Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Googlebot ignore-t-il vraiment le scroll et les interactions utilisateur ?
- □ Le DOM du navigateur reflète-t-il vraiment ce que Google indexe ?
- □ Les DevTools suffisent-ils vraiment pour déboguer vos problèmes SEO techniques ?
- □ Pourquoi les en-têtes de réponse HTTP sont-ils cruciaux pour votre référencement ?
- □ Pourquoi usurper le user agent de Googlebot dans votre navigateur ne sert à rien ?
- □ Pourquoi le diagramme en cascade de vos ressources révèle-t-il vos vrais problèmes de performance ?
- □ Pourquoi Google vérifie-t-il la présence du contenu dans le DOM plutôt que dans le HTML brut ?
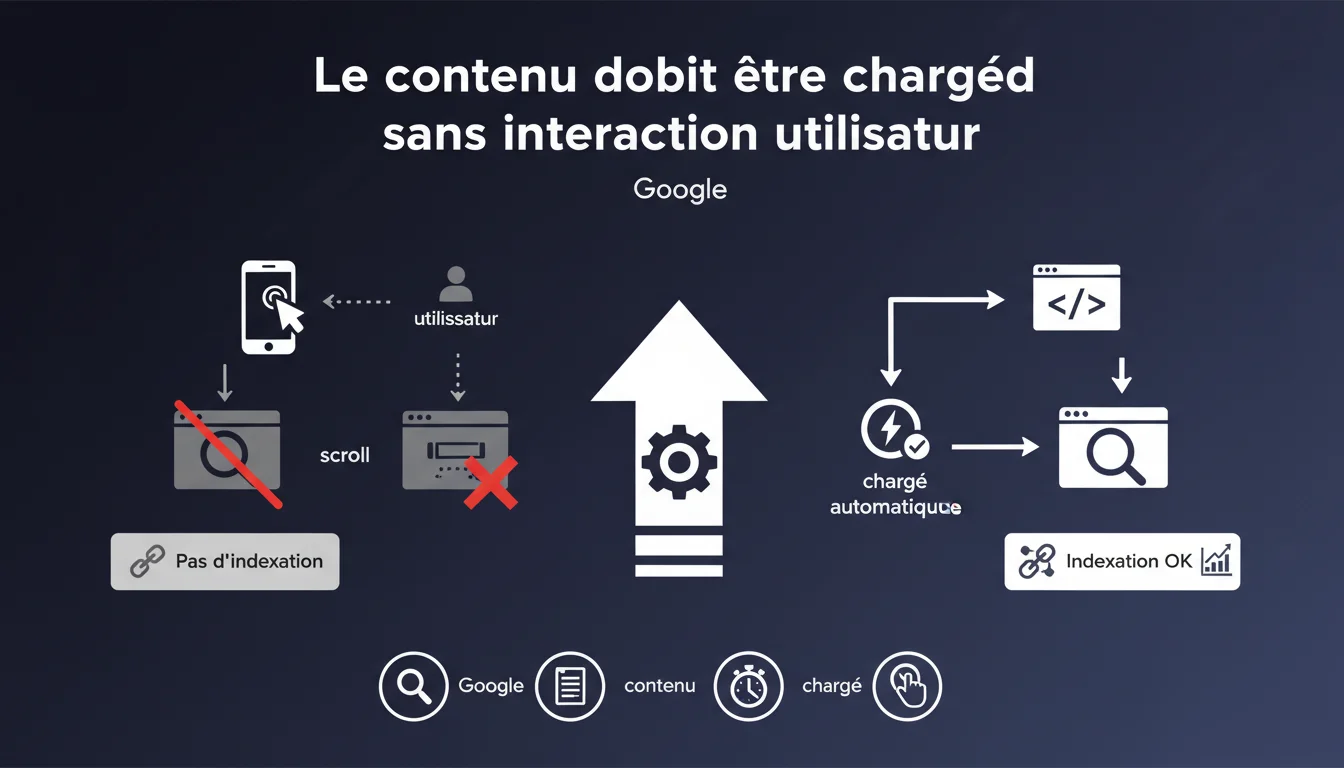
Google affirme que Googlebot ne peut indexer que le contenu chargé sans interaction utilisateur comme le scroll. Autrement dit : exit le lazy loading classique, exit le scroll infini — sauf si vous trouvez une alternative technique qui rend le contenu accessible au bot. Pour les sites riches en contenus dynamiques, c'est une contrainte technique majeure.
Ce qu'il faut comprendre
Cette déclaration rappelle une limite technique fondamentale de Googlebot : il ne scrolle pas, ne clique pas, et n'interagit pas avec la page comme un humain. Si votre contenu nécessite un défilement pour se charger (lazy loading déclenché au scroll, pagination infinie), Googlebot ne le verra probablement jamais.
Le problème concerne surtout les sites qui misent sur des techniques JavaScript modernes pour optimiser la performance côté utilisateur. Ce qui améliore l'expérience peut paradoxalement nuire à l'indexation.
Pourquoi cette limitation existe-t-elle encore ?
Googlebot exécute du JavaScript — certes — mais il ne simule pas un comportement humain complet. Pas de scroll, pas de clic sur des boutons "Charger plus", pas d'attente prolongée pour voir si du contenu supplémentaire apparaît.
Cette approche limite drastiquement les ressources serveur nécessaires pour crawler des milliards de pages. Simuler une interaction humaine complète sur chaque URL serait techniquement ruineux pour Google.
Quels types de contenu sont concernés ?
Les galeries d'images en lazy loading, les listes de produits qui se chargent au fur et à mesure du scroll, les commentaires ou avis chargés dynamiquement, les articles de blog en pagination infinie. Toute zone de contenu dont le rendu dépend d'une action utilisateur.
Et c'est là que ça coince pour beaucoup de frameworks front-end modernes (React, Vue, Next.js) qui implémentent ces patterns par défaut.
Quelle est la position officielle de Google sur ce sujet ?
Google demande aux développeurs de trouver une alternative technique pour charger ce contenu de manière accessible à Googlebot. Aucune directive précise sur comment y parvenir — juste l'impératif : "débrouillez-vous".
- Googlebot n'interagit pas avec les pages comme un utilisateur
- Le contenu chargé au scroll ou au clic est invisible au bot
- Les frameworks JavaScript modernes créent souvent ce problème par défaut
- Une solution technique existe — mais Google ne la détaille pas ici
- C'est aux développeurs de rendre leur contenu accessible au crawl
Avis d'un expert SEO
Cette règle est-elle vraiment aussi stricte dans la pratique ?
Soyons honnêtes : Google a fait d'énormes progrès dans l'exécution JavaScript. Mais cette déclaration rappelle que ces progrès ont des limites claires. Le lazy loading "standard" — celui qui attend un événement scroll — reste un angle mort pour Googlebot.
Ce qui surprend, c'est que Google continue de promouvoir le lazy loading pour les images (notamment via l'attribut loading="lazy") tout en affirmant qu'il faut éviter le contenu chargé au scroll. Cette apparente contradiction mérite clarification. [A vérifier]
Les observations terrain confirment-elles cette déclaration ?
Oui — et non. Sur des sites avec pagination infinie, on observe effectivement que seul le contenu du premier "écran" est indexé. Les produits ou articles suivants, chargés au scroll, disparaissent de l'index.
Mais certains sites semblent contourner ce problème sans modification technique visible. Pourquoi ? Mystère. Soit Google a des exceptions non documentées, soit ces sites utilisent des techniques de pre-rendering invisibles à l'analyse superficielle.
Quelles nuances faut-il apporter à cette règle ?
La déclaration parle d'"interaction utilisateur" au sens large. Mais il existe des techniques pour charger du contenu dynamique sans interaction : Intersection Observer API avec chargement automatique dès que l'élément entre dans le viewport virtuel, Server-Side Rendering (SSR), Static Site Generation (SSG), hydratation progressive.
Le vrai problème n'est pas le JavaScript en soi, mais le déclencheur de chargement. Si le contenu se charge automatiquement au premier rendu — même via JS — Googlebot devrait le voir. Si ça nécessite un événement scroll, clic ou hover, game over.
Impact pratique et recommandations
Que faut-il faire concrètement sur un site existant ?
Première étape : auditer les zones à risque. Identifiez tout contenu chargé au scroll, en pagination infinie, ou derrière un bouton "Voir plus". Testez ensuite avec l'outil d'inspection d'URL de la Search Console pour voir ce que Googlebot récupère réellement.
Deuxième étape : implémenter une solution technique viable. Les options classiques : SSR complet, génération statique, ou fallback en HTML pur pour le contenu critique. Pour les sites e-commerce, ça peut signifier remplacer le scroll infini par une pagination traditionnelle avec liens cliquables.
Quelles erreurs éviter absolument ?
Ne comptez pas sur le fait que "Google crawle du JavaScript maintenant donc c'est bon". Oui, il crawle du JS — mais avec des contraintes strictes. Le lazy loading au scroll reste un angle mort confirmé.
Autre erreur fréquente : tester uniquement avec Chrome en mode développeur. Ce n'est pas parce que ça s'affiche correctement dans votre navigateur que Googlebot voit la même chose. Utilisez systématiquement la Search Console ou des outils comme Screaming Frog en mode "rendu JavaScript".
Comment vérifier que votre site est conforme ?
Utilisez l'outil Test d'URL de la Search Console sur vos pages critiques. Comparez le HTML rendu avec ce que vous voyez dans le navigateur. Si des sections manquent dans la version Googlebot, vous avez un problème.
Complétez avec un crawl Screaming Frog ou OnCrawl en mode rendu JavaScript. Vérifiez que le contenu important apparaît bien dans le DOM crawlé, sans nécessiter d'interaction.
- Auditer toutes les implémentations de lazy loading et scroll infini
- Tester chaque type de page avec l'outil d'inspection Search Console
- Comparer le rendu Googlebot vs rendu navigateur standard
- Remplacer le scroll infini par une pagination classique avec liens
- Implémenter du SSR ou SSG pour les pages critiques
- Documenter les zones où le contenu dynamique reste nécessaire
- Monitorer l'indexation après chaque modification technique
Cette contrainte technique peut sembler simple en théorie, mais sa mise en œuvre sur un site complexe — particulièrement e-commerce ou média — nécessite souvent des arbitrages délicats entre performance, expérience utilisateur et indexation. Si vous n'avez pas d'expertise approfondie en rendu JavaScript et architecture front-end, ces optimisations peuvent rapidement devenir un casse-tête. Pour garantir une implémentation conforme sans sacrifier la performance, faire appel à une agence SEO spécialisée en SEO technique peut s'avérer judicieux — surtout si votre business dépend fortement du trafic organique.
❓ Questions frequentes
Le lazy loading d'images pose-t-il aussi problème pour Googlebot ?
Le Server-Side Rendering (SSR) résout-il définitivement ce problème ?
Peut-on garder le scroll infini pour l'UX et ajouter une pagination cachée pour les bots ?
Les sites qui utilisent du scroll infini et sont bien indexés font comment ?
L'Intersection Observer API peut-elle contourner cette limitation ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.