Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Faut-il paniquer si votre hreflang disparaît temporairement pendant une migration ?
- □ Les domaines locaux (ccTLD) offrent-ils vraiment un avantage SEO pour le référencement local ?
- □ Pourquoi Google traite-t-il un site après expansion massive comme un tout nouveau site web ?
- □ Pourquoi Google continue-t-il d'afficher l'ancien nom de votre site après un rebranding ?
- □ Faut-il vraiment corriger toutes les erreurs d'indexation signalées dans la Search Console ?
- □ Comment exploiter l'API du tableau de bord de statut Google Search pour vos outils SEO ?
- □ Pourquoi vos données structurées produits n'apparaissent-elles pas dans les résultats enrichis ?
- □ Pourquoi Google refuse-t-il les requêtes d'indexation illimitées dans Search Console ?
- □ Marque confondue avec un mot courant : faut-il vraiment attendre des mois sans rien faire ?
- □ Comment masquer du texte à Google en bloquant le JavaScript qui le contient ?
- □ Peut-on vraiment utiliser le Schema Recipe pour n'importe quel type de recette ?
- □ Google peut-il transférer vos rankings SEO lors d'une migration de domaine ?
- □ Comment la balise noindex fonctionne-t-elle réellement page par page ?
- □ Faut-il vraiment remplir tous les champs des données structurées pour que Google les prenne en compte ?
- □ Les flux RSS sont-ils vraiment exploités par Google pour l'exploration et l'indexation ?
- □ Pourquoi votre nouveau favicon met-il autant de temps à apparaître dans les résultats Google ?
- □ L'ordre des balises H1, H2, H3 influence-t-il vraiment le classement Google ?
- □ Les liens sur pages bloquées au crawl perdent-ils vraiment toute leur valeur SEO ?
- □ Faut-il vraiment structurer ses sitemaps selon des règles précises ou peut-on faire n'importe quoi ?
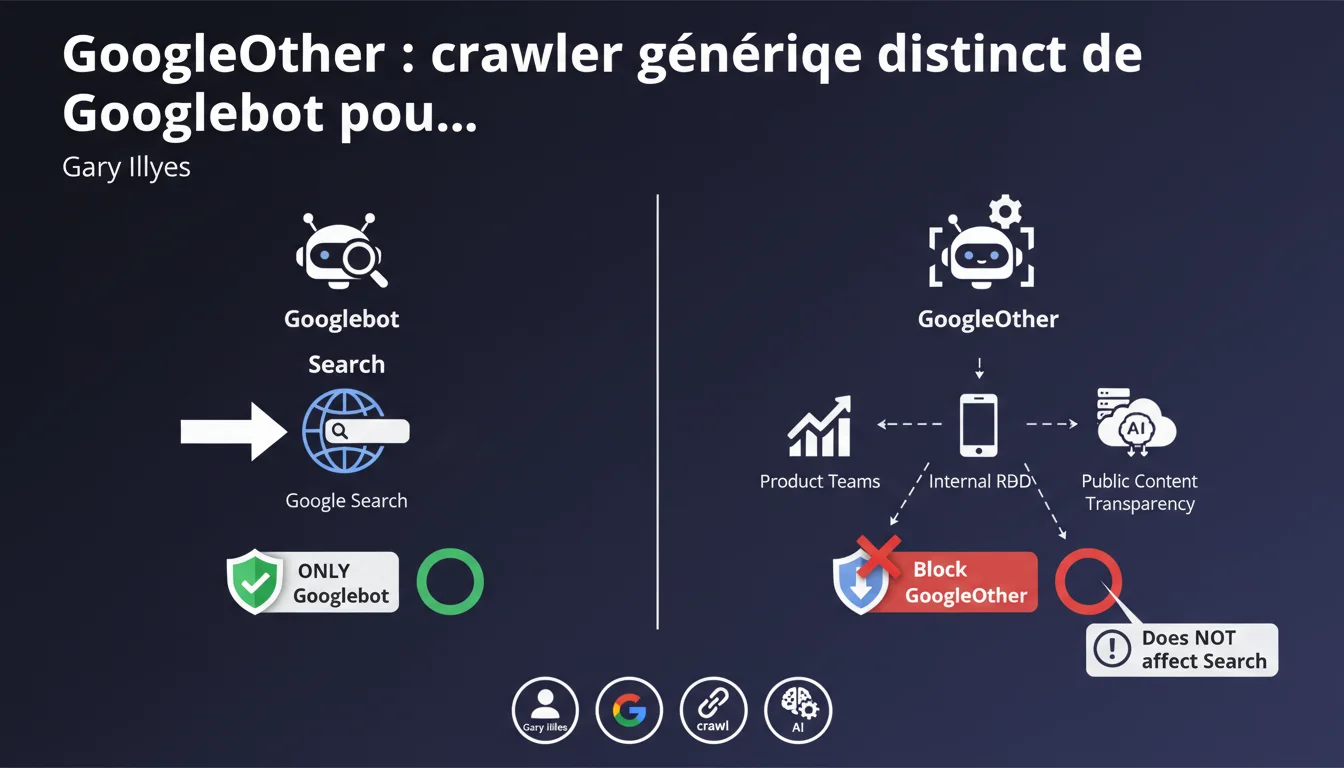
Google a lancé GoogleOther, un crawler générique distinct de Googlebot utilisé pour la R&D et diverses équipes produit. Bloquer GoogleOther n'affecte pas le référencement Search (géré uniquement par Googlebot), mais peut perturber d'autres services Google. La transparence accrue permet un contrôle granulaire via robots.txt.
Ce qu'il faut comprendre
Pourquoi Google a-t-il créé un crawler séparé de Googlebot ?
GoogleOther répond à un besoin de transparence opérationnelle. Historiquement, Google utilisait des crawlers internes non documentés pour alimenter ses équipes R&D et produit. Les webmasters n'avaient aucune visibilité sur ces accès, ce qui générait de la confusion dans les logs serveur.
En isolant ces activités sous une user-agent identifiable, Google permet aux administrateurs de sites de distinguer clairement le crawl destiné à Search (Googlebot) du crawl destiné aux expérimentations internes. C'est un pas vers plus de contrôle côté éditeur.
GoogleOther peut-il vraiment affecter mon référencement ?
Non. La déclaration est claire : seul Googlebot est utilisé pour Search. GoogleOther sert à d'autres équipes produit — développement, analyse de contenu accessible publiquement, tests internes. Bloquer GoogleOther via robots.txt n'a aucun impact sur votre classement organique.
En revanche, bloquer ce crawler peut perturber des services Google annexes dont la nature exacte n'est pas détaillée. Google reste évasif sur les produits concernés — une zone grise typique.
Quelles sont les implications pratiques pour un administrateur de site ?
- Un nouveau user-agent à surveiller dans les logs serveur et les fichiers robots.txt
- La possibilité de bloquer sélectivement GoogleOther sans risque SEO direct
- Un gain de visibilité sur l'activité de crawl non-Search de Google
- Une incertitude persistante sur les services Google impactés par un blocage
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, dans l'ensemble. Les logs serveur montrent depuis des années des crawlers Google non identifiés ou portant des user-agents génériques. GoogleOther formalise ce qui existait déjà de manière opaque. Côté terrain, aucun cas documenté ne lie le blocage de GoogleOther à une baisse de positions Search — ce qui confirme la séparation annoncée.
Cependant, Google reste volontairement flou sur les « divers services » impactés. Pas de liste exhaustive, pas d'exemples concrets. [À vérifier] : l'absence de transparence sur les produits concernés laisse planer un doute stratégique — est-ce Google Ads, Analytics, Discovery, autre chose ? Impossible de le savoir avec certitude.
Quelles nuances faut-il apporter à ce message ?
Première nuance : « accessible publiquement » ne signifie pas « indexable ». GoogleOther peut crawler des contenus que vous avez choisi de désindexer via noindex ou robots.txt, tant qu'ils restent techniquement accessibles via URL. Si vous avez des pages sensibles mais publiques, un blocage IP peut être nécessaire.
Deuxième nuance : même si GoogleOther ne sert pas directement Search, il alimente des équipes de développement et de R&D. Ces données peuvent indirectement influencer les futurs algorithmes de ranking ou les évolutions produit. Bloquer ce crawler, c'est potentiellement se retirer d'une boucle d'amélioration continue — à chacun de décider si c'est souhaitable.
Dans quels cas faut-il envisager de bloquer GoogleOther ?
Si votre infrastructure a une bande passante limitée ou si vous gérez un site à fort trafic avec des marges serveur serrées, bloquer GoogleOther peut réduire la charge sans conséquence SEO. Certains éditeurs de presse ou e-commerces à forte volumétrie font ce choix par pragmatisme.
En revanche, si vous utilisez intensivement l'écosystème Google (Ads, Analytics, Search Console), un blocage pourrait théoriquement dégrader la qualité des données remontées ou l'expérience utilisateur sur certains produits — encore une fois, Google ne donne aucune garantie dans un sens ou dans l'autre.
Impact pratique et recommandations
Que faut-il faire concrètement avec GoogleOther ?
Première étape : auditer vos logs serveur pour identifier la fréquence et les sections crawlées par GoogleOther. Si le volume est marginal et ne surcharge pas votre infrastructure, laissez-le passer — aucun bénéfice à le bloquer.
Si vous constatez un crawl intensif qui pèse sur vos ressources, ajoutez une règle spécifique dans votre robots.txt. GoogleOther respecte les directives standards — c'est d'ailleurs tout l'intérêt de son identification claire.
Quelles erreurs éviter dans la gestion de GoogleOther ?
Ne confondez pas GoogleOther et Googlebot dans vos règles robots.txt. Un blocage global des user-agents Google impacterait aussi Googlebot, avec des conséquences catastrophiques sur l'indexation. Soyez granulaire.
Évitez également de bloquer aveuglément par peur. Si votre site n'a pas de contrainte technique particulière, laisser GoogleOther accéder au contenu public ne présente aucun risque SEO — et pourrait même nourrir des améliorations futures dans l'écosystème Google.
Comment vérifier que mon site est correctement configuré ?
- Analyser les logs serveur pour repérer les accès GoogleOther (user-agent :
GoogleOther) - Vérifier que Googlebot et GoogleOther sont traités distinctement dans robots.txt
- Tester les directives robots.txt via Search Console (Googlebot) et manuellement (GoogleOther)
- Monitorer la charge serveur avant/après un éventuel blocage de GoogleOther
- Documenter les sections autorisées/bloquées et les raisons stratégiques
❓ Questions frequentes
GoogleOther peut-il impacter mon référencement sur Google Search ?
Comment bloquer GoogleOther sans impacter Googlebot ?
Quels services Google sont affectés si je bloque GoogleOther ?
GoogleOther respecte-t-il les directives robots.txt et crawl-delay ?
Dois-je surveiller GoogleOther dans mes logs serveur ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.