Official statement
What you need to understand
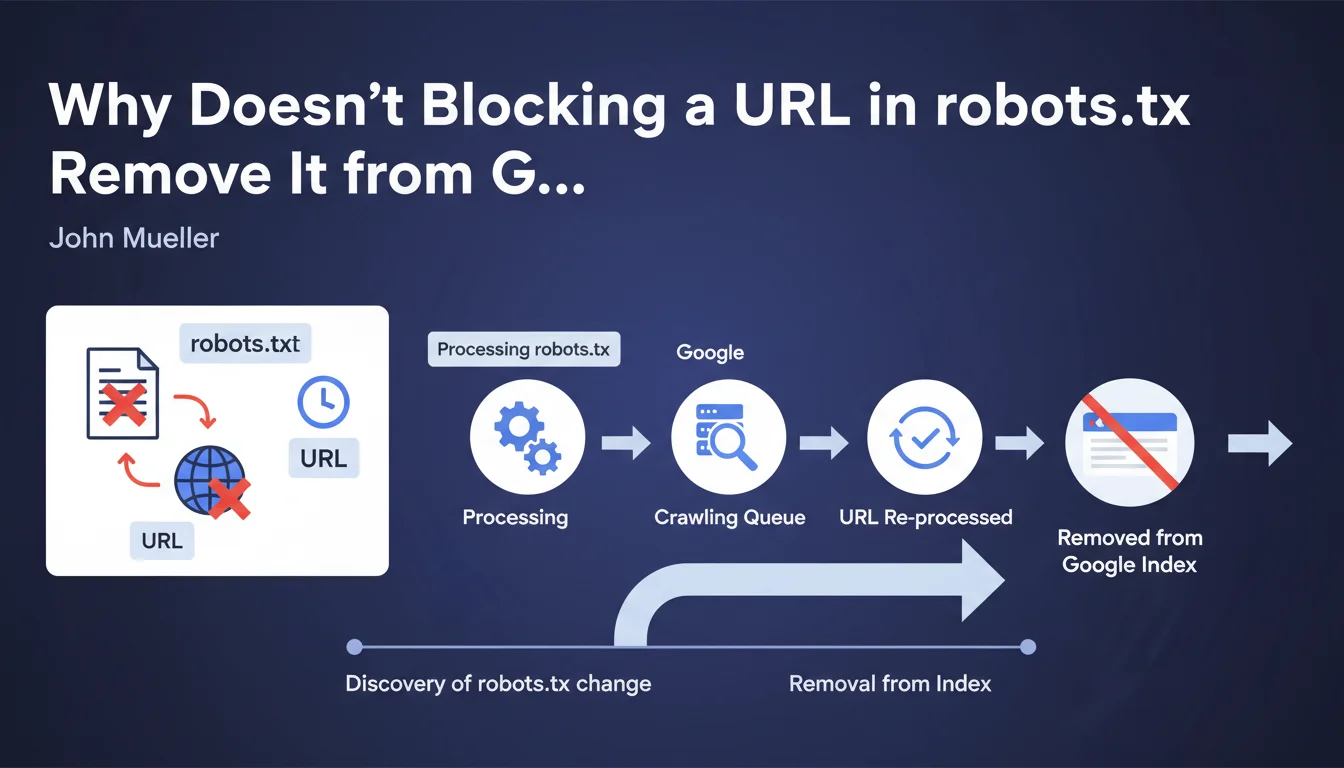
When an SEO practitioner adds an exclusion directive to the robots.txt file, they often expect the affected URLs to disappear quickly from the Google index. The reality is different.
Google does not instantly remove URLs the moment the modified robots.txt is discovered. The process occurs in two distinct stages: first Google must detect and process the new robots.txt, then each affected URL must be individually reprocessed by the crawl bots.
This individual reprocessing depends on the crawl budget allocated to the site and the priority Google assigns to each URL. A highly popular page with numerous backlinks will be recrawled more frequently than an orphaned page buried deep in the site architecture.
- Changes to robots.txt do not have an immediate effect on indexing
- Each blocked URL must be individually recrawled for the directive to apply
- The delay can vary from a few days to several months depending on the URLs
- Crawl budget and page popularity directly influence this timeframe
SEO Expert opinion
This clarification is perfectly consistent with what we have been observing in the field for years. It is not uncommon to find that a URL blocked via robots.txt remains visible in the SERPs for 2 to 3 months, or even longer for pages that are rarely crawled.
A crucial point often overlooked: blocking a URL in robots.txt is not the recommended method for removing content from the index. This approach prevents Googlebot from crawling the page, but if that page has backlinks, Google may continue to display it in search results with a generic description based on external signals only.
In practice, certain URLs benefiting from daily crawling will see the directive applied within a few days, while others with monthly crawling will logically take several months. The historical crawl frequency of your pages is the best indicator of the expected timeframe.
Practical impact and recommendations
- Never rely on robots.txt for quick or urgent deindexing – prioritize the temporary removal tool in Search Console
- Use the noindex tag rather than robots.txt if your goal is to remove pages from the index (while still allowing Google to access them to read the directive)
- Anticipate a delay of several weeks to several months for robots.txt changes to fully apply across all affected URLs
- Monitor deindexing via "site:" queries and Search Console to progressively verify that changes are being applied
- Prioritize important URLs by creating internal links to them if you want to accelerate their recrawl (if they are not blocked)
- Document your robots.txt changes with dates so you can correlate observed effects over time
- Test your robots.txt with the Search Console testing tool before publishing to avoid syntax errors that would further delay the process
Blocking via robots.txt is an asynchronous and progressive process, not an instant removal. For an effective deindexing strategy, you need to understand the difference between preventing crawling (robots.txt) and requesting deindexing (noindex).
The technical management of these directives and monitoring their implementation require specialized expertise and regular surveillance. These optimizations, while fundamental, are part of a comprehensive technical SEO strategy where every decision can have lasting repercussions. If you manage a large-scale site or need to orchestrate complex migrations, guidance from a specialized SEO agency can prove invaluable in avoiding costly mistakes and ensuring controlled execution of these delicate operations.
💬 Comments (0)
Be the first to comment.