Declaration officielle
Autres déclarations de cette vidéo 7 ▾
- □ Googlebot ignore-t-il vraiment le scroll et les interactions utilisateur ?
- □ Le DOM du navigateur reflète-t-il vraiment ce que Google indexe ?
- □ Les DevTools suffisent-ils vraiment pour déboguer vos problèmes SEO techniques ?
- □ Pourquoi les en-têtes de réponse HTTP sont-ils cruciaux pour votre référencement ?
- □ Pourquoi usurper le user agent de Googlebot dans votre navigateur ne sert à rien ?
- □ Pourquoi Google vérifie-t-il la présence du contenu dans le DOM plutôt que dans le HTML brut ?
- □ Faut-il vraiment bannir le lazy loading et le scroll infini pour être indexé par Google ?
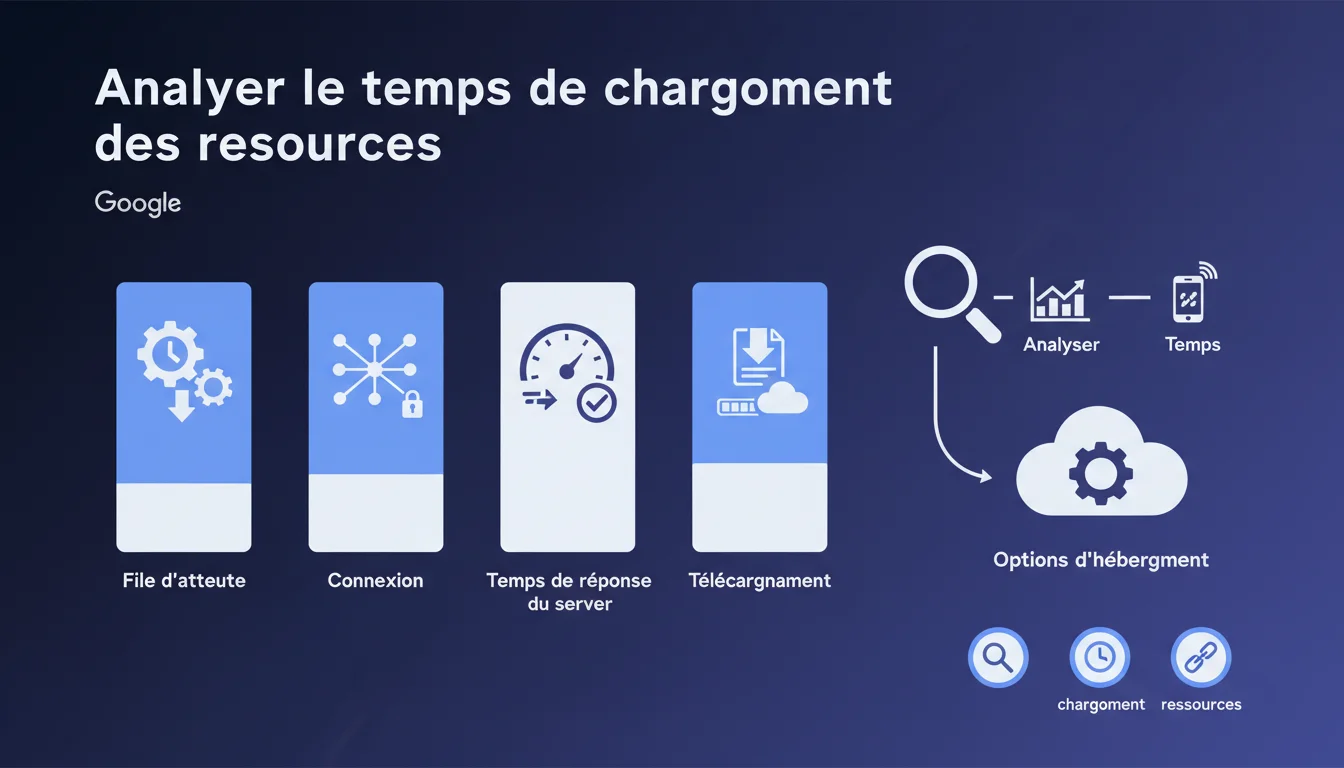
Google insiste sur l'analyse du waterfall dans l'onglet Network des DevTools pour identifier où le temps de chargement se perd réellement : file d'attente, connexion, TTFB ou téléchargement. Des latences anormales sur la connexion ou le download signalent souvent un problème d'hébergement à corriger en priorité.
Ce qu'il faut comprendre
Que révèle concrètement un diagramme en cascade ?
Le waterfall chart décompose chaque requête HTTP en phases distinctes : mise en file d'attente (queueing), établissement de la connexion (TCP + SSL/TLS), temps de réponse du serveur (TTFB), puis téléchargement effectif de la ressource. Cette granularité permet de diagnostiquer précisément où le délai s'accumule.
Un JS de 500 Ko qui met 3 secondes à charger peut souffrir d'un TTFB de 2 secondes (serveur lent) ou d'un download de 2,8 secondes (bande passante insuffisante). Les solutions ne sont pas les mêmes selon le goulot d'étranglement identifié.
Quelles étapes chronophages doivent alerter ?
Google pointe explicitement deux indicateurs : des temps de connexion longs (plusieurs centaines de millisecondes) et des temps de téléchargement excessifs. Le premier révèle souvent une latence réseau élevée entre l'utilisateur et le serveur — typique d'un hébergement sans CDN ou géographiquement mal positionné.
Le second traduit une limitation de débit côté serveur ou une compression insuffisante (GZIP/Brotli). Si le TTFB reste correct mais que le téléchargement traîne, c'est la bande passante ou la configuration du serveur web qui bride les performances.
Pourquoi Google mentionne-t-il « différentes options d'hébergement » ?
Cette formulation volontairement floue couvre plusieurs leviers : passer d'un hébergement mutualisé saturé à un VPS ou serveur dédié, adopter un CDN pour réduire la latence géographique, ou migrer vers un provider offrant de meilleures garanties réseau (peering, backbone).
L'implication est claire : si le waterfall montre systématiquement des phases de connexion ou download longues sur plusieurs ressources critiques, votre infrastructure est en cause — pas seulement votre code ou votre cache navigateur.
- Le waterfall décompose chaque requête en queueing, connexion, TTFB et download
- Des temps de connexion élevés signalent latence réseau ou absence de CDN
- Des temps de téléchargement longs indiquent bande passante limitée ou compression absente
- Google suggère de revoir l'hébergement si ces phases sont chroniquement lentes
- Le waterfall est accessible dans l'onglet Network des DevTools
Avis d'un expert SEO
Cette recommandation correspond-elle aux diagnostics terrain ?
Absolument. Le waterfall reste l'outil de première ligne pour tout audit de performance sérieux. Les outils synthétiques (PageSpeed Insights, Lighthouse) donnent un score global, mais le waterfall montre où l'argent se perd. Sur des milliers d'audits, les TTFB >600 ms et les downloads traînant sur des CSS/JS non compressés figurent parmi les causes les plus fréquentes de mauvais Core Web Vitals.
Ce qui est moins dit : un waterfall propre ne garantit pas forcément un bon LCP si les ressources critiques ne sont pas priorisées. Google se concentre ici sur l'infrastructure, mais le séquencement des requêtes (preload, fetchpriority, order d'inclusion) pèse tout autant.
Faut-il systématiquement changer d'hébergeur si les temps de connexion sont longs ?
Pas toujours. Avant de migrer, vérifiez trois points : HTTP/2 ou HTTP/3 activé (réduit les coûts de connexion multiples), Keep-Alive correctement configuré (évite de renégocier TCP/SSL à chaque requête), et présence d'un CDN avec des PoP proches de votre audience.
Un hébergement mutualisé OVH à 5€/mois peut suffire si un CDN (Cloudflare, BunnyCDN) gère les assets statiques. En revanche, si le HTML initial (document root) affiche un TTFB >800 ms même après optimisation cache serveur, là oui, l'infra est probablement sous-dimensionnée.
Quels pièges guettent l'analyse du waterfall ?
Premier piège : confondre temps total et temps bloquant. Une ressource qui met 2 secondes à charger mais qui est en async/defer n'impacte pas le LCP si elle n'est pas critique. Le waterfall ne dit pas quelles ressources sont prioritaires — il faut croiser avec le Critical Request Chains de Lighthouse.
Deuxième piège : tester depuis un DevTools local sur une connexion fibre 1 Gb/s. Les temps de download seront artificiellement bas. Utilisez le throttling (Fast 3G, Slow 4G) ou des tests RUM réels pour capturer l'expérience utilisateur médiane.
Impact pratique et recommandations
Comment identifier rapidement les ressources problématiques dans le waterfall ?
Ouvrez l'onglet Network des DevTools (F12), rechargez la page avec cache désactivé (Ctrl+Shift+R), puis triez les requêtes par colonne Time décroissant. Isolez les 5-10 ressources les plus lentes et examinez leur waterfall individuel.
Pour chacune, notez quelle phase consomme le plus de temps. Si c'est le Waiting (TTFB), le serveur met trop de temps à générer ou servir la ressource. Si c'est Content Download, la ressource est trop lourde ou la bande passante insuffisante. Si c'est Initial connection, la latence réseau est en cause.
Quelles actions concrètes selon le goulot identifié ?
TTFB élevé : Activez le cache serveur (Varnish, Redis, Memcached si dynamique), passez en cache navigateur agressif pour les assets statiques, ou optimisez les requêtes DB si le backend est le frein. Sur WordPress, un plugin de cache (WP Rocket, LiteSpeed Cache) peut diviser le TTFB par 10.
Temps de connexion long : Implémentez un CDN pour servir les assets depuis des PoP géographiquement proches. Vérifiez que HTTP/2 minimum est activé (HTTP/3 si possible). Réduisez le nombre de domaines tiers pour limiter les négociations TCP/SSL multiples.
Download lent : Compressez tous les assets textuels avec Brotli niveau 6+ (ou GZIP niveau 9 minimum). Minifiez CSS/JS, convertissez les images en WebP/AVIF, et activez le lazy-loading sur les images sous la ligne de flottaison.
- Trier les requêtes par Time dans l'onglet Network pour identifier les 10 plus lentes
- Vérifier que HTTP/2 (minimum) et Keep-Alive sont activés côté serveur
- Activer Brotli ou GZIP sur tous les assets textuels (HTML, CSS, JS, JSON, SVG)
- Implémenter un CDN si les temps de connexion dépassent 150 ms pour l'audience cible
- Utiliser le throttling réseau des DevTools pour tester en conditions réalistes (Fast 3G, Slow 4G)
- Comparer les waterfalls depuis plusieurs localisations géographiques (WebPageTest multi-régions)
- Monitorer le TTFB en production via RUM (Real User Monitoring) pour détecter les régressions
❓ Questions frequentes
Le waterfall des DevTools Chrome diffère-t-il de celui de Firefox ou Safari ?
Quel est le seuil acceptable pour un temps de connexion dans le waterfall ?
Un TTFB élevé impacte-t-il directement le LCP ?
Comment interpréter une phase de queueing longue dans le waterfall ?
Faut-il analyser le waterfall sur mobile ou desktop en priorité ?
🎥 De la même vidéo 7
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/02/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.