Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi Googlebot signale-t-il des soft 404 sur vos pages géolocalisées vides ?
- □ Le cloaking géolocalisé est-il vraiment acceptable pour Google ?
- □ Afficher du contenu national par défaut est-il considéré comme du cloaking par Google ?
- □ Googlebot crawle-t-il vraiment votre site depuis plusieurs pays ?
- □ Faut-il attendre avant de juger l'impact d'une mise à jour algorithmique Google ?
- □ Pourquoi l'analyse des fichiers logs est-elle indispensable pour les gros sites ?
- □ Pourquoi une page vide détruit-elle votre expérience utilisateur et votre SEO ?
- □ Comment garantir une expérience cohérente avec les attentes utilisateur sans risquer une pénalité pour cloaking ?
- □ Faut-il vraiment comparer l'état réel des pages avant et après une baisse de trafic ?
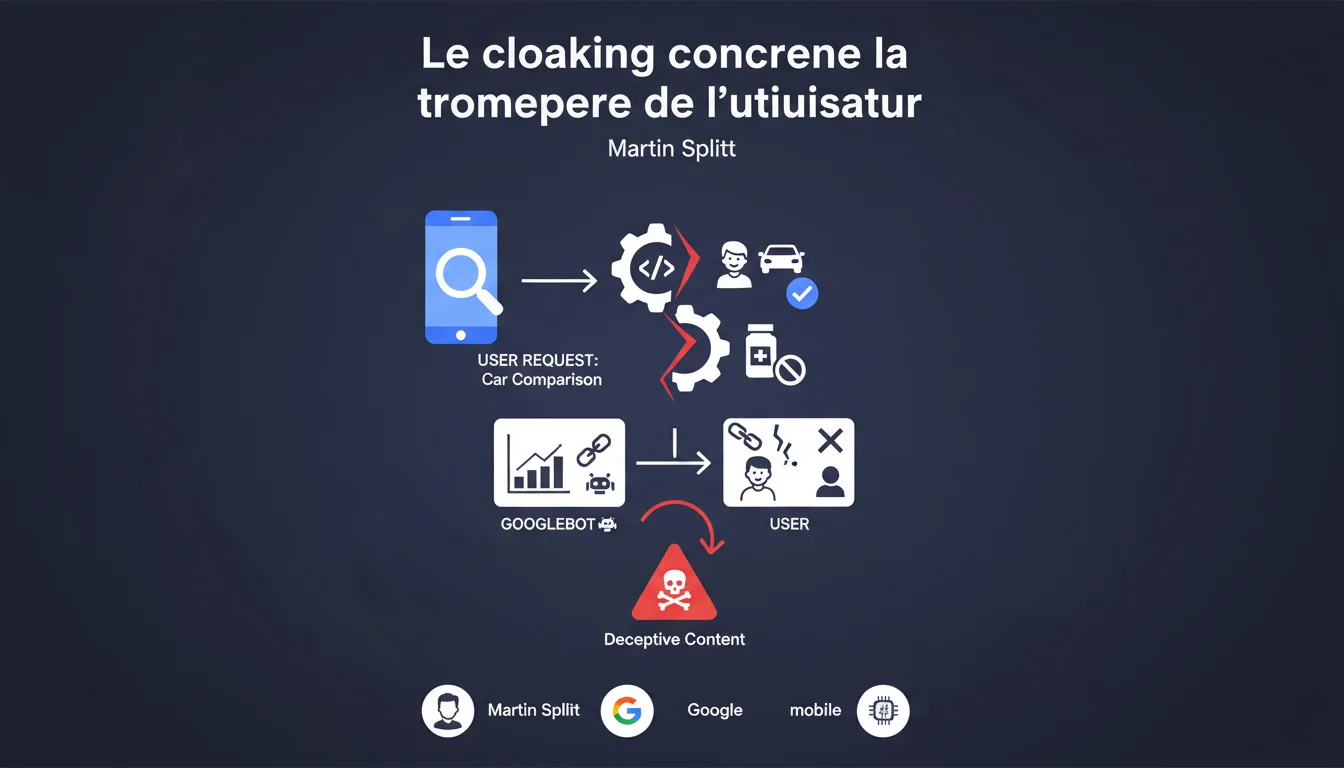
Google précise que le cloaking pose problème uniquement quand il trompe l'utilisateur final. Un site affichant du contenu radicalement différent de ce qu'annonce la SERP (exemple : promesse de comparatif auto, livraison de publicités pharmaceutiques) franchit la ligne rouge. L'intention de tromper l'utilisateur prime sur la technique employée.
Ce qu'il faut comprendre
Qu'est-ce que Google entend vraiment par "tromperie de l'utilisateur" ?
La définition technique classique du cloaking — afficher un contenu différent au bot et à l'utilisateur — ne suffit plus à qualifier une infraction. Google recentre son approche sur l'expérience utilisateur : si quelqu'un cherche « comparaison voitures », clique sur un résultat et se retrouve noyé dans des publicités pour des médicaments, il y a tromperie.
L'exemple donné par Splitt est volontairement caricatural. Il illustre un écart total entre la promesse du résultat de recherche et la réalité de la page. Ce qui compte, c'est le décalage entre l'attente légitime de l'utilisateur (basée sur le snippet, le titre, la meta description) et ce qu'il reçoit réellement.
Cette déclaration change-t-elle la définition historique du cloaking ?
Pas vraiment. Google a toujours sanctionné le cloaking, mais cette clarification déplace la focale. Auparavant, la documentation insistait sur la différence de contenu entre bot et humain. Ici, l'accent est mis sur l'intention malveillante : tromper sciemment l'utilisateur pour du clic, de la monétisation abusive, ou du spam.
Concrètement ? Un site qui adapte légèrement son affichage selon le user-agent pour des raisons techniques légitimes (compatibilité mobile, optimisation du rendu) ne devrait pas être inquiété. À condition que l'utilisateur reçoive bien ce qu'on lui a promis dans la SERP.
Quelles sont les limites de cette définition floue ?
Splitt ne donne pas de seuil quantitatif. À quel point le contenu peut-il diverger avant de devenir "trompeur" ? Un site de comparaison auto qui affiche aussi des publicités pour des médicaments (mais pas uniquement) franchit-il la ligne ? La réponse reste dans un angle mort.
Cette zone grise laisse de la marge d'interprétation à Google. En l'absence de critères chiffrés, c'est l'équipe de spam qui juge au cas par cas. Pour un praticien, cela signifie qu'il faut documenter l'intention légitime de toute divergence de rendu entre bots et utilisateurs.
- Le cloaking n'est sanctionné que s'il induit l'utilisateur en erreur entre promesse SERP et réalité de la page
- Les ajustements techniques légitimes (rendu mobile, A/B testing transparent) ne devraient pas poser problème
- Google ne fournit pas de seuil précis — la frontière entre optimisation et tromperie reste floue
- L'intention de nuire à l'expérience utilisateur est au cœur de la décision de Google
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les sanctions observées sur le terrain ?
Oui et non. Les cas de pénalités manuelles pour cloaking concernent effectivement des sites où l'écart entre promesse et livraison est flagrant. Pharma spam déguisé en contenu légitime, redirections sauvages vers des sites tiers, pages satellites — autant de schémas où l'utilisateur se fait avoir.
Mais — et c'est là que ça coince — on observe aussi des sites pénalisés pour des divergences techniques mineures, sans intention manifeste de tromper. [À vérifier] : des cas de sanctions pour du JavaScript rendering différentiel léger existent, même quand le contenu final est quasi-identique. Google affirme viser la tromperie, mais l'application terrain n'est pas toujours aussi nuancée.
Que faire des pratiques d'A/B testing et de personnalisation ?
Splitt ne mentionne pas explicitement l'A/B testing ni la personnalisation par segment utilisateur. Pourtant, ces pratiques affichent par nature du contenu différent selon le visiteur. Si le bot voit la version A et que 50 % des utilisateurs voient la version B, est-ce du cloaking ?
En théorie, non — tant que chaque version correspond à ce qui est promis dans la SERP. En pratique, documenter la démarche et s'assurer que Googlebot peut accéder aux différentes variantes (via des tests avec Inspect URL) est une précaution indispensable. Certains outils d'A/B testing servent systématiquement la même version au bot : c'est risqué si la version servie ne reflète pas la majorité du trafic.
Pourquoi Google reste-t-il aussi vague sur les critères techniques ?
Garder une définition large permet à Google de s'adapter sans devoir réviser sa documentation à chaque nouvelle astuce de spam. Si la règle était "pas plus de 10 % de différence de contenu texte entre bot et utilisateur", les spammeurs calibreraient leurs pages à 9,9 %. En restant flou, Google conserve une marge de manœuvre discrétionnaire.
Pour nous, praticiens, cela signifie qu'aucune checklist automatique ne garantit l'immunité. Il faut évaluer chaque cas avec bon sens : si un utilisateur se sent floué en arrivant sur la page, Google peut sanctionner. Si l'adaptation technique sert réellement l'expérience (accessibilité, performance), le risque est minimal. [À vérifier] : aucune documentation officielle ne liste des seuils tolérés — tout repose sur l'interprétation humaine chez Google.
Impact pratique et recommandations
Comment vérifier que mon site ne tombe pas dans le cloaking trompeur ?
Première étape : comparer systématiquement ce que voit Googlebot et ce que voit un utilisateur lambda. Utilise l'outil "Inspecter l'URL" dans la Search Console pour obtenir le rendu tel que Google le perçoit. Compare ensuite avec une session incognito classique (desktop et mobile).
Si tu constates des écarts significatifs — blocs de contenu manquants, titres différents, éléments cachés au bot — interroge-toi sur la raison. Un carrousel JavaScript qui ne se charge pas côté bot, ce n'est pas grave si le contenu essentiel est présent. Un bloc promotionnel affiché uniquement aux humains, c'est limite. Un site entier qui bascule de thématique entre bot et utilisateur, c'est la ligne rouge.
Quelles erreurs éviter absolument ?
Ne jamais afficher un contenu éditorial riche au bot et une page publicitaire ou quasi-vide à l'utilisateur. C'est le schéma classique du spam pharma : la page indexée parle santé générique, l'utilisateur atterrit sur une boutique de médicaments douteux. Google détecte cet écart via des signaux comportementaux (taux de rebond explosif, retour immédiat à la SERP) et des contrôles manuels.
Évite aussi les redirections conditionnelles basées sur le user-agent. Rediriger Googlebot vers une URL et les utilisateurs vers une autre est du cloaking pur et dur, même si les deux pages traitent du même sujet. Si tu dois rediriger, fais-le pour tout le monde, bot inclus.
Que faire si je personnalise légitimement mon contenu ?
Documente ta démarche. Si tu adaptes le contenu selon la géolocalisation (exemple : site e-commerce avec stocks régionaux), assure-toi que Googlebot voit une version par défaut cohérente avec la majorité de ton trafic. Utilise les balises hreflang ou rel=canonical pour signaler les variantes régionales si nécessaire.
Pour l'A/B testing, privilégie les outils qui servent la même variante au bot qu'à l'utilisateur lors de la première visite. Si ton outil modifie le DOM côté client après le rendu initial, vérifie que Googlebot capture bien la version finale. Un écart ponctuel et léger ne pose pas problème — un écart systématique et structurel, si.
- Comparer régulièrement le rendu Googlebot (Search Console) vs utilisateur réel (incognito)
- Éliminer toute redirection conditionnelle basée sur le user-agent vers des URLs différentes
- Vérifier que le contenu promis dans le snippet SERP correspond à la page réelle
- Documenter les raisons techniques de toute divergence de rendu (accessibilité, performance)
- Tester les outils d'A/B testing pour s'assurer que Googlebot voit une version représentative
- Éviter d'afficher massivement de la publicité ou du contenu hors-sujet uniquement aux utilisateurs
La frontière entre optimisation technique et cloaking trompeur repose sur l'intention et l'impact utilisateur. Si l'écart entre ce que promet la SERP et ce que livre la page est significatif, le risque de sanction existe. Dans les cas complexes — personnalisation avancée, architectures JavaScript lourdes, tests multivariés — il peut être judicieux de solliciter un accompagnement spécialisé pour auditer finement les divergences et sécuriser la conformité avec les attentes de Google.
❓ Questions frequentes
Un site peut-il afficher du contenu différent sur mobile et desktop sans risquer une sanction pour cloaking ?
L'A/B testing côté client est-il considéré comme du cloaking ?
Peut-on cacher certains blocs publicitaires à Googlebot pour améliorer le crawl budget ?
Comment Google détecte-t-il le cloaking en pratique ?
Un site sanctionné pour cloaking peut-il récupérer son classement ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 13/12/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.