Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Le DOM du navigateur reflète-t-il vraiment ce que Google indexe ?
- □ Les DevTools suffisent-ils vraiment pour déboguer vos problèmes SEO techniques ?
- □ Pourquoi les en-têtes de réponse HTTP sont-ils cruciaux pour votre référencement ?
- □ Pourquoi usurper le user agent de Googlebot dans votre navigateur ne sert à rien ?
- □ Pourquoi le diagramme en cascade de vos ressources révèle-t-il vos vrais problèmes de performance ?
- □ Pourquoi Google vérifie-t-il la présence du contenu dans le DOM plutôt que dans le HTML brut ?
- □ Faut-il vraiment bannir le lazy loading et le scroll infini pour être indexé par Google ?
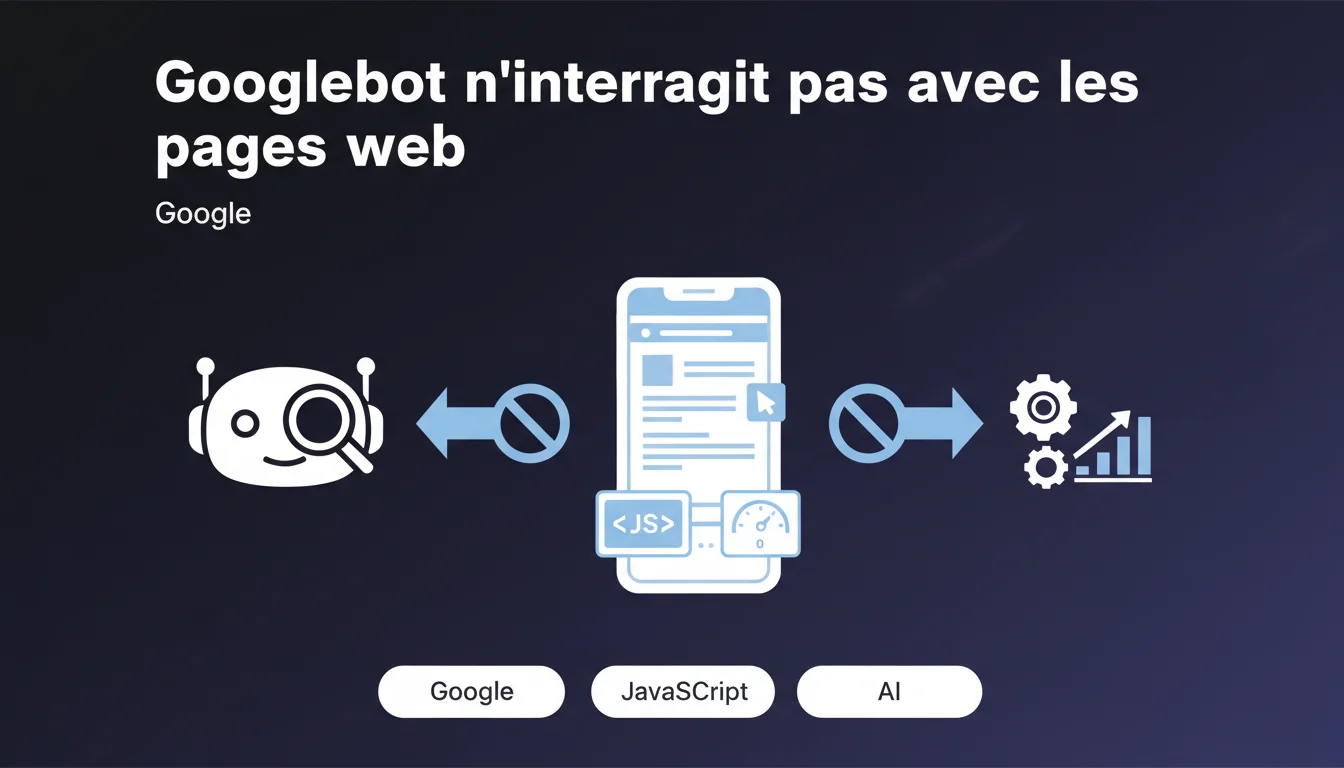
Googlebot n'interagit pas avec les pages web : pas de clic, pas de scroll, pas d'événements utilisateur. Le JavaScript qui dépend du scroll ou d'autres interactions ne sera donc jamais exécuté lors du crawl. Vos contenus lazy-loadés au scroll risquent tout simplement d'être invisibles pour Google.
Ce qu'il faut comprendre
Cette déclaration de Google met les points sur les i : Googlebot se comporte comme un visiteur passif. Il charge la page, exécute le JavaScript initial, mais ne simule aucune action humaine.
Concrètement, si votre site charge des contenus additionnels uniquement quand l'utilisateur scrolle ou clique, ces éléments n'existent tout simplement pas pour le moteur. C'est un point technique critique, souvent négligé lors de la mise en œuvre d'optimisations de performance.
Pourquoi Google a-t-il besoin de préciser cela maintenant ?
Parce que les frameworks JavaScript modernes (React, Vue, Next.js) encouragent le lazy-loading et les interactions dynamiques pour améliorer les performances perçues. Ce qui est excellent pour l'utilisateur peut devenir problématique pour l'indexation.
Google essaie depuis des années de crawler et indexer correctement le JavaScript. Mais cette déclaration rappelle une limite fondamentale : le bot n'a ni le temps ni les ressources pour simuler un comportement utilisateur complet sur chaque page crawlée.
Qu'est-ce qui déclenche réellement l'exécution du JavaScript par Googlebot ?
Googlebot exécute le JS qui se déclenche au chargement de la page — les scripts qui tournent automatiquement via DOMContentLoaded ou window.onload. Tout ce qui nécessite une interaction (scroll, hover, click) reste invisible.
La nuance importante : si votre JavaScript charge du contenu via une requête automatique (fetch au load, pas au scroll), Google le verra. C'est le déclencheur qui compte, pas la technologie.
- Googlebot charge la page et attend que le JavaScript initial s'exécute
- Aucun événement utilisateur n'est simulé (scroll, click, hover, resize)
- Le contenu lazy-loadé au scroll ne sera pas découvert ni indexé
- Seul le JavaScript qui s'exécute automatiquement au chargement est pris en compte
Avis d'un expert SEO
Cette règle s'applique-t-elle vraiment dans tous les cas ?
Soyons honnêtes : Google a parfois des comportements contradictoires. On observe régulièrement des cas où du contenu lazy-loadé semble quand même indexé. Mais il faut comprendre le mécanisme.
Si votre lazy-loading utilise Intersection Observer avec un seuil généreux (rootMargin élevé), le contenu peut se charger automatiquement sans scroll réel. Google voit alors le DOM final. Ce n'est pas que le bot scrolle — c'est que votre code charge le contenu de manière suffisamment anticipée.
Où cette déclaration manque-t-elle de précision ?
Google reste vague sur un point crucial : combien de temps le bot attend-il que le JavaScript s'exécute ? La réponse officielle parle de « quelques secondes », mais c'est insuffisant comme information.
En pratique, si votre JS met plus de 5 secondes à charger du contenu critique, vous êtes probablement dans la zone rouge. [A vérifier] Aucune donnée officielle ne confirme ce seuil — c'est une observation empirique basée sur des tests terrain.
Cette limitation est-elle cohérente avec la stratégie de Google ?
Totalement. Google pousse depuis des années pour le Server-Side Rendering (SSR) ou la génération statique. Cette déclaration confirme que miser uniquement sur un rendu client avec lazy-loading au scroll est risqué pour le SEO.
Le message sous-jacent : si votre contenu compte pour le référencement, il doit être présent dans le HTML initial ou chargé automatiquement au load. Pas de négociation.
Impact pratique et recommandations
Comment identifier les contenus invisibles pour Googlebot ?
Première étape : auditez vos scripts qui dépendent d'événements. Recherchez dans votre code les listeners sur scroll, click, hover, resize. Tout contenu chargé via ces déclencheurs est potentiellement invisible.
Utilisez la Search Console et comparez le HTML rendu dans l'outil d'inspection avec ce que vous voyez dans le source de la page (Ctrl+U). Si des différences majeures apparaissent, vous avez un problème d'indexation du contenu dynamique.
Quelles modifications techniques appliquer en priorité ?
Pour le contenu critique : chargez-le automatiquement au load, pas au scroll. Si vous utilisez Intersection Observer pour le lazy-loading, configurez un rootMargin généreux (par exemple 200-300px) pour anticiper le chargement.
Pour les images : utilisez l'attribut loading="lazy" natif du navigateur uniquement pour les images en dessous de la ligne de flottaison. Les images critiques (above the fold) doivent se charger normalement.
Envisagez une approche hybride avec du Server-Side Rendering pour le contenu essentiel et du client-side pour les éléments secondaires. Next.js, Nuxt ou Gatsby facilitent cette architecture.
- Identifiez tous les scripts déclenchés par scroll ou click dans votre code
- Déplacez le chargement du contenu critique vers le load automatique
- Testez le rendu dans la Search Console après modifications
- Vérifiez que le HTML source contient vos contenus stratégiques
- Ajustez les seuils d'Intersection Observer si vous l'utilisez
- Privilégiez le SSR ou la génération statique pour les pages à fort enjeu SEO
❓ Questions frequentes
Le lazy-loading d'images est-il également impacté par cette limitation ?
L'outil d'inspection d'URL reflète-t-il le comportement réel de Googlebot ?
Les infinite scroll sont-ils condamnés pour le SEO ?
Dois-je abandonner React ou Vue pour mon SEO ?
Comment tester si mon contenu JavaScript est bien crawlé ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.