Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Le balisage FAQ Schema impose-t-il un format strict de présentation ?
- □ Le balisage FAQ Schema garantit-il vraiment l'affichage des FAQ snippets dans Google ?
- □ Faut-il vraiment éviter de dupliquer son propre contenu pour le SEO ?
- □ Pourquoi Google pénalise-t-il les variations excessives d'un même contenu ?
- □ Comment vérifier si Googlebot voit vraiment votre contenu JavaScript ?
- □ WordPress pénalise-t-il vraiment le référencement par rapport au HTML statique ?
- □ Pourquoi vos pages ne sont-elles pas indexées malgré un site techniquement irréprochable ?
- □ Pourquoi les études utilisateurs externes sont-elles devenues incontournables pour résoudre les problèmes de qualité ?
- □ Faut-il vraiment faire confiance au rel=canonical pour contrôler l'indexation ?
- □ Les backlinks vers des 404 sont-ils vraiment perdus pour le SEO ?
- □ Le disavow tool efface-t-il vraiment toute trace des liens toxiques dans les algorithmes Google ?
- □ Un certificat SSL peut-il vraiment pénaliser votre référencement ?
- □ Une baisse progressive multi-domaines révèle-t-elle un problème de qualité plutôt que technique ?
- □ Les problèmes techniques SEO ont-ils vraiment un impact immédiat sur vos rankings ?
- □ Bloquer Google Translate impacte-t-il vraiment votre référencement ?
- □ La balise meta notranslate peut-elle vraiment bloquer le lien « Traduire cette page » dans les SERP Google ?
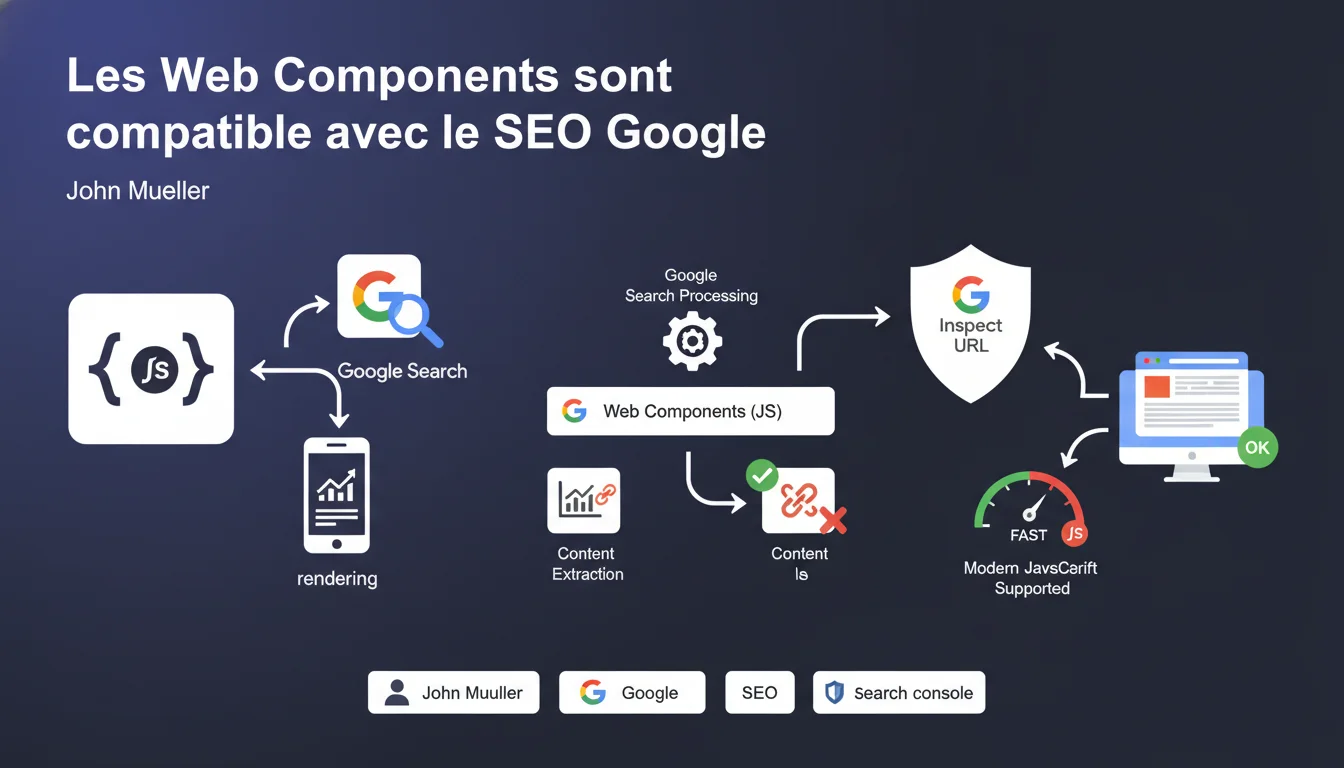
Google affirme traiter les Web Components basés sur JavaScript sans problème particulier. Mueller recommande de vérifier le rendu via l'outil Inspection d'URL de la Search Console pour s'assurer que le contenu critique reste bien accessible au crawler. La plupart du JavaScript moderne est désormais supporté.
Ce qu'il faut comprendre
Qu'est-ce qu'un Web Component et pourquoi cette question se pose-t-elle ?
Les Web Components sont une technologie native du navigateur qui permet de créer des composants réutilisables via JavaScript. Contrairement aux frameworks comme React ou Vue, ils s'appuient sur des standards web (Custom Elements, Shadow DOM, HTML Templates).
Le problème historique avec JavaScript en SEO ? Google devait exécuter le code pour accéder au contenu. Pendant longtemps, ce rendu différé posait des risques : délais de traitement, erreurs d'exécution, ressources manquantes. Les Web Components, en particulier avec le Shadow DOM, ajoutent une couche d'encapsulation qui pouvait théoriquement compliquer l'accès au contenu.
Google gère-t-il réellement le Shadow DOM des Web Components ?
Selon Mueller, oui — mais avec une nuance importante. Google peut traiter les Web Components, ce qui ne signifie pas qu'il le fera toujours parfaitement. Le crawler doit exécuter JavaScript, attendre le rendu, puis extraire le contenu encapsulé dans le Shadow DOM.
Concrètement ? Si votre Web Component charge du contenu de façon asynchrone, avec des dépendances externes ou des timeouts agressifs, Google pourrait ne pas tout capturer. D'où la recommandation insistante de tester avec l'outil Inspect URL de Search Console.
- Google supporte la plupart du JavaScript moderne, y compris ES6+
- Le Shadow DOM n'est pas un blocage technique absolu pour Googlebot
- Le rendu reste conditionné par les délais d'exécution et la disponibilité des ressources
- Un test systématique via Search Console est indispensable pour valider l'indexabilité
Qu'entend-on par « la plupart du JavaScript moderne » ?
Mueller reste volontairement flou. Google utilise une version de Chromium assez récente pour son moteur de rendu WRS (Web Rendering Service), mais « la plupart » n'est pas « tout ». Certains polyfills, modules ES très récents ou API expérimentales peuvent ne pas être supportés.
Le vrai risque ? Les erreurs JavaScript silencieuses qui cassent le rendu sans que vous le sachiez. Un try/catch manquant, une dépendance externe qui échoue, un CDN temporairement inaccessible — et votre contenu disparaît pour Googlebot.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Google gère effectivement beaucoup mieux JavaScript qu'il y a cinq ans — c'est un fait. Les sites en React, Vue ou Angular s'indexent sans trop de problèmes si le code est propre. Pour les Web Components, l'expérience terrain montre une réussite variable.
Le Shadow DOM, en particulier en mode closed, peut compliquer l'extraction du contenu. Certains retours montrent que Google accède au contenu rendu, mais parfois avec un délai qui pénalise la fraîcheur. [A vérifier] : on manque de données publiques fiables sur le taux de succès du rendu des Web Components complexes avec dépendances multiples.
Quelles nuances faut-il apporter à cette position officielle ?
Soyons honnêtes : dire « Google peut traiter les Web Components » ne signifie pas que c'est optimal ou sans risque. Le rendu JavaScript consomme des ressources et du temps. Pour un site avec des millions de pages, ça peut devenir un goulot d'étranglement.
Autre point — Google « peut » ne veut pas dire « avec la même fiabilité que du HTML statique ». Si votre contenu critique dépend entièrement d'un Web Component qui s'initialise en 2 secondes, vous prenez un risque. Et c'est là que ça coince : Mueller ne donne aucun SLA, aucune garantie de temps de rendu maximal.
Dans quels cas cette règle ne s'applique-t-elle pas complètement ?
Si votre Web Component dépend d'APIs tierces avec authentification, de cookies spécifiques, ou de contextes de navigation particuliers, Google risque de ne rien voir. Le WRS n'a pas accès aux cookies de session utilisateur, ne se connecte pas à vos APIs privées.
Cas concret observé : un site e-commerce avec prix et disponibilités rendus côté client via Web Components. Google indexait les fiches produits, mais sans prix ni bouton d'achat — contenus chargés de façon asynchrone après vérification de stock. Résultat : taux de clic catastrophique en SERP, snippets vides.
Impact pratique et recommandations
Que faut-il faire concrètement si vous utilisez des Web Components ?
Premier réflexe : tester chaque page critique avec l'outil Inspection d'URL de Search Console. Compare le HTML source (View Source) avec le rendu (Capture d'écran + DOM rendu). Si le contenu important n'apparaît que dans le rendu, vous dépendez du JavaScript — risque assumé.
Deuxième action : implémenter un SSR (Server-Side Rendering) ou un prerendering pour les pages stratégiques. Frameworks comme Lit supportent le SSR pour les Web Components. Ça réduit la dépendance au rendu client et accélère l'indexation.
- Tester systématiquement le rendu via Search Console (outil Inspect URL)
- Vérifier que le contenu critique est visible dans le DOM rendu, pas seulement côté client
- Éviter le Shadow DOM en mode
closedpour le contenu SEO stratégique - Implémenter un fallback HTML statique pour les éléments essentiels (titres, descriptions, contenus principaux)
- Monitorer les erreurs JavaScript en production (Google Tag Manager, Sentry, etc.)
- Analyser les logs serveur pour identifier les timeouts ou erreurs côté Googlebot
Quelles erreurs éviter absolument avec les Web Components en SEO ?
Ne jamais encapsuler le titre H1, la meta description simulée en HTML, ou le contenu textuel principal dans un Web Component sans fallback. Si le JS plante, vous perdez tout. Google est tolérant, mais pas magicien.
Autre piège : charger les Web Components via des bundles JavaScript trop lourds ou trop fragmentés. Googlebot a un budget de rendu limité. Si votre page met 5 secondes à être interactive, le crawler pourrait snapshooter un état intermédiaire incomplet.
Comment vérifier que votre implémentation actuelle est conforme ?
Audit technique en trois étapes. Un : crawl complet avec un outil comme Screaming Frog en mode JavaScript activé, comparaison avec crawl JS désactivé. Deux : analyse des rapports de couverture dans Search Console, repérage des pages indexées sans contenu visible. Trois : test manuel sur un échantillon de pages stratégiques.
Si vous détectez des écarts significatifs entre le contenu rendu et le contenu indexé, il faut corriger rapidement. Soit par du SSR, soit par un prerendering ciblé, soit en revoyant l'architecture des Web Components pour exposer le contenu essentiel sans dépendance JavaScript.
❓ Questions frequentes
Googlebot exécute-t-il le JavaScript de tous les Web Components sans exception ?
Le Shadow DOM en mode closed empêche-t-il Google d'accéder au contenu ?
Faut-il absolument implémenter du SSR pour les Web Components ?
L'outil Inspect URL de Search Console suffit-il pour valider l'indexabilité ?
Les Web Components impactent-ils les Core Web Vitals ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/05/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.