Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Le contenu dupliqué pénalise-t-il vraiment votre site sur Google ?
- □ Le contenu dupliqué freine-t-il réellement le crawl de votre site ?
- □ Faut-il vraiment s'inquiéter des alertes de duplication dans Google Search Console ?
- □ La balise canonical : pourquoi Google ignore-t-il parfois vos instructions ?
- □ Pourquoi Google ignore-t-il votre balise canonical et comment le corriger ?
- □ Faut-il vraiment rediriger en 301 toutes les URL non-canoniques pour le SEO ?
- □ Pourquoi fusionner des pages similaires améliore-t-il le SEO même sans duplicate content ?
- □ Faut-il vraiment fusionner vos pages pour améliorer votre SEO ?
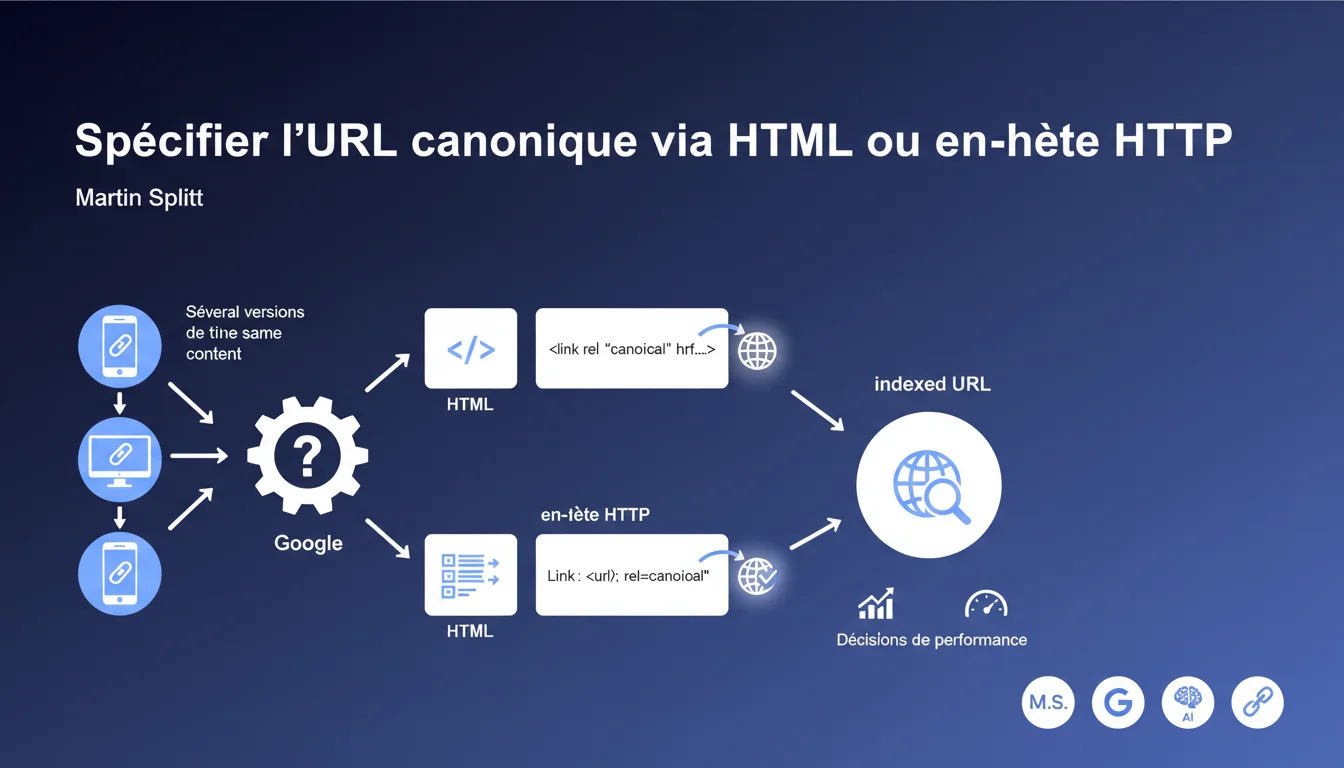
Google accepte deux méthodes pour déclarer une URL canonique : la balise <link rel="canonical"> en HTML ou l'en-tête HTTP Link. Les deux fonctionnent, mais le choix dépend de votre architecture technique. L'essentiel ? Être cohérent et ne jamais envoyer de signaux contradictoires entre ces deux canaux.
Ce qu'il faut comprendre
Google traite le duplicate content en s'appuyant sur les signaux de canonicalisation que vous lui envoyez. Cette déclaration rappelle qu'il existe deux canaux techniques distincts pour indiquer quelle URL vous souhaitez voir indexée.
Pourquoi Google propose-t-il deux méthodes de canonicalisation ?
La balise HTML <link rel="canonical"> est la méthode historique, accessible directement dans le code source de la page. Elle fonctionne pour tous les types de contenus HTML et reste la plus utilisée par les CMS.
L'en-tête HTTP Link: <URL>; rel="canonical" s'avère indispensable pour les fichiers non-HTML — PDF, images, documents — qui n'ont pas de balise <head>. C'est aussi une solution élégante pour des architectures complexes où modifier le HTML est compliqué.
Quelle méthode Google privilégie-t-il vraiment ?
Officiellement, aucune priorité n'est donnée à l'une ou l'autre. Google traite les deux comme des signaux équivalents dans son algorithme de sélection de l'URL canonique.
Le problème surgit quand vous envoyez des signaux contradictoires : une balise HTML pointe vers une URL, l'en-tête HTTP vers une autre. Dans ce cas, Google choisit — et son choix ne vous plaira pas forcément.
Que se passe-t-il en cas de conflit entre HTML et HTTP ?
Google arbitre en croisant tous les signaux disponibles : sitemaps, redirections, liens internes, historique de crawl. La canonique déclarée devient un signal parmi d'autres, pas une directive absolue.
Autrement dit : si vos deux méthodes se contredisent, vous perdez le contrôle. Google décide selon sa propre logique — et vous découvrez le verdict dans la Search Console, souvent trop tard.
- Deux canaux valides : balise HTML et en-tête HTTP fonctionnent tous deux
- Pas de hiérarchie officielle entre les deux méthodes
- En-tête HTTP obligatoire pour les fichiers non-HTML (PDF, images)
- Cohérence critique : ne jamais envoyer de signaux contradictoires
- Google arbitre en cas de conflit — résultat imprévisible
Avis d'un expert SEO
Cette approche "les deux fonctionnent" est-elle suffisante en production ?
Soyons honnêtes : cette déclaration est techniquement exacte mais stratégiquement incomplète. Oui, les deux méthodes fonctionnent. Non, elles ne se valent pas dans tous les contextes.
Sur le terrain, la balise HTML reste plus fiable pour une raison simple : elle est visible dans le DOM, debuggable avec les outils classiques, et tous les CMS la gèrent nativement. L'en-tête HTTP, lui, nécessite un accès serveur et peut être écrasé par des couches intermédiaires (CDN, reverse proxy, cache).
Le vrai enjeu ? La gouvernance technique. Dans une stack moderne avec plusieurs équipes (dev, ops, SEO), qui contrôle quoi ? Si votre équipe SEO déclare une canonique en HTML pendant que les ops configurent un en-tête HTTP différent, vous êtes dans le brouillard. [À vérifier] sur votre propre infrastructure : qui a la main sur chaque canal ?
Google détecte-t-il vraiment tous les conflits entre HTML et HTTP ?
La documentation officielle reste floue sur l'ordre de traitement. Google affirme "croiser les signaux" mais ne précise pas les règles d'arbitrage.
Observations terrain : quand un conflit existe, Google semble privilégier l'en-tête HTTP sur les fichiers non-HTML (logique), mais le comportement est moins prévisible sur les pages HTML. Parfois c'est l'en-tête qui gagne, parfois la balise, parfois ni l'un ni l'autre — Google choisit une troisième URL.
Ce flou n'est pas anodin. Il laisse Google libre d'ajuster ses heuristiques sans documenter chaque cas de figure. Pour un praticien, la seule posture viable : ne jamais compter sur l'arbitrage de Google. Éliminez les conflits en amont.
Dans quels cas l'en-tête HTTP devient-il incontournable ?
Pour les fichiers PDF, images ou tout contenu non-HTML exposé à l'indexation, l'en-tête HTTP est votre seul levier. Pas de balise possible, donc pas d'alternative.
Autre cas d'usage légitime : les architectures headless où le HTML est généré côté client (SPA React/Vue avec rendu tardif). Si votre canonique doit être détectée avant le rendu JavaScript, l'en-tête HTTP sécurise le signal dès la réponse serveur.
En revanche, sur un site WordPress ou Shopify classique, l'en-tête HTTP apporte plus de complexité que de valeur. Restez sur la balise HTML : c'est plus simple à auditer, à débugger, et à transmettre à un successeur.
Impact pratique et recommandations
Comment choisir entre balise HTML et en-tête HTTP pour mon site ?
Privilégiez la balise HTML par défaut. Elle est universelle, documentée, et gérée nativement par tous les CMS du marché. Votre équipe éditoriale peut vérifier son existence dans le code source sans compétence serveur.
Réservez l'en-tête HTTP aux cas où la balise HTML est techniquement impossible : PDF, images, fichiers statiques. Ou si votre architecture impose une gestion centralisée côté serveur (CDN, edge computing).
Et surtout : documentez votre choix. Dans un an, quand un nouvel arrivant audite le site, il doit comprendre immédiatement quel canal est actif et pourquoi.
Quelles erreurs éviter absolument lors de l'implémentation ?
Première erreur : implémenter les deux méthodes avec des URLs différentes. Vous croyez doubler les signaux, vous créez un conflit. Google choisit à votre place — et rarement en votre faveur.
Deuxième piège : oublier que les en-têtes HTTP sont modifiables par les couches intermédiaires. Votre serveur Origin envoie la bonne valeur, mais votre CDN l'écrase ? Vous découvrez le problème trois mois plus tard dans la Search Console.
Troisième faille : canonicaliser vers une URL en 301. La canonique doit pointer vers une ressource qui répond en 200. Sinon, Google ignore le signal ou, pire, indexe l'URL source malgré votre déclaration.
Comment auditer et valider ma configuration actuelle ?
Testez avec curl ou les DevTools pour inspecter les en-têtes HTTP réels côté client. Ne vous fiez pas uniquement à votre configuration serveur — vérifiez ce que Google reçoit vraiment.
Croisez avec la Search Console : dans l'outil "Inspection d'URL", Google indique quelle URL il considère comme canonique et pourquoi (déclarée par l'utilisateur vs. sélectionnée par Google).
Si l'URL canonique détectée par Google ne correspond pas à votre déclaration, c'est un signal d'alarme. Soit vous avez un conflit, soit d'autres signaux (redirections, sitemaps, liens internes) contredisent votre balise.
- Privilégier la balise HTML sauf contrainte technique justifiée
- Utiliser l'en-tête HTTP uniquement pour les fichiers non-HTML ou architectures headless
- Ne jamais implémenter les deux méthodes avec des URLs différentes
- Vérifier les en-têtes HTTP finaux côté client (curl, DevTools)
- S'assurer que l'URL canonique répond en 200, jamais en 301/302
- Auditer régulièrement la Search Console pour détecter les écarts
- Documenter la méthode choisie pour les futurs auditeurs
La canonicalisation est un signal technique subtil qui nécessite une cohérence absolue entre tous vos canaux. Une erreur de configuration peut passer inaperçue pendant des mois et éroder progressivement votre visibilité organique.
Si votre infrastructure technique est complexe — multiples environnements, CDN, gestion hybride HTML/HTTP — il devient difficile de garantir cette cohérence seul. Une agence SEO spécialisée peut auditer votre stack complète, identifier les conflits invisibles et mettre en place une gouvernance qui sécurise vos signaux de canonicalisation sur le long terme.
❓ Questions frequentes
Puis-je utiliser à la fois la balise HTML et l'en-tête HTTP pour renforcer le signal ?
L'en-tête HTTP est-il prioritaire sur la balise HTML en cas de conflit ?
Comment canonicaliser un PDF ou une image sans balise HTML ?
Google respecte-t-il toujours la canonique que je déclare ?
Dois-je déclarer une canonique auto-référencée sur chaque page ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/11/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.