Official statement
What you need to understand
What happens when Google detects malformed HTML attributes?
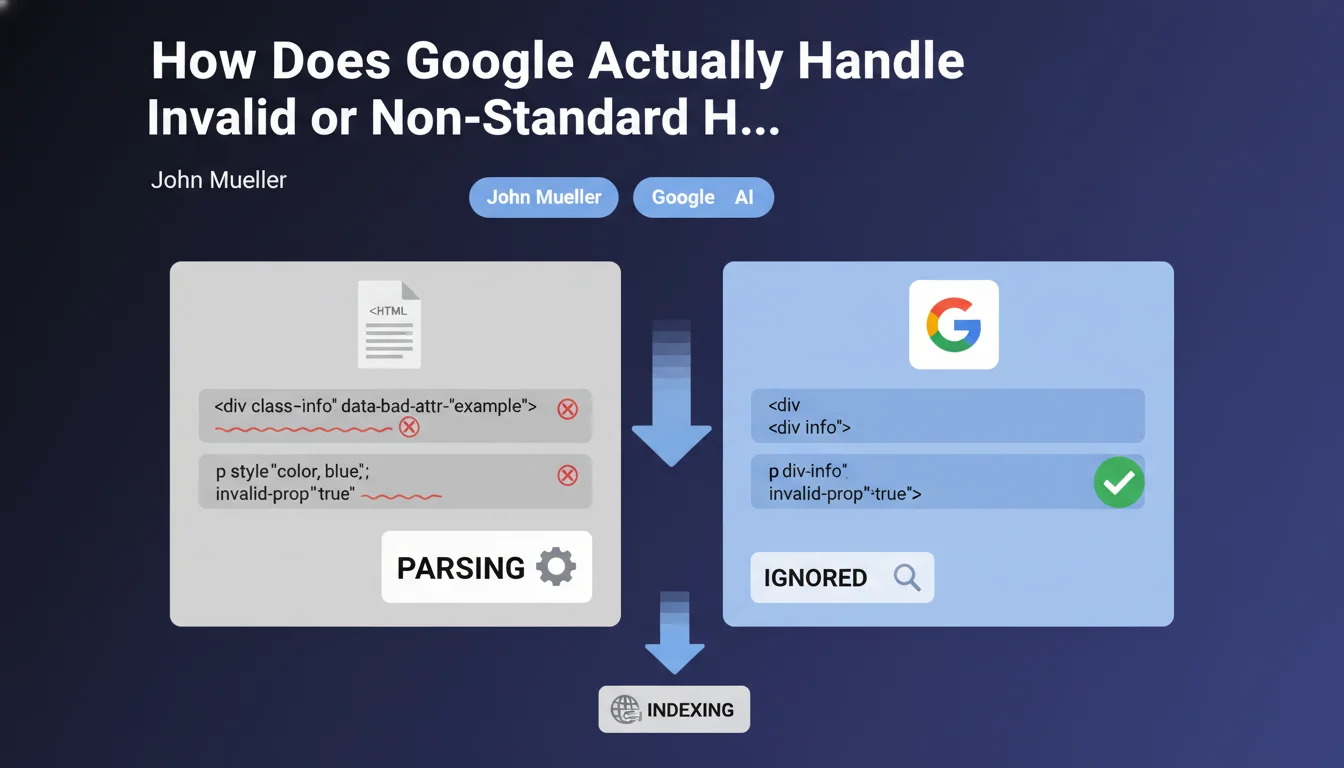
When Google's robots analyze the HTML code of a web page, they frequently encounter badly coded attributes, attributes absent from specifications, or those containing syntax errors. According to John Mueller's statement, the engine's behavior is simple: these erroneous attributes are ignored during parsing.
This means that Google does not block the indexation of a page due to non-compliant HTML attributes. Google's parser is error-tolerant, similar to modern web browsers that display pages even with imperfect code.
Why does this tolerance matter for SEO?
This pragmatic approach reflects the reality of the web where the majority of sites contain HTML errors. If Google refused to index every page with non-standard attributes, a large portion of the web would be invisible in search results.
The engine therefore focuses on extracting content and essential SEO signals rather than strict compliance with W3C standards. Critical elements like title tags, meta descriptions, headings, and links remain interpretable even if the surrounding code contains imperfections.
Which attributes are covered by this rule?
The statement primarily concerns custom attributes, typos in attribute names (such as "classe" instead of "class"), or obsolete attributes that no longer appear in current HTML specifications.
- Misspelled attributes are simply ignored
- Custom data-* attributes do not affect crawling or indexation
- Obsolete attributes (such as "align" or "bgcolor") do not disrupt analysis
- Invalid attribute values do not prevent tag processing
- Text content and structural tags remain usable despite errors
SEO Expert opinion
Does this tolerance mean HTML code quality doesn't matter at all?
Be careful not to interpret this statement as a green light to neglect HTML code quality. While Google ignores erroneous attributes, this does not mean that poorly structured code is without consequence. Chaotic HTML can hinder the analysis of your page's semantic structure.
Furthermore, clean code improves loading performance, reduces rendering errors in browsers, and facilitates maintenance. These factors indirectly influence SEO through user experience and Core Web Vitals.
Are there critical HTML attributes that Google cannot afford to ignore?
Absolutely. Google's tolerance applies to non-essential attributes, but certain attributes remain crucial for SEO. The "href" attributes of links, "src" for images, "alt" for accessibility, or "rel" for directives are carefully analyzed.
An error on these structural attributes can have direct consequences: a link with a malformed href will not be followed, an image without a correct src will not be indexed in Google Images, a badly coded rel="nofollow" attribute might not be recognized.
How does this statement fit into the evolution of Google's HTML processing?
This tolerance reflects Google's evolution toward more intelligent content processing. With the increasing use of JavaScript and modern frameworks, the engine must deal with dynamically generated HTML structures that are sometimes less orthodox.
Google invests in robust parsing technologies capable of extracting meaning and structure even from imperfect code. This pragmatic approach ensures that the engine remains relevant in the face of the diversity of web technologies used today.
Practical impact and recommendations
Should I fix the HTML errors detected on my site?
Even though Google ignores erroneous attributes, correcting HTML errors remains a best practice. Use tools like the W3C validator or browser extensions to identify problems in your code.
Focus primarily on errors that affect critical SEO elements: structural tags, metadata, schema markup, internal links, and essential attributes. Minor errors on decorative attributes can wait.
What technical checks should be performed as a priority?
Establish a hierarchy in your corrections. Errors that affect crawling, indexation, or display in SERPs must be addressed as a priority. Purely aesthetic imperfections can be scheduled in a maintenance backlog.
- Verify the validity of title tags, meta descriptions, and meta robots on all your key pages
- Test all href attributes of your internal and external links to detect malformations
- Validate the syntax of your canonical and hreflang tags with specialized tools
- Check that alt and src attributes of your images are correctly filled in
- Audit your schema.org structured data with Google's Rich Results Test
- Review rel attributes (nofollow, sponsored, ugc) to confirm their proper implementation
- Verify the compliance of your Open Graph and Twitter Card attributes for social sharing
- Use Google Search Console to identify parsing errors reported by the engine
How can I maintain optimal HTML code over time?
Code quality must be part of an ongoing process, not a one-time audit. Integrate automated tests into your development process to detect regressions before production deployment.
Train your teams in technical SEO best practices and establish coding guidelines. Clean code from the design stage avoids costly corrections later and ensures better maintainability.
💬 Comments (0)
Be the first to comment.