Declaration officielle
Autres déclarations de cette vidéo 29 ▾
- □ Un fichier robots.txt volumineux pénalise-t-il vraiment votre SEO ?
- □ Soumettre son sitemap dans robots.txt ou Search Console : y a-t-il vraiment une différence ?
- □ Les balises H1-H6 ont-elles encore un impact réel sur le classement Google ?
- □ Faut-il vraiment respecter une hiérarchie stricte des balises Hn pour le SEO ?
- □ Combien de temps faut-il réellement pour qu'une migration de domaine soit prise en compte par Google ?
- □ Une migration de site peut-elle vraiment booster votre SEO ou tout faire planter ?
- □ Googlebot crawle-t-il vraiment depuis un seul endroit pour indexer vos contenus géolocalisés ?
- □ Le noindex sur pages géolocalisées peut-il faire disparaître tout votre site des résultats Google ?
- □ Faut-il vraiment abandonner les redirections géolocalisées pour une simple bannière ?
- □ Faut-il créer des pages de destination pour chaque ville ou se limiter aux régions ?
- □ Faut-il rediriger les utilisateurs mobiles vers votre application mobile ?
- □ Faut-il vraiment traduire mot pour mot ses pages pour que le hreflang fonctionne ?
- □ Fichier Disavow : pourquoi la directive domaine permet-elle de contourner la limite de 2MB ?
- □ Faut-il vraiment utiliser le fichier Disavow uniquement pour les liens achetés ?
- □ Faut-il mettre en noindex ses pages de résultats de recherche interne pour bloquer les backlinks spam ?
- □ Le HTML sémantique booste-t-il vraiment votre référencement naturel ?
- □ AMP est-il encore un critère de ranking dans Google Search ?
- □ AMP est-il vraiment un facteur de classement pour Google ?
- □ Supprimer AMP boost-t-il le crawl de vos pages classiques ?
- □ Faut-il tester la suppression de son fichier Disavow de manière incrémentale ?
- □ Pourquoi les panels de connaissance s'affichent-ils différemment selon les appareils ?
- □ Le système de synonymes de Google fonctionne-t-il vraiment sans intervention humaine ?
- □ Faut-il vraiment créer une page distincte par localisation pour le schema Local Business ?
- □ Faut-il vraiment marquer TOUT son contenu en données structurées ?
- □ Faut-il vraiment afficher toutes les questions du schema FAQ sur la page ?
- □ Le contenu masqué dans les accordéons peut-il vraiment apparaître dans les featured snippets ?
- □ Faut-il supprimer des pages pour améliorer l'indexation de son site ?
- □ Le volume de recherche des ancres influence-t-il vraiment la valeur d'un lien interne ?
- □ Faut-il vraiment ajouter du contenu unique sur vos pages produit en e-commerce ?
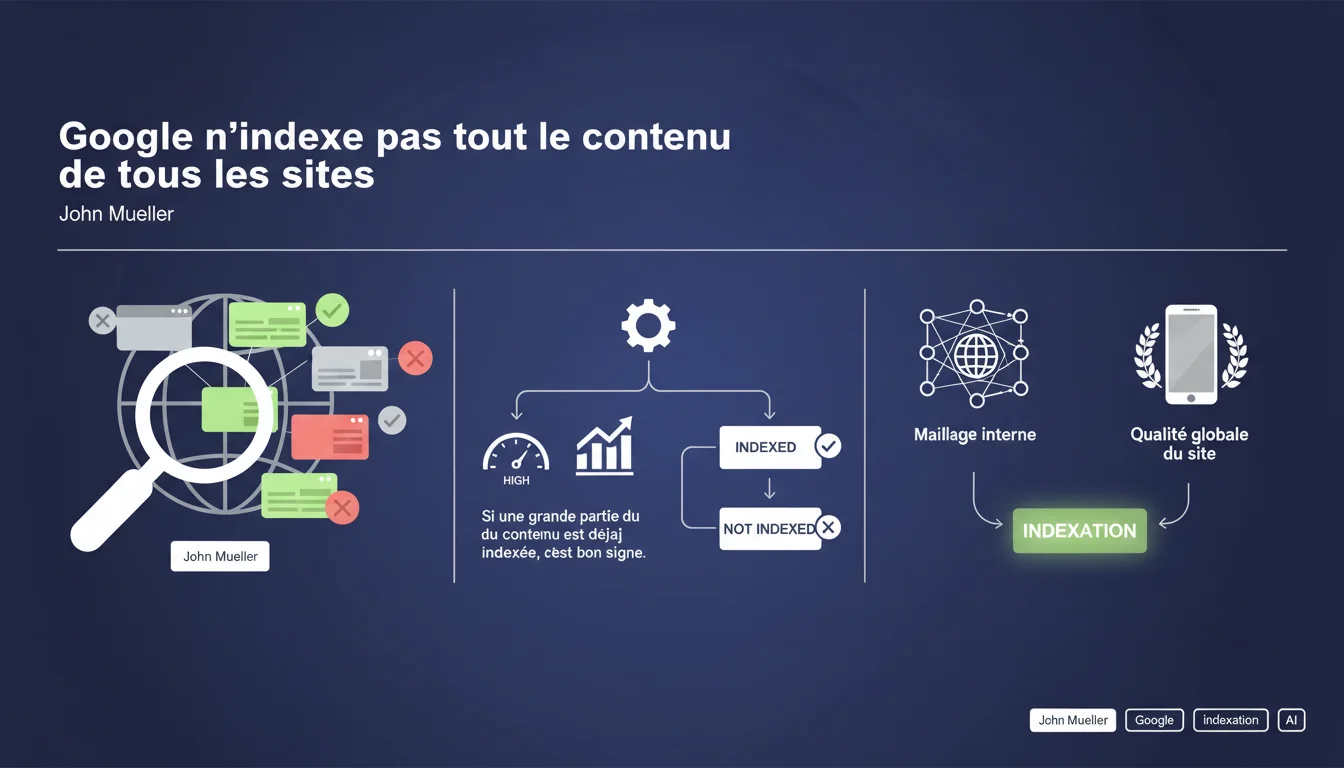
Google assume ouvertement qu'il n'indexe pas tout le contenu de tous les sites, et considère cette sélectivité comme normale. Si une grande partie de vos pages est déjà dans l'index, c'est suffisant selon Mountain View. Le maillage interne et la qualité globale restent les leviers principaux pour améliorer le taux d'indexation.
Ce qu'il faut comprendre
Google fait-il réellement un tri sélectif dans vos contenus ?
Oui, et Mueller le confirme sans détour. Google ne considère pas l'indexation exhaustive comme un objectif. Le moteur opère une sélection basée sur des critères de qualité, de pertinence et de ressources disponibles.
Cette déclaration officialise ce que beaucoup observent sur le terrain : des pages techniquement crawlables qui ne passent jamais en index, des contenus mis à jour qui disparaissent mystérieusement, des URLs soumises via Search Console qui restent en "Discovered - currently not indexed".
Qu'est-ce qui détermine si une page mérite l'indexation ?
Mueller évoque deux axes principaux : le maillage interne et la qualité globale du site. Traduction concrète : Google évalue si une page apporte quelque chose d'unique et si votre architecture lui donne suffisamment de poids dans votre écosystème.
Le crawl budget entre aussi en jeu, même si ce n'est pas explicitement mentionné ici. Plus votre site est volumineux, plus Google devient sélectif. C'est mathématique.
Quel taux d'indexation considérer comme acceptable ?
"Une grande partie" suffit selon Mueller. Mais il ne donne aucun chiffre précis — 70% ? 85% ? 95% ? Cette absence de seuil laisse le praticien SEO dans le flou total.
Ce qu'on peut déduire : si vous avez 10 000 pages et que 2 000 seulement sont indexées, il y a clairement un problème structurel. Mais entre 7 000 et 9 500 indexées, Google considère probablement que tout va bien.
- L'indexation partielle est la norme, pas une anomalie à corriger à tout prix
- Le maillage interne impacte directement les chances d'indexation d'une page
- La qualité globale du site influence la sélectivité de Google sur vos contenus
- Aucun seuil chiffré n'est communiqué pour définir un taux d'indexation satisfaisant
Avis d'un expert SEO
Cette position de Google est-elle cohérente avec les observations terrain ?
Partiellement. On observe effectivement que Google indexe de moins en moins systématiquement. Les sites e-commerce avec milliers de fiches produits, les médias avec archives profondes, les sites multilingues — tous font face à cette sélectivité accrue.
Mais la justification par "la qualité" reste floue. Des pages de haute qualité, bien maillées, techniquement propres restent parfois hors index sans raison apparente [À vérifier]. La vraie raison ? Probablement un mix entre économie de ressources chez Google et lutte contre l'inflation de contenu médiocre sur le web.
Quelles zones d'ombre subsistent dans cette déclaration ?
Mueller ne dit pas comment Google détermine qu'une "grande partie" est indexée. Il ne précise pas non plus ce qui relève de la qualité objective versus la perception algorithmique de cette qualité.
Autre point crucial : il n'évoque pas les contenus dupliqués ou quasi-dupliqués, pourtant responsables d'une large part des non-indexations. Silence aussi sur le rôle du temps : une page peut-elle entrer en index plusieurs semaines après publication si la qualité globale s'améliore ?
Dans quels cas cette logique de sélectivité pose-t-elle vraiment problème ?
Pour les sites d'actualité qui ont besoin d'indexation rapide. Pour les marketplaces avec inventaire dynamique. Pour les sites SaaS avec documentation produit détaillée. Tous ces modèles nécessitent une indexation quasi-exhaustive pour fonctionner.
Le discours de Mueller s'applique mieux aux blogs, sites vitrine, ou contenus informationnels classiques. Mais dès qu'on parle de sites transactionnels ou à forte temporalité, cette sélectivité devient un frein commercial direct.
Impact pratique et recommandations
Comment maximiser vos chances d'indexation sur les pages prioritaires ?
Identifiez d'abord vos pages stratégiques — celles qui génèrent du trafic, des conversions ou du chiffre. Ce sont elles qui doivent absolument être indexées. Le reste peut attendre, voire ne jamais l'être.
Ensuite, concentrez vos efforts de maillage sur ces URLs critiques. Pas depuis le footer avec 500 autres liens, mais depuis des contenus éditoriaux pertinents, en contexte sémantique cohérent. Un lien contextuel vaut 10 liens footer.
Quelles erreurs courantes aggravent le problème d'indexation sélective ?
Créer des milliers de pages à faible valeur ajoutée. Google filtre impitoyablement. Si 40% de votre site sont des pages catégories quasi-vides ou des tags générés automatiquement, vous polluez votre propre crawl budget.
Autre piège : le maillage plat. Tout lier à tout depuis une méga-navigation ne donne aucun signal de hiérarchie à Google. Le moteur ne sait plus ce qui compte vraiment chez vous.
Que faire si des pages importantes restent désindexées malgré tout ?
Vérifiez d'abord les basiques : robots.txt, balises noindex, canoniques mal placées. Ça paraît évident, mais c'est encore la cause n°1 de non-indexation.
Si la technique est propre, regardez si ces pages reçoivent suffisamment de jus interne. Utilisez Screaming Frog ou Oncrawl pour visualiser la distribution du PageRank interne. Les pages orphelines ou à 5+ clics de la home ont peu de chances.
- Cartographier les pages absolument critiques pour le business (top 20%)
- Renforcer le maillage interne vers ces URLs prioritaires avec ancres contextuelles
- Élaguer les contenus faibles qui diluent le crawl budget sans ROI
- Vérifier la profondeur de crawl : pages stratégiques à maximum 3 clics de la home
- Monitorer l'évolution du taux d'indexation via Search Console, pas juste le volume absolu
- Éviter le maillage générique (footer, sidebar) comme principal vecteur de lien interne
- Analyser les logs serveur pour identifier les pages crawlées mais non indexées
❓ Questions frequentes
Quel pourcentage d'indexation est considéré comme normal par Google ?
Le fait de soumettre des URLs via Search Console garantit-il leur indexation ?
Faut-il bloquer les pages peu importantes pour améliorer le crawl budget ?
Le maillage interne peut-il vraiment forcer l'indexation d'une page ?
Pourquoi certaines pages disparaissent de l'index alors qu'elles étaient indexées ?
🎥 De la même vidéo 29
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 14/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.