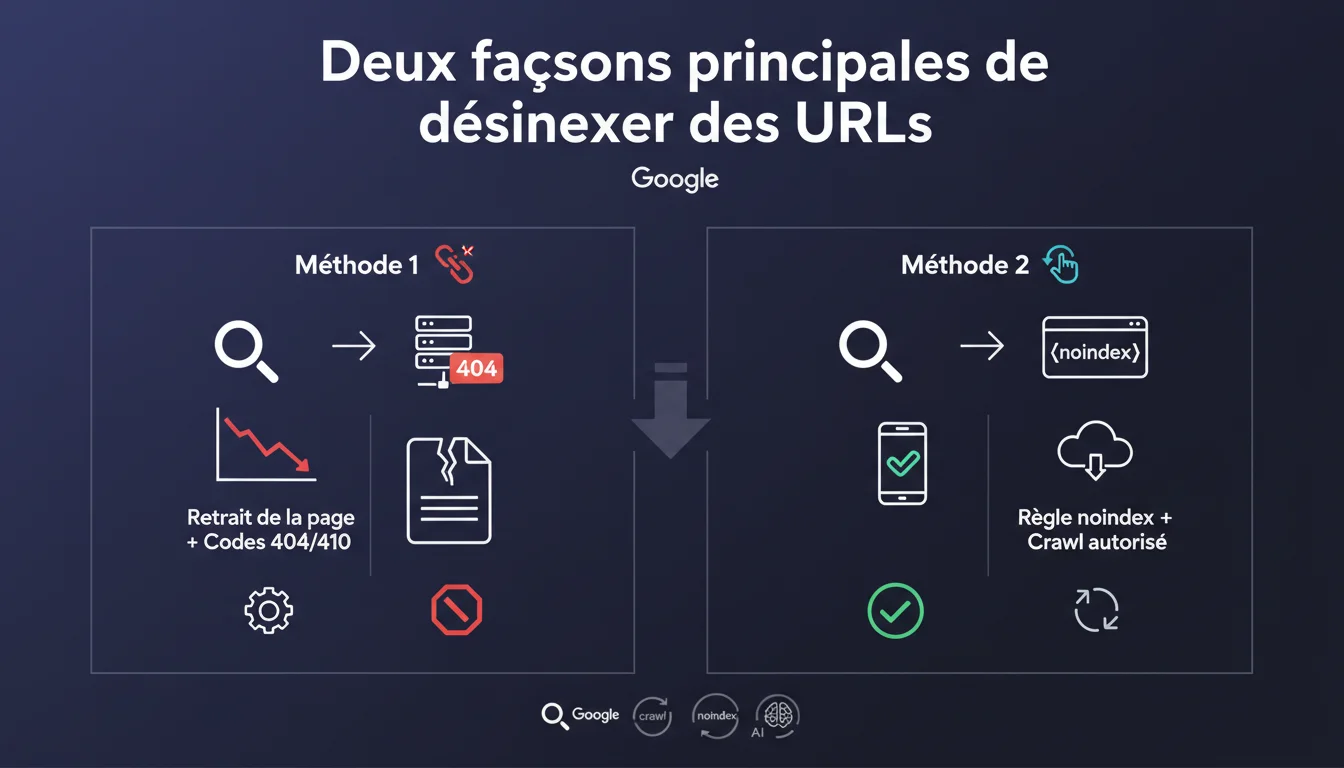
Google affirme qu'il n'existe que deux façons efficaces de désindexer des URLs : retourner un code HTTP 404/410 ou utiliser la directive noindex en permettant à Googlebot de crawler la page. Cette simplification volontaire passe sous silence d'autres méthodes techniques et soulève la question de leur efficacité réelle comparée aux deux options officiellement recommandées.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur seulement deux méthodes ?
Google cherche à simplifier la communication auprès des webmasters en réduisant le spectre des possibilités à deux options claires et maîtrisables. Cette approche pédagogique évite la confusion et les erreurs d'implémentation qui surviennent quand trop d'alternatives sont proposées.
Cependant, cette simplification occulte volontairement d'autres leviers techniques — robots.txt, balises canonical cross-domain, désindexation via Search Console, redirections 301 suivies d'une suppression. Google les considère soit comme inefficaces, soit comme des solutions de contournement qu'il préfère décourager.
Quelle est la différence fondamentale entre 404/410 et noindex ?
Le code HTTP 404 ou 410 signale une suppression définitive au niveau serveur. Googlebot comprend immédiatement que la ressource n'existe plus et retire l'URL de l'index, généralement en quelques jours selon la fréquence de crawl.
La directive noindex exige que Googlebot accède à la page (code 200) pour lire la balise meta ou l'en-tête HTTP. C'est une instruction explicite demandant de ne pas indexer le contenu, tout en permettant au crawler de suivre les liens présents sur la page. Cette nuance change tout pour le maillage interne et la transmission de PageRank.
Que se passe-t-il si on bloque le crawl d'une page en noindex ?
Soyons honnêtes : c'est une erreur classique. Bloquer via robots.txt une page contenant une directive noindex empêche Googlebot de découvrir cette instruction. Résultat ? L'URL reste potentiellement indexée avec un snippet tronqué.
Google insiste sur ce point depuis des années — et c'est la raison pour laquelle cette déclaration précise explicitement « permettre à Googlebot de crawler ces pages ». Sans accès, pas de lecture du noindex, donc pas de désindexation propre.
- 404/410 : Suppression immédiate, pas besoin d'accès au contenu
- Noindex : Nécessite un crawl pour être appliqué, préserve le crawl des liens internes
- Robots.txt : Bloque le crawl mais n'empêche pas l'indexation si des backlinks existent
- Erreur fréquente : Combiner robots.txt + noindex annule l'effet du noindex
- Timing : La désindexation via noindex peut prendre plusieurs semaines selon le crawl budget
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Globalement, oui. Les observations concordent : 404/410 et noindex sont effectivement les deux leviers les plus fiables pour désindexer du contenu de manière prévisible. Les autres méthodes génèrent souvent des résultats erratiques ou incomplets.
Mais cette simplification évacue des cas d'usage réels. La canonical cross-domain, par exemple, peut servir à désindexer en faveur d'une autre URL — même si Google ne la considère que comme une suggestion. Les redirections 301 suivies d'une suppression côté destination créent aussi une forme de désindexation progressive, quoique moins maîtrisée.
Quelles nuances faut-il apporter à cette affirmation ?
Google dit « vraiment qu'une poignée de façons » — ce qui sous-entend qu'il en existe d'autres, mais qu'elles ne sont pas recommandées ou pas aussi efficaces. C'est un choix éditorial, pas une vérité technique absolue.
Le timing de désindexation varie énormément selon la méthode. Un 410 Gone est traité plus agressivement qu'un 404 classique. Un noindex sur une page crawlée quotidiennement sera appliqué en quelques jours ; sur une page orpheline ou profonde, ça peut traîner des semaines. [A vérifier] : Google ne publie aucune métrique officielle sur les délais moyens de désindexation selon la méthode.
Dans quels cas cette règle ne suffit-elle pas ?
Les situations complexes échappent à ce cadre binaire. Imaginons un site avec des millions d'URLs générées dynamiquement — facettes, filtres, paramètres — qu'on veut désindexer sans les supprimer physiquement. Un noindex massif peut fonctionner, mais il consomme du crawl budget inutilement.
Dans ce contexte, d'autres stratégies — canonicalisation agressive, paramètres URL dans Search Console, refonte de l'architecture — deviennent indispensables. Google ne les évoque pas ici, ce qui peut induire en erreur les praticiens face à des problématiques d'indexation à grande échelle.
Impact pratique et recommandations
Que faut-il faire concrètement pour désindexer proprement ?
Choix stratégique : Si le contenu est définitivement supprimé et ne reviendra jamais, opte pour un 404 ou 410. Si le contenu existe toujours mais ne doit pas apparaître dans les résultats de recherche — espace membre, pages de conversion internes, contenus dupliqués — utilise noindex.
Vérifie que Googlebot a bien accès aux pages concernées. Consulte le fichier robots.txt et assure-toi qu'aucune directive Disallow ne bloque le chemin. Pour un noindex, le crawl doit être autorisé — c'est non négociable.
Surveille la désindexation via Search Console : requête site:tonsite.com/url-a-desindexer dans Google ou suivi des pages indexées dans le rapport de couverture. Si l'URL persiste après plusieurs semaines, creuse : backlinks externes qui maintiennent l'indexation, problème de crawl, signal mixte (canonical + noindex contradictoires).
Quelles erreurs éviter absolument ?
Ne combine jamais robots.txt + noindex sur la même URL. C'est l'erreur la plus fréquente et elle annule complètement l'effet désiré. Google ne peut pas lire une directive qu'il n'a pas le droit de crawler.
Évite de basculer un site entier en noindex « par précaution » pendant une migration ou une refonte. Ça arrive — et ça génère des catastrophes SEO. Utilise plutôt un environnement de staging avec authentification HTTP ou un sous-domaine bloqué via robots.txt.
Ne compte pas sur une redirection 301 seule pour désindexer. La redirection transfère le PageRank et signale un déplacement, mais l'URL source peut rester indexée si la destination retourne elle-même un code d'erreur ou si la chaîne de redirections est cassée.
Comment vérifier que mon site respecte ces bonnes pratiques ?
- Audite ton fichier robots.txt : aucune directive Disallow ne doit bloquer les URLs en noindex
- Vérifie les en-têtes HTTP des pages à désindexer : code 404/410 ou 200 + noindex, jamais de mixte incohérent
- Consulte le rapport de couverture dans Search Console : identifie les URLs "Exclues par la balise noindex" vs "Introuvables (404)"
- Scanne les backlinks externes pointant vers les URLs à désindexer — ils peuvent ralentir ou empêcher le retrait
- Teste avec un crawler (Screaming Frog, OnCrawl) pour repérer les incohérences entre directives
- Documente la stratégie de désindexation : quelle méthode pour quel type de contenu, pour éviter les erreurs en équipe
❓ Questions frequentes
Peut-on utiliser robots.txt pour désindexer des URLs ?
Quelle différence entre un code 404 et un code 410 ?
Combien de temps faut-il pour qu'une URL en noindex soit désindexée ?
Faut-il supprimer les backlinks vers une page désindexée ?
Peut-on combiner noindex et canonical sur la même page ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/12/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.