Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Faut-il paniquer si votre hreflang disparaît temporairement pendant une migration ?
- □ Faut-il bloquer GoogleOther ou risquer d'impacter ses services Google ?
- □ Les domaines locaux (ccTLD) offrent-ils vraiment un avantage SEO pour le référencement local ?
- □ Pourquoi Google traite-t-il un site après expansion massive comme un tout nouveau site web ?
- □ Pourquoi Google continue-t-il d'afficher l'ancien nom de votre site après un rebranding ?
- □ Faut-il vraiment corriger toutes les erreurs d'indexation signalées dans la Search Console ?
- □ Comment exploiter l'API du tableau de bord de statut Google Search pour vos outils SEO ?
- □ Pourquoi vos données structurées produits n'apparaissent-elles pas dans les résultats enrichis ?
- □ Pourquoi Google refuse-t-il les requêtes d'indexation illimitées dans Search Console ?
- □ Marque confondue avec un mot courant : faut-il vraiment attendre des mois sans rien faire ?
- □ Comment masquer du texte à Google en bloquant le JavaScript qui le contient ?
- □ Peut-on vraiment utiliser le Schema Recipe pour n'importe quel type de recette ?
- □ Google peut-il transférer vos rankings SEO lors d'une migration de domaine ?
- □ Comment la balise noindex fonctionne-t-elle réellement page par page ?
- □ Faut-il vraiment remplir tous les champs des données structurées pour que Google les prenne en compte ?
- □ Les flux RSS sont-ils vraiment exploités par Google pour l'exploration et l'indexation ?
- □ Pourquoi votre nouveau favicon met-il autant de temps à apparaître dans les résultats Google ?
- □ L'ordre des balises H1, H2, H3 influence-t-il vraiment le classement Google ?
- □ Faut-il vraiment structurer ses sitemaps selon des règles précises ou peut-on faire n'importe quoi ?
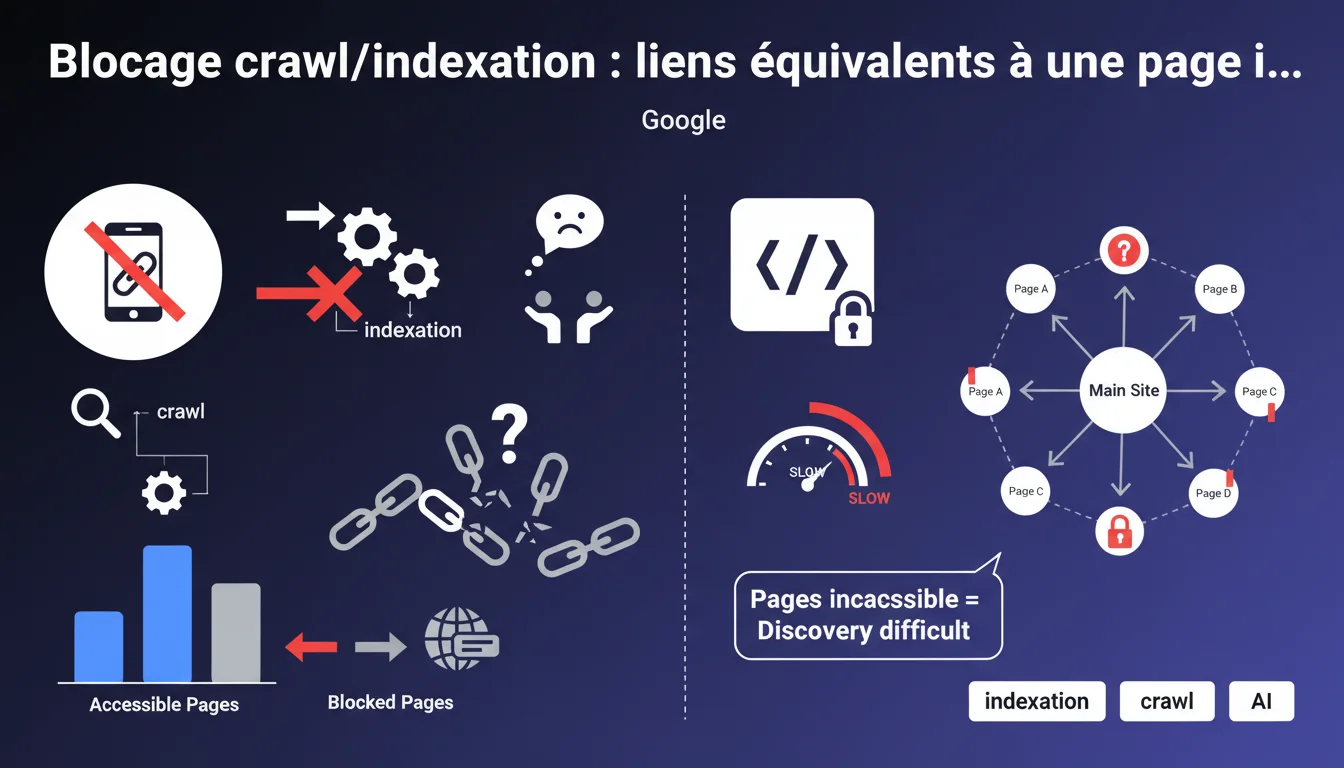
Google considère qu'une page bloquée au crawl ou à l'indexation est équivalente à une page inexistante pour l'utilisateur. Les liens présents sur ces pages perdent donc leur pertinence et ne transmettent pas de valeur. Si une portion significative de votre site n'est accessible que via des pages bloquées, sa découverte par les moteurs devient extrêmement difficile.
Ce qu'il faut comprendre
Pourquoi Google assimile-t-il une page bloquée à une page inexistante ?
La logique est simple : si un utilisateur ne peut pas accéder à une page, peu importe qu'elle soit techniquement présente sur le serveur. Google adopte ici une perspective centrée sur l'expérience utilisateur.
Une page bloquée via robots.txt, noindex, ou authentification devient invisible pour Googlebot. Les liens qu'elle contient ne peuvent pas être suivis efficacement, et leur valeur de recommandation disparaît. C'est cohérent avec le principe que Google explore et classe le web comme un utilisateur le ferait.
Qu'est-ce que cela signifie concrètement pour le maillage interne ?
Si vos pages stratégiques ne reçoivent des liens internes que depuis des pages bloquées, elles deviennent orphelines du point de vue de Google. Même avec un sitemap XML, leur découverte et leur indexation restent compromises.
Le problème s'aggrave quand une section entière du site dépend de ces liens invisibles. Google peut alors sous-estimer l'importance de ces contenus, voire ne jamais les explorer correctement.
Cette règle s'applique-t-elle à tous les types de blocage ?
Google ne différencie pas dans cette déclaration entre un blocage robots.txt, une balise noindex, ou une page sous authentification. L'effet reste le même : les liens deviennent non pertinents.
C'est une simplification qui pose question — notamment pour les pages noindex crawlables, où les liens peuvent théoriquement être suivis. Mais la position officielle reste ferme : pas d'accès utilisateur = pas de valeur de lien.
- Une page bloquée équivaut à une page inexistante pour Google
- Les liens sur pages bloquées perdent leur capacité de recommandation
- Les pages orphelines (accessibles uniquement via des liens bloqués) risquent de ne jamais être indexées
- Cette règle s'applique quel que soit le type de blocage (robots.txt, noindex, authentification)
Avis d'un expert SEO
Cette déclaration est-elle totalement cohérente avec les observations terrain ?
Globalement, oui — mais avec des nuances importantes. Sur les sites que j'ai audités, les pages accessibles uniquement via des liens sur pages bloquées affichent effectivement des taux d'indexation catastrophiques.
Là où ça coince : Google ne précise pas si un lien depuis une page en noindex crawlable conserve une valeur. Techniquement, Googlebot peut suivre ce lien. Dans la pratique, les tests montrent que la transmission de PageRank reste possible, mais largement affaiblie. [À vérifier] pour chaque configuration spécifique.
Quelles sont les conséquences réelles sur le crawl budget ?
Si Google considère les liens non pertinents, il ne consacrera pas de ressources à les suivre activement. Sur un gros site, cela peut créer un goulet d'étranglement majeur.
Le problème devient critique quand des pages importantes se retrouvent à plusieurs clics de la home, uniquement accessibles via des zones bloquées. Google peut mettre des semaines — voire des mois — à les découvrir, si tant est qu'il y parvienne.
Dans quels cas cette règle pose-t-elle des problèmes spécifiques ?
Les sites e-commerce avec des facettes de navigation bloquées en souffrent particulièrement. Si vos fiches produits ne sont accessibles que via ces facettes, elles deviennent invisibles.
Même constat pour les sites avec des zones membres. Si des articles publics ne sont liés que depuis des pages sous authentification, leur découverte organique s'effondre. Soyons honnêtes : beaucoup de sites font cette erreur sans s'en rendre compte.
Impact pratique et recommandations
Comment identifier les pages orphelines à cause de blocages ?
Commencez par crawler votre site avec les mêmes restrictions que Googlebot. Screaming Frog ou Sitebulb peuvent simuler le respect du robots.txt et des balises noindex.
Comparez ensuite ce crawl avec un crawl sans restriction. Les pages présentes dans le second mais absentes du premier sont potentiellement orphelines pour Google. Vérifiez si elles reçoivent des liens depuis des pages indexables.
Quelles erreurs faut-il absolument éviter ?
Ne bloquez jamais une page qui sert de hub de navigation critique — même si elle semble peu pertinente pour les utilisateurs. Les conséquences en cascade peuvent être dévastatrices.
Évitez aussi de créer des dépendances structurelles. Si une catégorie entière ne reçoit des liens internes que depuis des pages en noindex, vous sabotez votre propre indexation.
Que faut-il mettre en place concrètement ?
Assurez-vous que toutes vos pages stratégiques reçoivent au moins un lien depuis une page crawlable et indexable. Idéalement, depuis la home ou une page de niveau 1.
Pour les sites complexes, créez un maillage interne redondant : plusieurs chemins d'accès vers chaque page importante. Cela réduit les risques d'orphelinage accidentel.
- Crawler votre site avec les restrictions Googlebot pour identifier les orphelines
- Vérifier que chaque page stratégique reçoit au moins un lien depuis une page indexable
- Éliminer les dépendances structurelles vers des pages bloquées
- Créer des chemins de navigation redondants pour les contenus prioritaires
- Documenter les règles de blocage et leur impact sur le maillage interne
- Auditer régulièrement les logs serveur pour détecter les zones sous-crawlées
❓ Questions frequentes
Un lien depuis une page en noindex crawlable transmet-il du PageRank ?
Les pages présentes uniquement dans le sitemap XML seront-elles indexées si elles n'ont pas de liens internes ?
Faut-il bloquer les pages de filtres et facettes en e-commerce ?
Comment gérer les pages sous authentification qui contiennent des liens vers du contenu public ?
Un blocage temporaire via robots.txt a-t-il le même impact qu'un noindex permanent ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.