Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Googlebot ignore-t-il vraiment le scroll et les interactions utilisateur ?
- □ Le DOM du navigateur reflète-t-il vraiment ce que Google indexe ?
- □ Les DevTools suffisent-ils vraiment pour déboguer vos problèmes SEO techniques ?
- □ Pourquoi les en-têtes de réponse HTTP sont-ils cruciaux pour votre référencement ?
- □ Pourquoi le diagramme en cascade de vos ressources révèle-t-il vos vrais problèmes de performance ?
- □ Pourquoi Google vérifie-t-il la présence du contenu dans le DOM plutôt que dans le HTML brut ?
- □ Faut-il vraiment bannir le lazy loading et le scroll infini pour être indexé par Google ?
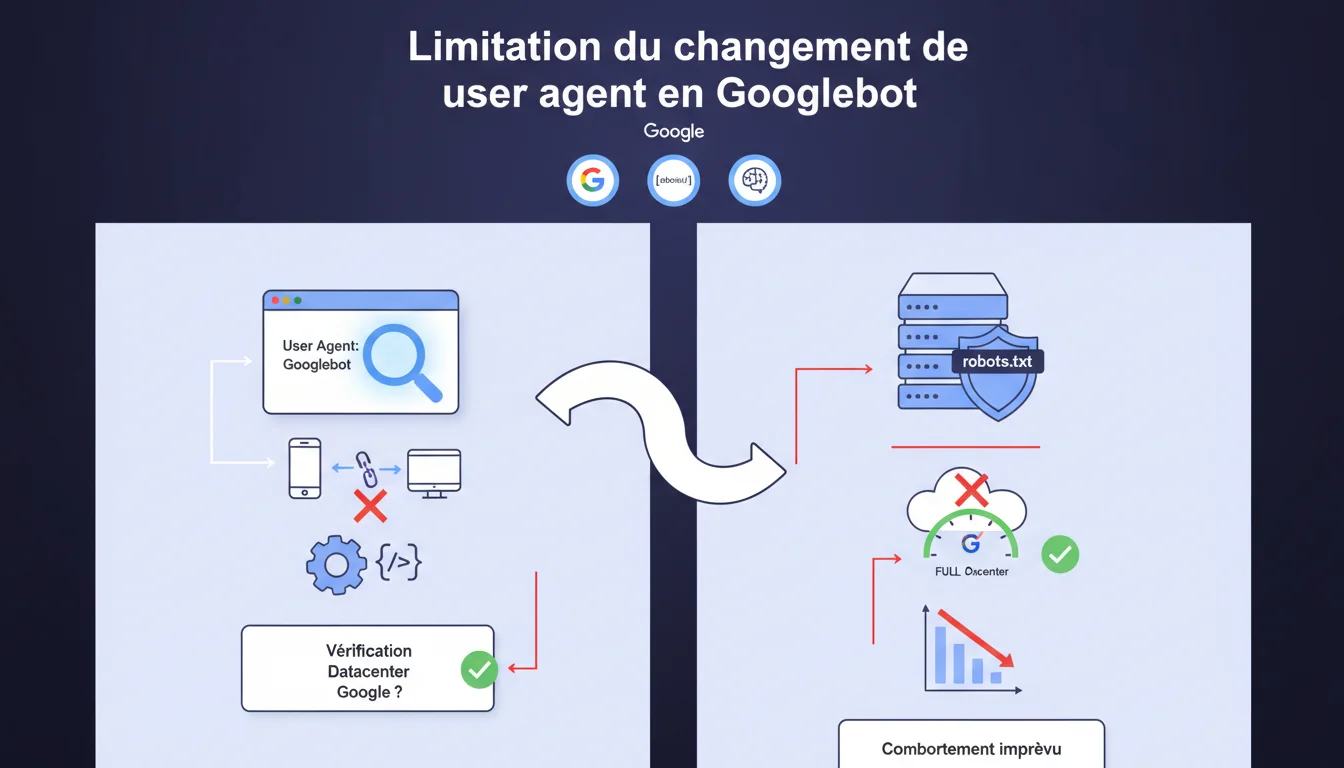
Modifier manuellement le user agent de votre navigateur pour imiter Googlebot ne reproduit pas fidèlement le comportement réel du crawler. Googlebot respecte le robots.txt et provient d'adresses IP vérifiables dans les datacenters Google — deux éléments qu'un simple changement de user agent ne peut simuler. Cette technique de test reste donc limitée et trompeuse pour diagnostiquer le rendu ou l'accès des pages.
Ce qu'il faut comprendre
Pourquoi vouloir simuler Googlebot dans un navigateur ?
Nombreux sont les SEO qui changent le user agent de leur navigateur pour imiter Googlebot, espérant voir exactement ce que le crawler voit. L'idée ? Détecter rapidement si une page bloque le bot, affiche un contenu différent (cloaking), ou rencontre des problèmes de rendu JavaScript.
Cette pratique repose sur l'hypothèse qu'un simple changement de chaîne user agent suffit à reproduire le comportement de Googlebot. Mais Google rappelle ici que cette approche est incomplète — et potentiellement trompeuse.
Quelles sont les limites techniques de cette simulation ?
Premier écueil : le robots.txt. Votre navigateur, même avec un user agent modifié, ignore totalement ce fichier. Googlebot, lui, le respecte strictement. Si une directive bloque l'accès à certaines ressources CSS ou JS, votre navigateur les chargera quand même — faussant le diagnostic.
Deuxième problème : la vérification IP. Certains sites vérifient que les requêtes prétendant venir de Googlebot proviennent effectivement d'un datacenter Google. Un reverse DNS lookup ou une vérification via les plages IP publiées par Google permettent de démasquer les imposteurs. Votre navigateur, lui, vient de votre FAI.
- Googlebot respecte le robots.txt, pas votre navigateur — les ressources bloquées ne seront pas visibles pour le bot
- Les sites peuvent vérifier l'IP source via reverse DNS pour authentifier Googlebot
- Un simple changement de user agent ne simule ni l'infrastructure ni le comportement complet du crawler
- Cette technique peut donner un faux sentiment de sécurité sur l'accessibilité réelle des pages
Dans quels cas cette méthode peut-elle quand même servir ?
Malgré ses limites, changer le user agent reste utile pour des tests rapides et superficiels. Vous pouvez détecter un cloaking grossier basé uniquement sur la chaîne user agent, ou vérifier si une page affiche un message d'erreur spécifique aux bots.
Mais ne comptez pas sur cette méthode pour diagnostiquer des problèmes d'indexation liés au robots.txt, au JavaScript, ou à des restrictions IP. Pour ça, Google Search Console et l'outil d'inspection d'URL restent indispensables.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Absolument. Les SEO expérimentés savent depuis longtemps que le simple changement de user agent est une béquille, pas une vraie solution de test. Les cas où ça coince concernent souvent des ressources bloquées par robots.txt (polices, scripts tiers) que le navigateur charge sans souci.
Côté vérification IP, certains sites e-commerce ou médias bloquent effectivement les faux Googlebots pour se protéger du scraping. Ils utilisent des solutions comme Cloudflare ou des scripts maison qui croisent user agent et adresse IP. Dans ces configurations, votre navigateur ne passera jamais pour Googlebot — même avec le bon user agent.
Quelles nuances faut-il apporter à ce message de Google ?
Google ne dit pas que changer le user agent est inutile, mais qu'il ne faut pas en attendre une simulation fidèle. Nuance importante : cette technique reste valable pour des vérifications basiques, mais elle devient trompeuse si vous vous basez sur elle pour valider l'accessibilité complète d'une page.
Un point que Google n'aborde pas : le rendu JavaScript. Même avec le bon user agent, votre navigateur peut exécuter le JS différemment de Googlebot selon la version de Chrome utilisée, les extensions actives, ou les capacités matérielles. [A vérifier] dans chaque contexte spécifique.
Quelle est la meilleure alternative pour tester comme Googlebot ?
L'outil d'inspection d'URL dans Google Search Console reste la référence. Il sollicite réellement Googlebot, respecte le robots.txt, et vous montre exactement ce que le crawler voit — rendu inclus. C'est la seule méthode 100 % fiable.
Pour les tests en volume ou automatisés, des outils comme Screaming Frog peuvent simuler Googlebot de manière plus complète (respect du robots.txt, options de rendering). Mais rien ne remplace un test réel via GSC pour valider l'indexabilité d'une page stratégique.
Impact pratique et recommandations
Que faut-il faire concrètement pour tester l'accessibilité de vos pages ?
Privilégiez Google Search Console et l'outil d'inspection d'URL pour tout diagnostic sérieux. Vous aurez accès au rendu réel, aux ressources bloquées, et aux erreurs JavaScript rencontrées par Googlebot.
Si vous devez quand même changer le user agent dans votre navigateur (pour un test rapide), gardez en tête que le résultat ne sera qu'indicatif. Croisez-le avec d'autres sources : logs serveur, GSC, outils tiers.
Quelles erreurs éviter lors de vos tests de crawlabilité ?
Ne vous basez jamais uniquement sur un changement de user agent pour valider qu'une page est accessible à Googlebot. Vérifiez toujours le robots.txt — manuellement ou via un outil — pour identifier les ressources bloquées.
Évitez aussi de tester depuis votre réseau local si votre site applique des restrictions géographiques ou IP. Utilisez un VPN ou un serveur distant pour simuler un accès externe.
- Utilisez Google Search Console pour inspecter les pages critiques et voir le rendu réel de Googlebot
- Vérifiez le robots.txt pour identifier les ressources bloquées (CSS, JS, images)
- Croisez les résultats avec les logs serveur pour confirmer les requêtes réelles de Googlebot
- Ne vous fiez pas au seul user agent pour diagnostiquer des problèmes d'indexation
- Testez le rendu JavaScript via l'outil d'inspection d'URL ou des solutions tierces (Screaming Frog, OnCrawl)
- Si votre site vérifie les IP, assurez-vous que les plages Google ne sont pas bloquées par erreur
❓ Questions frequentes
Puis-je quand même utiliser le changement de user agent pour tester mes pages ?
Comment un site peut-il vérifier que la requête vient vraiment de Googlebot ?
Googlebot respecte-t-il systématiquement le robots.txt, même pour l'indexation ?
Quels outils permettent de simuler Googlebot plus fidèlement qu'un simple changement de user agent ?
Si mon site bloque les faux Googlebots par IP, est-ce pénalisant pour le SEO ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.