Official statement
Other statements from this video 8 ▾
- □ Has mobile-first indexing really been a game-changer for SEO since 2016?
- □ Is the meta keywords tag still worth anything for SEO in 2025?
- □ Does using Google Analytics or Chrome really boost your SEO rankings?
- □ Does CSS really influence the SEO weight of your H1-H6 tags?
- □ How does Caffeine actually ingest Googlebot data into Google's search index?
- □ Should you really de-optimize certain pages to boost your SEO performance?
- □ Should you really optimize each Google removal tool differently for SEO?
- □ Why does Google document only one single meta tag in its official SEO guide?
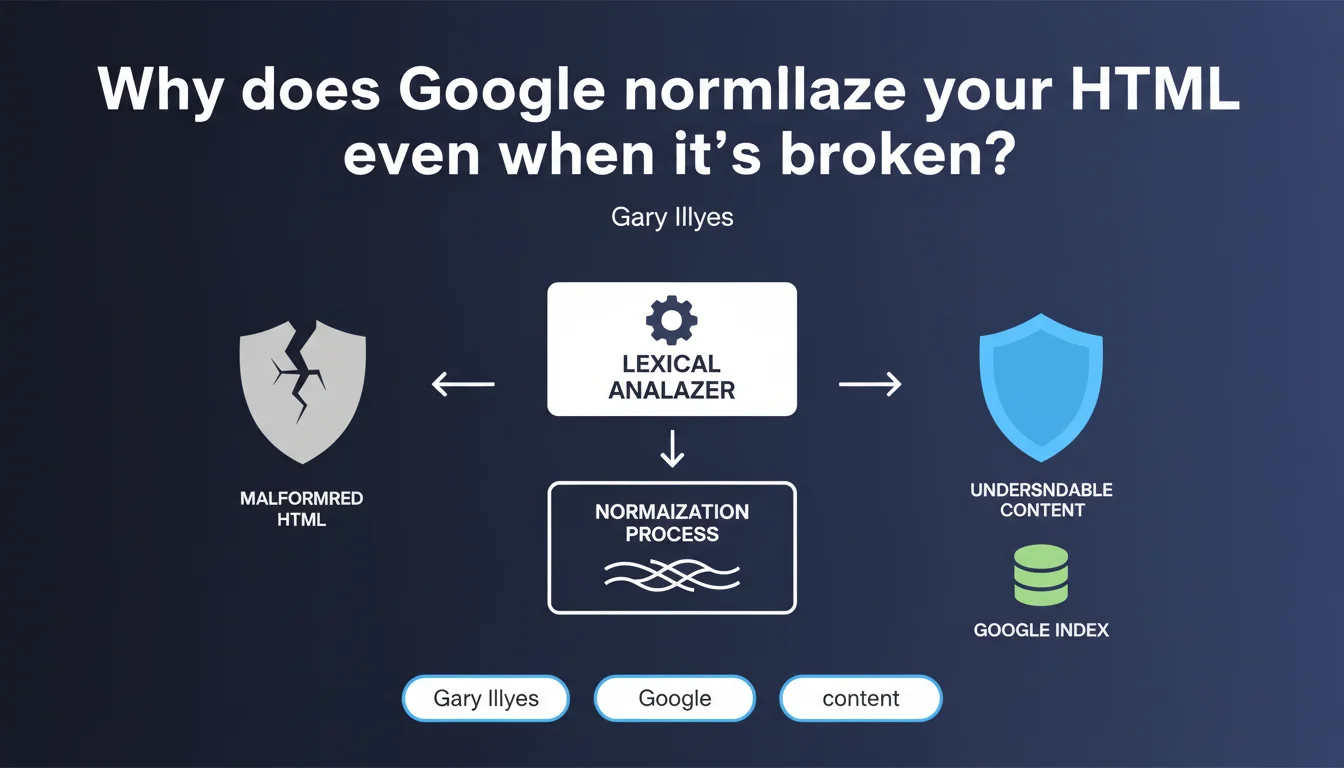
Google uses a lexical analyzer to normalize malformed HTML during indexing, since the majority of the web contains code errors. Even if your page has incorrectly closed tags or unstable structures, the search engine attempts to extract and organize content coherently. Concretely, this means your HTML errors don't necessarily condemn you — but that doesn't mean they're without consequence.
What you need to understand
What does this "normalization" of HTML actually mean in practice?
When Google crawls your page, it doesn't take the HTML as-is. It first goes through a lexical analyzer (tokenizer) that breaks down the code into understandable units: opening tags, closing tags, attributes, text content.
If your HTML is shaky — a <div> never closed, a <p> nested inside another <p>, overlapping tags — the analyzer attempts to reconstruct a logical structure. This is what we call normalization.
Why does Google do this instead of rejecting poorly coded pages?
Gary Illyes says it plainly: "The Internet is generally broken at the HTML level". Browsers have long developed error recovery mechanisms to display pages even if they're imperfect.
Google does the same — otherwise, a massive portion of the web would be unusable. But pay attention: normalizing doesn't mean interpreting correctly every time.
Does this mean we can get away with dirty code?
No. The search engine does its best, but nothing guarantees that the normalized version matches your original intent.
If your semantic tags (<article>, <section>, <header>) are poorly closed, Google may restructure the DOM in a way that dilutes your markup. Result: you lose clarity with the search engine.
- Google normalizes broken HTML to make the web indexable despite its imperfections
- This normalization goes through a lexical analyzer that reconstructs a coherent structure
- It doesn't guarantee the search engine understands your page as you intended
- HTML errors don't block indexing, but can alter perceived semantics
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, completely. We regularly see sites with catastrophic HTML that still rank. Not because the code is good, but because content and external signals compensate.
However — and this is where it gets tricky — there's a difference between "it works anyway" and "it works optimally". A site that forces Google to normalize heavily consumes more crawl budget and risks misinterpretations of semantic markup.
What nuances should we add to Google's tolerance?
Normalization doesn't fix everything. If your HTML is so broken that the analyzer can't reconstruct a clear hierarchy, you lose structural comprehension.
Concrete example: <h1> tags poorly closed that end up nested inside <span> tags. Google can normalize the DOM, but it can't guess that this <h1> was supposed to be a main title. The hierarchy is ruined.
In what cases does this tolerance become a trap?
When you rely on it to avoid cleaning up your code. Let's be honest: if your HTML needs aggressive normalization, you're letting Google interpret on your behalf.
And this interpretation can change. The search engine evolves, its normalization heuristics too. What worked two years ago can suddenly be understood differently in a parser update.
Practical impact and recommendations
What should you do concretely to limit the risks?
First, validate your HTML. You don't need to aim for absolute W3C perfection, but at least ensure that critical tags (<head>, <body>, headings, semantic tags) are properly opened and closed.
Next, test the normalized DOM as Google sees it. To do that, use the URL inspection tool in Search Console and look at the indexed source code. Compare it with your original HTML.
What errors should you avoid at all costs?
Never leave structural tags (<article>, <section>, <nav>) poorly closed or nested haphazardly. Google can normalize, but semantics get lost in the process.
Also avoid poorly escaped inline scripts that break HTML parsing around them. It's a classic that generates orphan tags and phantom attributes.
How can you verify that your site isn't suffering from problematic normalization?
Crawl your site with a tool that simulates Googlebot rendering (Screaming Frog in JavaScript mode, or directly Search Console). Compare the final DOM with your source HTML.
If you see massive reorganizations — content blocks moved, semantic tags removed or transformed — it means the parser had to force its way to make sense. There, you need to fix it.
- Validate the HTML of strategic pages with a validator (W3C or other)
- Inspect the indexed source code via Search Console to detect normalizations
- Verify that semantic tags remain coherent after parsing
- Test structured data with official tools to ensure they're being read correctly
- Crawl the site in render mode to compare source DOM and final DOM
- Fix structural errors first (unclosed tags, invalid nesting)
🎥 From the same video 8
Other SEO insights extracted from this same Google Search Central video · published on 03/11/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.