Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Le contenu dupliqué pénalise-t-il vraiment votre site sur Google ?
- □ Faut-il vraiment s'inquiéter des alertes de duplication dans Google Search Console ?
- □ La balise canonical : pourquoi Google ignore-t-il parfois vos instructions ?
- □ Faut-il privilégier la balise HTML ou l'en-tête HTTP pour déclarer une URL canonique ?
- □ Pourquoi Google ignore-t-il votre balise canonical et comment le corriger ?
- □ Faut-il vraiment rediriger en 301 toutes les URL non-canoniques pour le SEO ?
- □ Pourquoi fusionner des pages similaires améliore-t-il le SEO même sans duplicate content ?
- □ Faut-il vraiment fusionner vos pages pour améliorer votre SEO ?
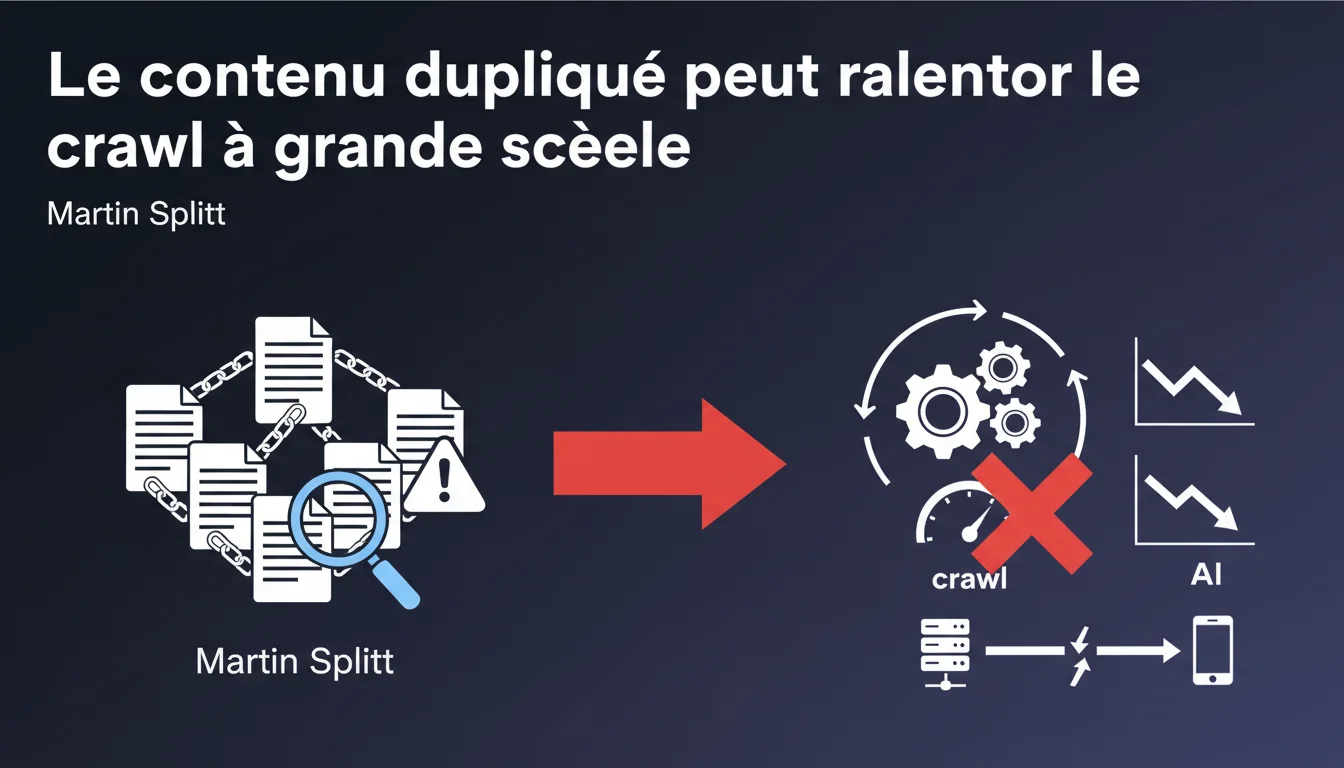
Google confirme que le contenu dupliqué à grande échelle ralentit le crawl, sans pour autant constituer une pénalité. Martin Splitt minimise l'impact — « rien qui devrait empêcher de dormir » — mais invite à optimiser quand même. Une position typiquement floue qui mérite décryptage.
Ce qu'il faut comprendre
Que dit exactement cette déclaration de Google ?
Martin Splitt reconnaît que le contenu dupliqué en volume important peut provoquer un ralentissement du crawl. Il précise immédiatement que ce n'est pas un sujet d'inquiétude majeur, mais qu'il reste pertinent dans une démarche d'optimisation.
La formulation reste volontairement vague : à partir de quel volume parle-t-on de « grande échelle » ? Quelle ampleur de ralentissement ? Google ne donne aucun chiffre, aucun seuil.
Pourquoi le contenu dupliqué affecte-t-il le crawl ?
Quand Googlebot découvre des pages avec un contenu identique ou quasi-identique, il doit analyser, comparer, déterminer quelle version conserver dans l'index. Ce traitement consomme du crawl budget — ressource limitée, surtout sur les gros sites.
Le bot perd du temps sur des URL redondantes au lieu d'explorer des pages à forte valeur ajoutée. Le problème se pose surtout quand des milliers de pages dupliquées saturent le site : facettes e-commerce, paramètres URL, versions imprimables, paginations mal gérées.
Quelle est la différence avec une pénalité duplicate content ?
Google insiste : ce n'est pas une pénalité algorithmique. Votre site ne sera pas sanctionné dans les classements uniquement parce qu'il contient du contenu dupliqué.
En revanche, l'effet indirect existe : moins de pages crawlées = moins de pages indexées rapidement = moins de visibilité potentielle. C'est un frein mécanique, pas une punition.
- Le contenu dupliqué à grande échelle ralentit le crawl des pages, sans constituer une pénalité directe
- L'impact se manifeste par une consommation inefficace du crawl budget disponible
- Google ne fournit aucun seuil chiffré pour définir « grande échelle »
- Le ralentissement affecte surtout les gros sites avec des milliers d'URL redondantes
- Les pages à forte valeur ajoutée peuvent être explorées moins fréquemment à cause du temps perdu sur les duplicatas
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Sur les gros sites e-commerce ou médias, on observe effectivement que le taux de crawl baisse quand des milliers de facettes, de paginations ou de paramètres URL génèrent du duplicate. Les logs le montrent clairement : Googlebot revient moins souvent sur les pages stratégiques.
Mais la formulation de Splitt minimise le problème. « Ne devrait pas empêcher de dormir » — sauf que sur un site de 100 000 pages avec 60 % de duplicate, ça peut carrément plomber l'indexation des nouveautés et des pages profondes. [À vérifier] : Google ne donne aucun chiffre sur le seuil critique.
Pourquoi Google reste-t-il si évasif sur les seuils ?
Parce que fixer un pourcentage ou un volume déclencherait des comportements de gaming : « OK, je peux me permettre 30 % de duplicate sans risque ». Google préfère laisser planer le flou pour que chacun optimise au maximum.
Autre raison : le crawl budget varie selon la popularité du site, sa fraîcheur, sa vitesse. Un seuil universel n'aurait aucun sens. Mais cette opacité complique le diagnostic pour les praticiens.
Quelles nuances faut-il apporter ?
Tous les duplicates ne se valent pas. Un site avec 500 fiches produits identiques à 95 % posera plus de problèmes qu'un blog avec quelques pages « À propos » ou mentions légales redondantes. Le volume relatif compte, mais aussi la proportion par rapport au contenu unique.
De plus, certains outils de crawl (Screaming Frog, OnCrawl) détectent du duplicate que Google ignore en pratique : métadonnées, blocs de navigation, footer. Il faut distinguer le duplicate structurel mineur du duplicate éditorial massif.
Impact pratique et recommandations
Que faut-il faire concrètement pour limiter l'impact ?
D'abord, auditer votre site pour identifier les sources de duplicate : facettes e-commerce, paginations infinies, paramètres de tri, versions AMP/mobile/desktop, syndication de contenu. Utilisez Screaming Frog ou un outil de crawl pour cartographier les doublons.
Ensuite, canonicaliser intelligemment. La balise rel=canonical doit pointer vers la version de référence. Si vous avez 50 variantes d'une fiche produit (couleur, taille), une seule URL doit être indexable.
Pour les facettes e-commerce : bloquez le crawl via robots.txt ou noindex sur les combinaisons à faible trafic. Privilégiez le JavaScript côté client pour les filtres — Googlebot ne suit pas les liens générés dynamiquement sans HTML initial.
Quelles erreurs éviter absolument ?
Ne canonicalisez pas à tort et à travers. Une page A qui pointe vers B via canonical, alors que B pointe vers C, crée une chaîne de canonicals — Google peut ignorer la directive.
Évitez aussi le noindex massif sur des pages crawlées fréquemment. Si Googlebot les explore quand même, vous gaspillez du crawl budget sans bénéfice. Mieux vaut bloquer proprement via robots.txt ou ne pas générer ces URL.
Et surtout, ne confondez pas duplicate content et thin content. Une page dupliquée mais riche en contenu unique pose moins de problème qu'une page unique mais vide de valeur.
Comment vérifier que mon site est optimisé ?
Analysez vos logs serveur sur 30 jours minimum. Quelle proportion des hits Googlebot concerne des pages stratégiques vs. redondantes ? Si moins de 50 % du crawl cible vos pages à forte valeur, vous avez une marge d'optimisation.
Utilisez aussi la Search Console : section Statistiques d'exploration. Un taux de crawl en baisse constante, couplé à des pages importantes non indexées, peut signaler un problème de duplicate qui bouffe le budget.
- Auditer les sources de contenu dupliqué (facettes, paginations, paramètres URL)
- Mettre en place des canonicals cohérentes sur toutes les variantes de pages
- Bloquer le crawl des URL à faible valeur via robots.txt ou noindex
- Privilégier le JavaScript côté client pour les filtres e-commerce dynamiques
- Éviter les chaînes de canonicals (A → B → C) qui rendent la directive inefficace
- Analyser les logs serveur pour mesurer la proportion de crawl sur les pages stratégiques
- Surveiller les Statistiques d'exploration dans la Search Console pour détecter les baisses de crawl
- Distinguer duplicate structurel mineur et duplicate éditorial massif
❓ Questions frequentes
Le contenu dupliqué peut-il entraîner une pénalité Google ?
À partir de combien de pages dupliquées parle-t-on de grande échelle ?
La balise canonical suffit-elle à résoudre le problème de crawl ?
Comment savoir si mon site est impacté par un problème de duplicate et de crawl ?
Le duplicate dans les blocs de navigation ou footer compte-t-il aussi ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/11/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.