Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Faut-il supprimer la balise 'priority' de vos sitemaps ?
- □ Faut-il vraiment supprimer la balise 'changefreq' de vos sitemaps ?
- □ Pourquoi Google ignore-t-il la balise 'lastmod' dans vos sitemaps ?
- □ Faut-il encore remplir la balise lastmod dans vos sitemaps XML ?
- □ Pourquoi soumettre un sitemap ne garantit-il pas le crawl de vos URLs ?
- □ Faut-il remplacer les extensions de sitemap par des données structurées ?
- □ Faut-il abandonner les balises vidéo et image dans vos sitemaps XML ?
- □ Faut-il mettre à jour lastmod quand on ajoute des données structurées ?
- □ Pourquoi créer un sitemap révèle-t-il plus de problèmes techniques qu'il n'en résout ?
- □ Un site crawlable garantit-il vraiment une meilleure navigation utilisateur ?
- □ Faut-il vraiment attendre le crawl même après avoir soumis ses URLs via API ?
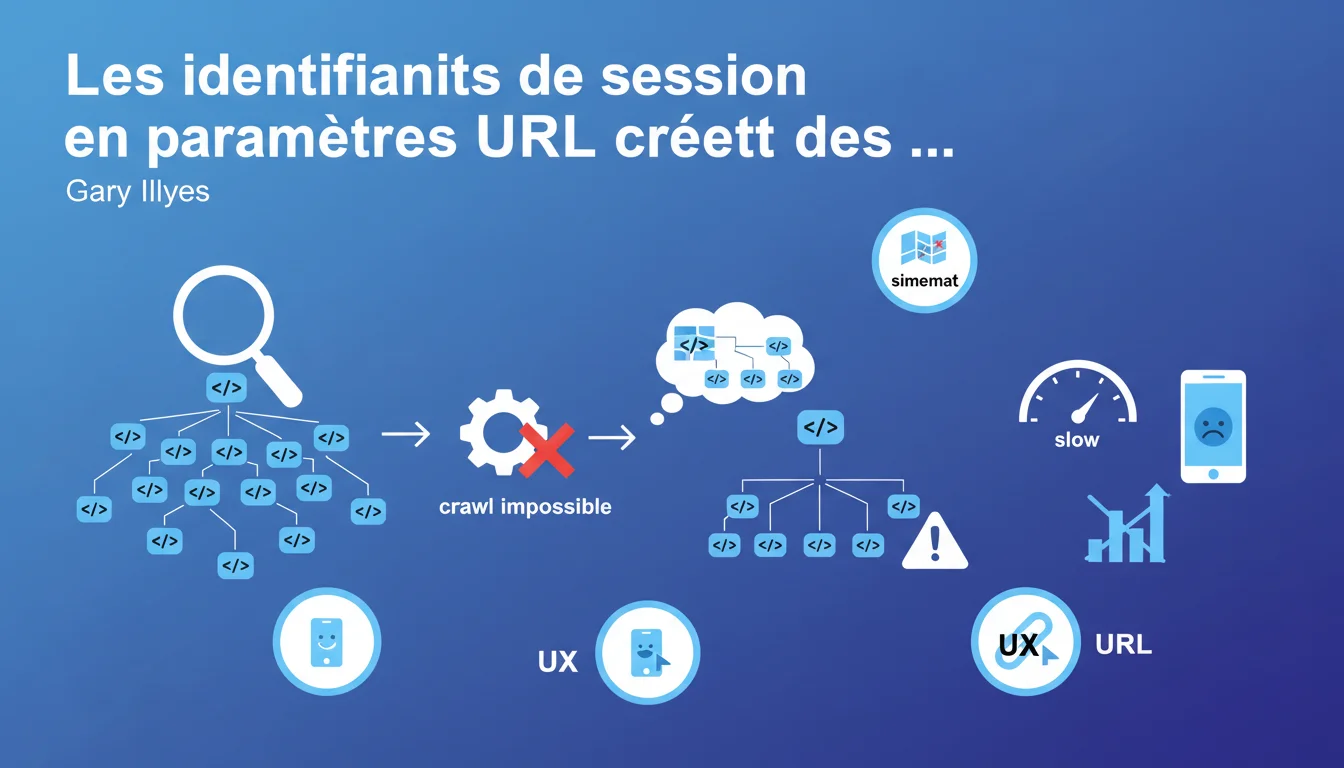
Les identifiants de session passés en paramètres d'URL génèrent un nombre quasi-infini d'URLs distinctes, rendant le crawl par les moteurs impossible. Ce problème, massif dans les années 2000, continue d'impacter certains sites — souvent révélé uniquement lors de la création d'un sitemap. La solution : gestion des sessions par cookies ou paramètres URL configurés dans Search Console.
Ce qu'il faut comprendre
Qu'est-ce qu'un identifiant de session en paramètre URL exactement ?
Un identifiant de session en paramètre URL, c'est ce token unique généré pour chaque visiteur et injecté directement dans l'URL — typiquement sous forme de ?sessionid=abc123xyz. Chaque fois qu'un utilisateur navigue sur le site, l'URL change, créant ainsi autant de variantes qu'il y a de visiteurs.
Le problème : Googlebot ne distingue pas ces URLs les unes des autres. Il les considère comme des pages distinctes — alors que le contenu reste identique. En quelques minutes, un site peut générer des milliers de combinaisons d'URLs que le crawler va tenter de suivre.
Pourquoi ce mécanisme rend-il le crawl impossible ?
Chaque URL unique consomme du crawl budget. Si Google doit traiter 10 000 variantes d'une même page produit à cause de paramètres de session, il gaspille des ressources sur du contenu dupliqué plutôt que d'explorer vos vraies pages.
Le crawl devient un cauchemar : le bot détecte une explosion exponentielle d'URLs et peut ralentir drastiquement ou carrément abandonner certaines sections du site. Résultat : vos nouvelles pages ou contenus stratégiques restent invisibles.
Comment les webmasters découvrent-ils ce problème ?
Gary Illyes pointe un révélateur classique : la génération du sitemap. Dès qu'un outil d'audit ou un CMS tente de lister toutes les URLs du site, il tombe sur des milliers (voire millions) de variations absurdes.
C'est souvent le premier signal d'alarme — mais le mal est déjà fait. Les logs serveur montrent alors que Googlebot a passé des semaines à crawler du vide, négligeant les sections importantes.
- Les identifiants de session en paramètres créent des URLs infinies
- Chaque variante consomme du crawl budget sans apporter de valeur
- Le problème se révèle souvent lors de la génération du sitemap XML
- Impact direct : ralentissement du crawl et indexation incomplète
- Solution de base : passer par des cookies ou configurer les paramètres dans Search Console
Avis d'un expert SEO
Ce problème appartient-il vraiment au passé ?
Soyons honnêtes : non. Si les CMS modernes (WordPress, Shopify, etc.) gèrent proprement les sessions par cookies, de nombreux sites custom ou legacy continuent d'injecter des sessionID dans les URLs. On voit encore ça régulièrement sur des plateformes e-commerce maison ou des sites institutionnels mal configurés.
Le vrai souci, c'est que ce n'est pas toujours intentionnel. Parfois, un paramètre de tracking analytics ou un module tiers mal implémenté crée exactement le même effet — et les équipes ne s'en rendent pas compte avant un audit approfondi.
Google traite-t-il automatiquement ces doublons ?
En théorie, oui — via la canonicalisation et les algorithmes de détection de duplicate content. Mais en pratique ? [À vérifier]. La détection n'est pas infaillible, surtout si les paramètres varient de manière imprévisible ou si le contenu change légèrement d'une session à l'autre.
Et même si Google consolide finalement les URLs, le gaspillage de crawl budget a déjà eu lieu. Le bot a perdu du temps, de la bande passante, et votre indexation a pris du retard. Compter uniquement sur l'IA de Google pour nettoyer vos erreurs, c'est risqué.
Quelles sont les situations où ce problème passe inaperçu ?
Les sites à faible trafic ou avec peu de pages ne verront peut-être jamais l'impact — leur crawl budget est suffisant pour absorber le gaspillage. Mais dès qu'un site atteint plusieurs milliers de pages ou génère beaucoup de sessions simultanées, ça explose.
Autre cas critique : les sites avec du contenu généré dynamiquement. Si chaque session produit des variations de filtres, de tri ou de pagination, on multiplie les combinaisons. Un e-commerce avec 10 000 produits peut facilement atteindre des millions d'URLs parasites.
Impact pratique et recommandations
Comment détecter si votre site génère des URLs infinies ?
Première étape : analysez vos logs serveur. Cherchez les patterns d'URLs avec des paramètres suspects (sessionid, sid, PHPSESSID, etc.). Si vous voyez Googlebot requêter des milliers de variations d'une même URL, c'est mauvais signe.
Deuxième vérification : générez un sitemap. Si l'outil explose en mémoire ou sort 500 000 URLs alors que votre site en contient 5 000, le diagnostic est posé. Vous pouvez aussi utiliser Screaming Frog en mode spider — s'il tourne à l'infini, vous avez votre réponse.
Quelles actions correctives appliquer immédiatement ?
Concrètement ? Éliminez les paramètres de session des URLs. Passez par des cookies ou du stockage local côté client. Si vous devez absolument garder des paramètres, utilisez la fonctionnalité Paramètres d'URL dans Google Search Console pour indiquer lesquels ignorer.
Côté technique : configurez des balises canonical pointant vers la version propre de chaque page. Ajoutez un robots.txt bloquant les patterns d'URLs problématiques si nécessaire — mais attention, c'est un pansement, pas une solution pérenne.
- Auditez vos logs pour identifier les paramètres de session dans les URLs crawlées
- Générez un sitemap pour repérer les explosions d'URLs
- Migrez la gestion des sessions vers des cookies HTTP
- Configurez les Paramètres d'URL dans Search Console si élimination impossible
- Implémentez des balises canonical propres sur chaque page
- Vérifiez que le
robots.txtne bloque pas les URLs légitimes - Surveillez le crawl budget via Search Console (section Statistiques d'exploration)
Faut-il se faire accompagner pour résoudre ce type de problème ?
La détection est une chose — la correction en est une autre. Modifier la gestion des sessions sur un site en production sans casser les tunnels de conversion ou les analytics, ça demande du doigté. Les impacts peuvent toucher l'authentification, le panier, les formulaires multi-étapes.
Si votre infrastructure est complexe ou si vous n'avez pas de développeur full-stack disponible, faire appel à une agence SEO technique peut éviter des erreurs coûteuses. Un accompagnement personnalisé permet de cartographier les risques, de tester en staging et de déployer proprement — sans perdre du trafic en route.
❓ Questions frequentes
Comment savoir si mon site utilise des identifiants de session en paramètres URL ?
Les cookies résolvent-ils définitivement le problème des sessions en URL ?
Peut-on corriger ce problème sans intervention développeur ?
Quel est l'impact réel sur le référencement si ce problème persiste ?
Les paramètres de tracking (UTM, fbclid) posent-ils le même problème ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/05/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.