Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Faut-il paniquer si votre hreflang disparaît temporairement pendant une migration ?
- □ Faut-il bloquer GoogleOther ou risquer d'impacter ses services Google ?
- □ Les domaines locaux (ccTLD) offrent-ils vraiment un avantage SEO pour le référencement local ?
- □ Pourquoi Google traite-t-il un site après expansion massive comme un tout nouveau site web ?
- □ Pourquoi Google continue-t-il d'afficher l'ancien nom de votre site après un rebranding ?
- □ Faut-il vraiment corriger toutes les erreurs d'indexation signalées dans la Search Console ?
- □ Comment exploiter l'API du tableau de bord de statut Google Search pour vos outils SEO ?
- □ Pourquoi vos données structurées produits n'apparaissent-elles pas dans les résultats enrichis ?
- □ Pourquoi Google refuse-t-il les requêtes d'indexation illimitées dans Search Console ?
- □ Marque confondue avec un mot courant : faut-il vraiment attendre des mois sans rien faire ?
- □ Comment masquer du texte à Google en bloquant le JavaScript qui le contient ?
- □ Peut-on vraiment utiliser le Schema Recipe pour n'importe quel type de recette ?
- □ Google peut-il transférer vos rankings SEO lors d'une migration de domaine ?
- □ Faut-il vraiment remplir tous les champs des données structurées pour que Google les prenne en compte ?
- □ Les flux RSS sont-ils vraiment exploités par Google pour l'exploration et l'indexation ?
- □ Pourquoi votre nouveau favicon met-il autant de temps à apparaître dans les résultats Google ?
- □ L'ordre des balises H1, H2, H3 influence-t-il vraiment le classement Google ?
- □ Les liens sur pages bloquées au crawl perdent-ils vraiment toute leur valeur SEO ?
- □ Faut-il vraiment structurer ses sitemaps selon des règles précises ou peut-on faire n'importe quoi ?
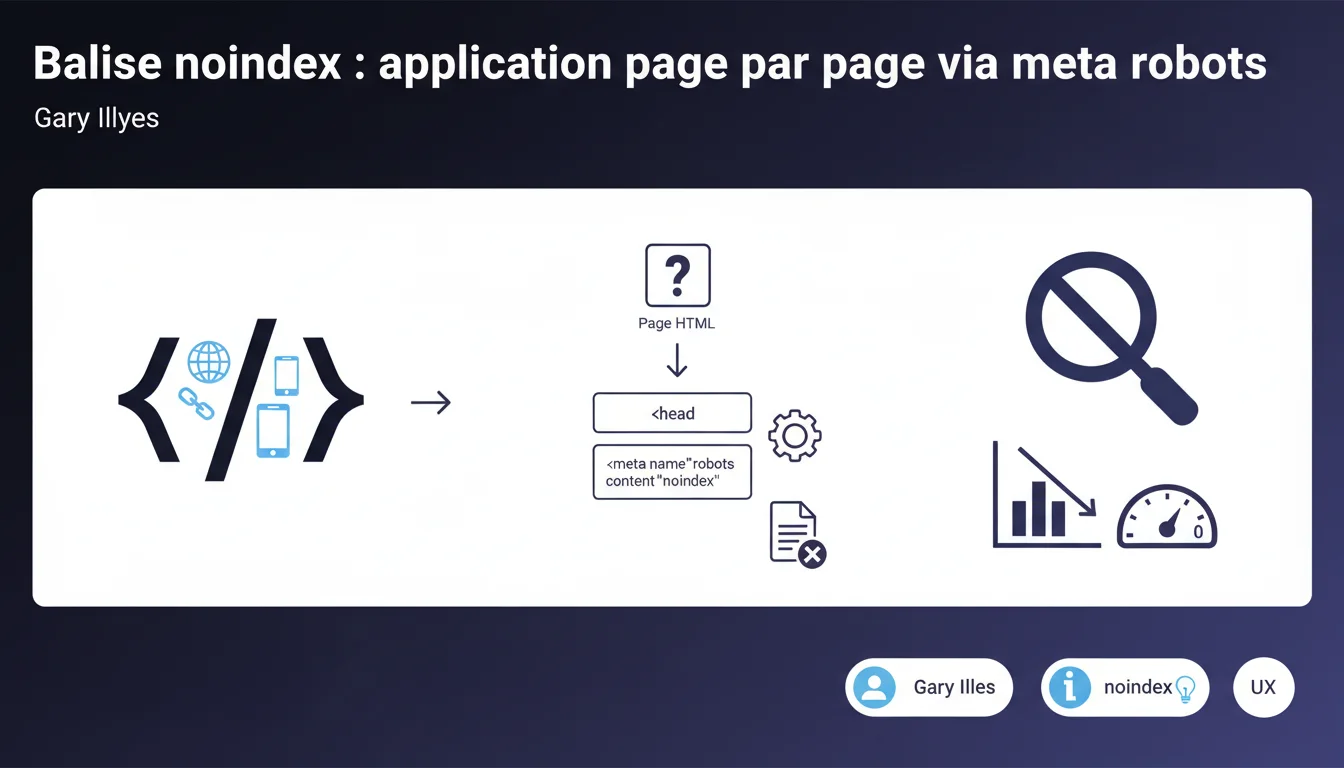
Google confirme que la directive noindex s'applique uniquement aux ressources individuelles, jamais au niveau du site entier. Pour bloquer l'indexation d'une page HTML, il faut ajouter une balise meta robots avec la valeur noindex dans la section <head>. Chaque page nécessite sa propre implémentation — aucun effet de cascade automatique.
Ce qu'il faut comprendre
Pourquoi Google insiste-t-il sur l'application page par page ?
Cette précision n'est pas anodine. Google veut éviter toute confusion : une directive noindex sur une page n'affecte jamais les autres pages du site. C'est un verrou de sécurité pour éviter qu'une erreur de configuration ne déindexe tout un domaine.
Contrairement au robots.txt qui peut bloquer des sections entières, le noindex reste granulaire. Chaque ressource ciblée doit porter explicitement cette instruction. Si vous avez 50 pages à désindexer, il faut 50 implémentations distinctes.
Quelle est la différence entre meta robots et l'en-tête HTTP X-Robots-Tag ?
Les deux méthodes sont équivalentes en termes d'efficacité, mais pas en termes de praticité. La balise meta se place directement dans le HTML, accessible via le CMS. L'en-tête HTTP X-Robots-Tag se configure au niveau serveur et convient mieux aux fichiers non-HTML (PDF, images).
Gary mentionne la balise meta parce que c'est la méthode la plus courante pour les pages web classiques. Mais techniquement, vous pouvez aussi envoyer un en-tête HTTP avec la même directive — Google traitera les deux de manière identique.
Le noindex s'applique-t-il instantanément ?
Non. Google doit d'abord crawler la page pour découvrir la directive. Si vous bloquez le crawl via robots.txt, Googlebot ne verra jamais la balise noindex et la page restera indexée. C'est un piège classique.
Une fois la directive détectée, le délai de désinexation varie selon la fréquence de crawl du site. Pour une page importante recrawlée quotidiennement, comptez quelques jours. Pour une page marginale, ça peut prendre des semaines.
- Une directive noindex ne s'applique qu'à une seule ressource, jamais à l'ensemble du site
- Deux méthodes équivalentes : balise meta robots dans le HTML ou en-tête HTTP X-Robots-Tag
- La page doit rester crawlable pour que Google détecte la directive noindex
- Le délai de désinexation dépend de la fréquence de crawl de la page concernée
- Aucun effet de cascade : chaque page nécessite sa propre implémentation
Avis d'un expert SEO
Cette déclaration est-elle alignée avec ce qu'on observe sur le terrain ?
Totalement. Aucune surprise ici — c'est le comportement documenté depuis des années et confirmé par les tests. La vraie question, c'est pourquoi Google ressent le besoin de le rappeler maintenant.
Soit il y a une vague de confusion récente dans la communauté, soit Google anticipe des erreurs liées à de nouvelles fonctionnalités de CMS. Dans tous les cas, le message est clair : pas de raccourci, pas de magie. Vous voulez bloquer 100 pages ? Vous implémentez 100 balises.
Quelles nuances faut-il apporter à cette affirmation ?
Gary ne mentionne pas les cas limites qui posent problème. Exemple : une page avec noindex qui contient des liens vers d'autres pages. Ces liens internes transmettent-ils du PageRank ? [A vérifier] selon les dernières observations — certains tests suggèrent que le PageRank circule encore temporairement, d'autres non.
Autre angle mort : le comportement en cas de directives conflictuelles. Si vous avez un noindex dans la balise meta ET un index dans l'en-tête HTTP, lequel l'emporte ? Google a dit que la directive la plus restrictive gagne, mais les confirmations empiriques manquent.
Enfin, Gary parle de « pages HTML », mais qu'en est-il des ressources JavaScript générées côté client ? Si la balise noindex apparaît après exécution du JS, Google la prend-elle en compte ? Sur du rendu dynamique pur, les observations terrain montrent une fiabilité variable.
Dans quels cas cette règle ne s'applique-t-elle pas comme prévu ?
Premier cas problématique : les sites avec des millions de pages. Ajouter manuellement une balise noindex sur chaque URL devient ingérable. Les solutions programmatiques via templates CMS ou règles serveur sont indispensables, mais introduisent des risques d'erreur de masse.
Deuxième cas : les pages avec redirections 301. Si une page A avec noindex redirige vers une page B sans noindex, Google peut encore indexer B en fonction du contexte. La directive ne « suit » pas la redirection — elle meurt avec la page source.
Troisième cas : les pages noindex qui reçoivent des backlinks puissants. Vous perdez le PageRank de ces liens entrants, mais Google peut quand même les explorer et suivre les liens sortants. Résultat : vous gaspillez du jus de lien sans vraiment contrôler le budget de crawl.
Impact pratique et recommandations
Que faut-il faire concrètement pour implémenter correctement le noindex ?
D'abord, auditer toutes les pages que vous voulez exclure de l'index. Exportez une liste depuis votre CMS, votre sitemap ou un crawl Screaming Frog. Classez-les par type : pagination, pages filtrées, contenus dupliqués, pages de test.
Ensuite, choisissez la méthode d'implémentation. Pour des pages HTML standards gérées par un CMS, la balise meta robots est la plus simple. Pour des fichiers PDF ou des ressources non-HTML, préférez l'en-tête HTTP X-Robots-Tag configuré au niveau serveur.
Enfin, vérifiez que ces pages restent crawlables. Parcourez votre robots.txt pour vous assurer qu'aucune règle Disallow ne bloque les URLs concernées. Un Disallow empêche Google de voir la directive noindex — la page reste alors indexée avec un snippet vide.
Quelles erreurs éviter absolument ?
Erreur numéro un : bloquer dans le robots.txt une page marquée noindex. Google ne pourra jamais crawler la page pour découvrir la directive, et elle restera indexée indéfiniment avec le message « bloqué par robots.txt ».
Erreur numéro deux : ajouter noindex sur des pages stratégiques par accident. Ça arrive plus souvent qu'on ne le pense, surtout lors de migrations ou de refonte de templates. Un noindex sur une catégorie principale peut faire chuter le trafic de 30% en quelques jours.
Erreur numéro trois : utiliser noindex comme solution de facilité pour gérer le contenu dupliqué. La canonicalisation est souvent plus pertinente. Le noindex supprime la page de l'index, mais ne transfère pas les signaux vers une version préférentielle — vous perdez tout le potentiel SEO.
Comment vérifier que la directive est bien prise en compte ?
Utilisez l'outil d'inspection d'URL de la Search Console. Il indique si Googlebot a détecté la balise noindex lors du dernier crawl. Si la page apparaît encore dans l'index malgré la directive, demandez une ré-indexation pour forcer un nouveau crawl.
Lancez aussi un crawl avec un outil comme Screaming Frog en activant le mode « Spider » pour simuler Googlebot. Vérifiez que toutes les pages ciblées renvoient bien la directive noindex, soit dans le HTML, soit dans l'en-tête HTTP.
Enfin, surveillez régulièrement la Search Console pour détecter les exclusions inattendues. La section « Pages exclues » liste toutes les URLs bloquées par noindex. Si une page stratégique y apparaît, c'est un signal d'alerte immédiat.
- Auditer et lister précisément toutes les pages à exclure de l'index
- Implémenter la balise meta robots avec noindex dans le
<head>de chaque page HTML - Vérifier que ces pages restent crawlables (non bloquées par robots.txt)
- Utiliser l'en-tête HTTP X-Robots-Tag pour les ressources non-HTML (PDF, images)
- Contrôler l'implémentation via l'outil d'inspection d'URL de la Search Console
- Crawler le site régulièrement pour détecter les noindex accidentels sur des pages stratégiques
- Surveiller la section « Pages exclues » de la Search Console pour identifier les anomalies
- Préférer la canonicalisation au noindex pour gérer le contenu dupliqué quand c'est pertinent
La gestion granulaire du noindex demande rigueur et vigilance permanente. Chaque page nécessite une attention individuelle, et une erreur d'implémentation peut impacter sérieusement la visibilité du site. Les audits réguliers sont indispensables pour maintenir la cohérence entre la stratégie d'indexation et la réalité technique.
Pour les sites complexes ou les équipes qui manquent de ressources internes, ces optimisations peuvent rapidement devenir chronophages et techniques. Faire appel à une agence SEO spécialisée permet de sécuriser l'implémentation, d'éviter les erreurs coûteuses et de bénéficier d'un suivi proactif adapté aux spécificités de votre architecture.
❓ Questions frequentes
Peut-on utiliser noindex via le robots.txt ?
Le noindex empêche-t-il le crawl de la page ?
Combien de temps faut-il pour qu'une page noindex disparaisse de l'index ?
Une page noindex transmet-elle du PageRank ?
Que se passe-t-il si une page a noindex dans la balise meta ET index dans l'en-tête HTTP ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/07/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.