Declaration officielle
Autres déclarations de cette vidéo 8 ▾
- □ Les Core Web Vitals sont-ils vraiment un outil de diagnostic UX ou juste un critère de ranking ?
- □ Pourquoi Google insiste-t-il sur les données utilisateurs réels pour mesurer la performance SEO ?
- □ Pourquoi Google privilégie-t-il les données lab pour le débogage SEO ?
- □ Lighthouse est-il vraiment l'outil de référence pour diagnostiquer les problèmes de performance ?
- □ Pourquoi Lighthouse ne détecte-t-il pas tous vos problèmes de Core Web Vitals ?
- □ Pourquoi le performance panel Chrome DevTools change-t-il la donne pour le debug des Core Web Vitals ?
- □ Les données de laboratoire peuvent-elles remplacer les données terrain pour optimiser l'UX ?
- □ Faut-il vraiment tester les Core Web Vitals en laboratoire plutôt qu'en production ?
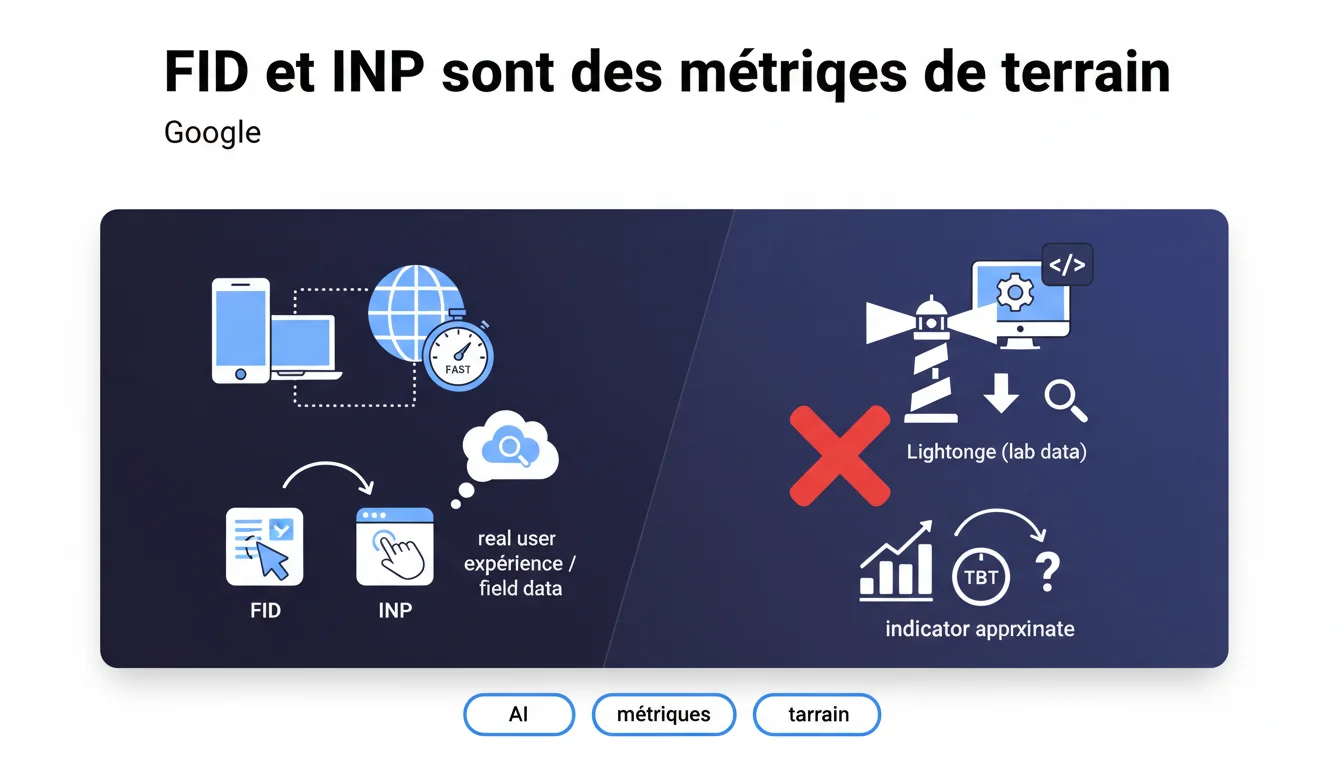
Google rappelle que FID et INP sont des métriques terrain impossibles à capturer fidèlement avec Lighthouse. L'outil utilise le Total Blocking Time comme approximation, ce qui signifie qu'un bon score Lighthouse ne garantit pas une expérience utilisateur réelle satisfaisante. Les données CrUX restent la seule référence fiable pour évaluer la réactivité perçue par vos visiteurs.
Ce qu'il faut comprendre
Quelle différence fondamentale existe entre métriques terrain et métriques lab ?
Les métriques terrain (field metrics) capturent l'expérience réelle des utilisateurs sur des appareils variés, des connexions diverses, avec des comportements imprévisibles. Le FID (First Input Delay) mesure le délai avant la première interaction, l'INP (Interaction to Next Paint) évalue la réactivité globale sur toute la session.
Lighthouse, lui, tourne dans un environnement contrôlé et reproductible. Impossible de simuler un vrai clic utilisateur au bon moment, sur le bon élément, avec la charge CPU exacte d'un smartphone moyen de gamme sous Chrome avec 12 onglets ouverts. Le lab donne une tendance — le terrain livre la vérité.
Pourquoi Google utilise-t-il le Total Blocking Time comme proxy ?
Le TBT (Total Blocking Time) mesure le temps cumulé pendant lequel le thread principal est bloqué entre le FCP et le TTI. C'est un indicateur disponible en environnement lab, corrélé statistiquement avec FID et INP — mais c'est une approximation, pas une équivalence.
Un site avec un TBT élevé aura probablement des problèmes d'INP terrain. Mais l'inverse n'est pas garanti : vous pouvez afficher un TBT correct en lab et subir des blocages massifs en production à cause d'un script tiers qui charge différemment selon le contexte utilisateur.
Quelles données devez-vous surveiller en priorité ?
- CrUX (Chrome User Experience Report) : la seule source de données terrain validée par Google pour le classement
- RUM (Real User Monitoring) : vos propres métriques terrain via Analytics ou solutions dédiées
- Lighthouse/PageSpeed Insights : indicateurs diagnostiques pour identifier des pistes d'optimisation, jamais une vérité absolue
- Search Console : rapport Core Web Vitals basé sur CrUX, avec distribution 75e percentile
Avis d'un expert SEO
Cette distinction lab/terrain est-elle vraiment nouvelle ?
Non — et c'est justement ce qui interpelle. Google martèle ce message depuis l'introduction des Core Web Vitals en 2020. Si cette précision revient aujourd'hui, c'est probablement parce que trop de praticiens optimisent encore uniquement pour Lighthouse.
Le piège classique : un site affiche 95/100 sur PageSpeed Insights, le client est ravi, mais la Search Console remonte 60% d'URLs avec un INP médiocre. Le scoring Lighthouse crée une fausse confiance — il mesure un instant T dans des conditions idéales qui ne reflètent jamais la complexité du terrain.
Le TBT est-il vraiment un bon indicateur ?
Soyons honnêtes : c'est mieux que rien, mais loin d'être suffisant. Le TBT capture les blocages pendant le chargement initial. L'INP, lui, surveille toute l'expérience utilisateur, y compris les interactions post-chargement — scrolls, clics sur des boutons, ouverture de menus.
Un cas typique où le TBT vous trompe : un site e-commerce avec lazy loading agressif. Lighthouse voit un chargement initial propre, TBT faible. Mais dès que l'utilisateur scroll, un déluge de scripts s'exécute, les images chargent, les trackers se déclenchent — et l'INP explose. [À vérifier] sur vos propres données CrUX si vous constatez cette divergence.
Faut-il ignorer Lighthouse pour autant ?
Absolument pas. Lighthouse reste un outil diagnostique précieux pour identifier des quick wins : JavaScript bloquant, images non optimisées, polices web mal chargées. Mais il ne doit jamais être votre unique référence.
Impact pratique et recommandations
Que faut-il surveiller concrètement chaque semaine ?
Oubliez le réflexe "je lance Lighthouse". Connectez-vous à la Search Console, section Core Web Vitals. Regardez la distribution INP sur mobile (c'est là que ça se joue). Si plus de 25% de vos URLs sont en rouge, vous avez un problème de classement potentiel.
Complétez avec PageSpeed Insights en mode "Discover what your real users are experiencing" — ça affiche les données CrUX pour votre origine. Comparez avec les résultats lab pour identifier les écarts. Un écart massif signale que votre environnement de production diffère significativement des conditions de test.
Comment diagnostiquer un INP dégradé en production ?
Le TBT Lighthouse vous donne une première piste, mais il faut aller plus loin. Installez une solution de RUM (Real User Monitoring) — web-vitals.js de Google est gratuit et s'intègre en 10 minutes. Vous verrez quelles interactions spécifiques posent problème, sur quels appareils, à quels moments.
Analysez les long tasks avec les DevTools Performance en conditions réalistes : throttling CPU 4x, connexion 3G lente, mode mobile. Tracez les event handlers qui bloquent le thread principal pendant plus de 50ms. C'est là que se cachent 80% des problèmes d'INP.
Quelles actions prioritaires mettre en place ?
- Passer d'une optimisation "score Lighthouse" à une optimisation "données CrUX terrain"
- Monitorer INP avec RUM ou web-vitals.js sur toutes les pages clés
- Fragmenter le JavaScript : code splitting, lazy loading des modules non critiques
- Différer les scripts tiers non essentiels au chargement initial (analytics, chat, widgets sociaux)
- Utiliser des Web Workers pour déporter les calculs lourds hors du thread principal
- Tester en conditions réelles : vrais devices, vraies connexions, vrais scénarios utilisateur
- Auditer les event listeners : débounce, throttle, passive listeners quand approprié
L'écart entre performances lab et terrain révèle souvent une dette technique invisible : scripts legacy, dépendances non optimisées, architectures front mal pensées. Ces chantiers demandent une expertise pointue en performance web — identifier les bottlenecks, prioriser les interventions, mesurer l'impact réel sans casser l'existant.
Si votre équipe manque de ressources ou de compétences spécifiques sur ces sujets, faire appel à une agence SEO spécialisée en optimisation technique peut accélérer significativement vos résultats tout en évitant les faux pas coûteux.
❓ Questions frequentes
Le score Lighthouse a-t-il encore une utilité pour le SEO ?
Quelle métrique remplace le FID dans les Core Web Vitals ?
Comment obtenir des données CrUX si mon site a peu de trafic ?
Un bon TBT garantit-il un bon INP en production ?
Faut-il optimiser pour mobile ou desktop en priorité ?
🎥 De la même vidéo 8
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/08/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.