Official statement
What you need to understand
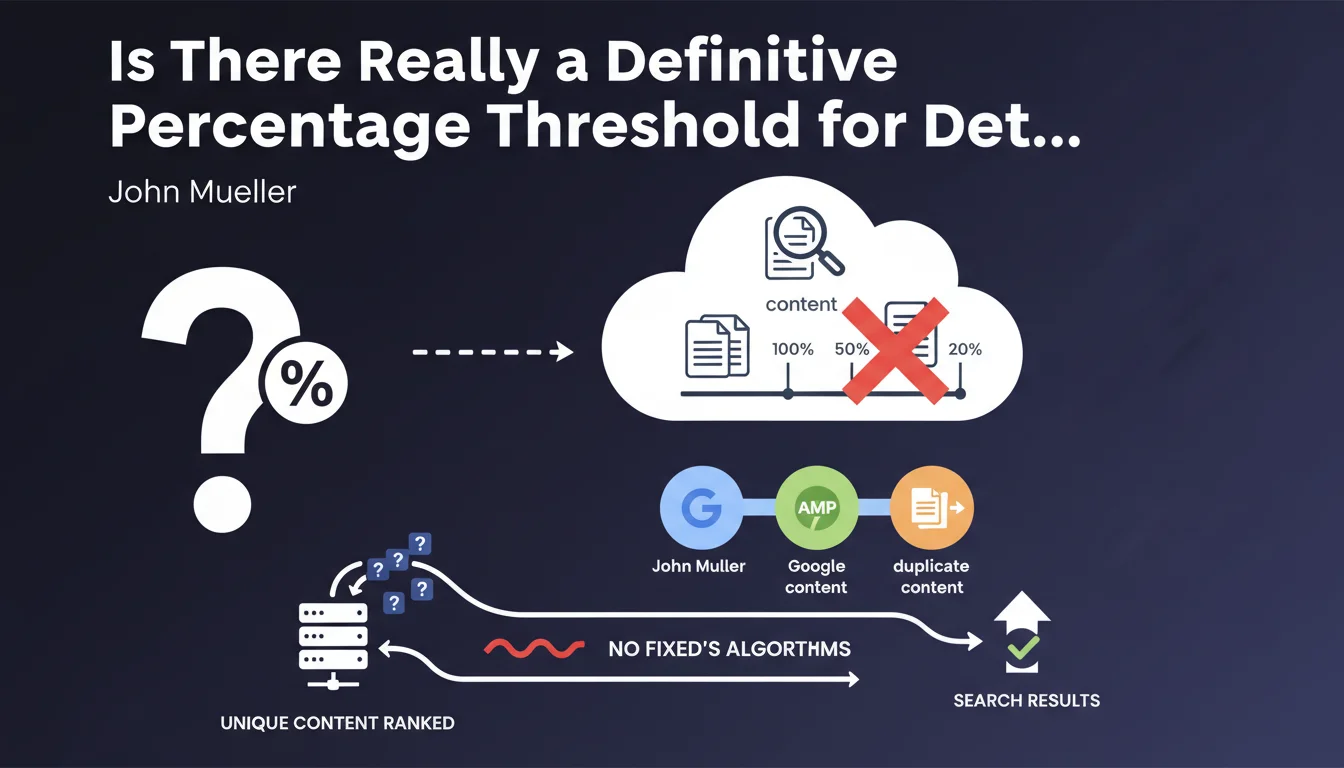
What is Google's official position on duplication thresholds?
Google clearly states that no fixed percentage can determine whether two pieces of content are considered duplicate. Contrary to common misconceptions, there is no absolute rule like "beyond X% similarity, the content is duplicate".
This position reflects Google's algorithmic complexity, which analyzes far more than simple percentages. The algorithm evaluates context, semantic structure, search intent, and numerous other qualitative signals.
Why does this absence of a precise threshold raise questions for SEO professionals?
SEO practitioners naturally seek quantifiable benchmarks to audit their sites. The absence of an official threshold creates a gray area where everyone must establish their own working standards.
In practice, most professionals adopt empirical thresholds derived from field experience, generally ranging between 70% and 80% similarity. These values function as pragmatic safeguards.
How does Google actually detect duplicate content?
The search engine uses a multidimensional approach that goes far beyond simple textual comparison. It examines HTML structure, tags, internal links, content freshness, and its authority.
- Semantic analysis: Google understands meaning and context, not just words
- Added value assessment: two similar pieces of content can coexist if they provide different perspectives
- Canonicalization signals: canonical tags and site structure influence decisions
- No systematic penalty: duplicate content leads to filtering rather than punishment
- Duplication context: internal vs external, intentional vs technical
SEO Expert opinion
Does this statement align with what we observe in the field?
My 15 years of experience fully confirm this position. I've observed sites with 30% similarity penalized in terms of visibility, and others with 75% duplication that performed well.
The difference lies in qualitative factors: domain authority, logical content structure, overall user experience, and especially perceived added value. An e-commerce site with similar product descriptions but well-structured performs better than a blog copying content even partially.
What essential nuances should we bring to this statement?
Although Google doesn't impose a threshold, this doesn't mean that all levels of duplication are acceptable. The absence of a fixed percentage reflects a reality: each situation is unique and contextualized.
We must distinguish inevitable technical duplication (pagination, filters, mobile versions) from problematic editorial duplication. Google tolerates the former with proper technical signals, but systematically devalues the latter.
In which cases does this flexible rule work in our favor?
This nuanced approach benefits sites that work on qualitative differentiation rather than quantitative. An article reusing 70% of common factual information but adding 30% unique analysis can outperform a competitor that's 100% original but superficial.
It also allows some flexibility for multilingual sites, comparison sites, data aggregators, or technical sites where a certain standardization of content is inevitable. It's the overall execution that matters.
Practical impact and recommendations
How can you effectively audit your site without an official reference threshold?
Adopt a multi-level methodology rather than relying on a single percentage. Start with a complete crawl using Screaming Frog by activating internal similarity detection.
Use the 70% threshold as an initial alert, but then manually analyze each case. Check whether the duplication concerns strategic content or technical elements. Prioritize pages generating organic traffic.
Supplement with tools like Copyscape for external duplication, and Search Console to identify ignored pages or those considered alternatives. Cross-reference this data for a comprehensive view.
What concrete actions should you implement to minimize risks?
- Implement canonical tags on all page variations (filters, parameters, pagination)
- Rewrite duplicate content beyond 70% similarity for strategic pages
- Use noindex for technical pages with no SEO value (internal search results, thank you pages)
- Systematically enrich similar content with unique elements: reviews, data, analyses
- Create differentiated content structures even for closely related topics
- Set up continuous monitoring with automated alerts on newly published content
- Train editorial teams in best practices for unique and differentiated writing
- Document legitimate exceptions and their technical justification for consistent tracking
What strategy should you adopt to turn this constraint into a competitive advantage?
Rather than aiming for a magic percentage, focus on creating high-value content. Analyze competitor content to identify untreated angles and differentiation opportunities.
Develop a strict editorial charter that mandates unique required elements: proprietary data, specific use cases, professional expertise. This qualitative approach naturally protects you from duplication.
💬 Comments (0)
Be the first to comment.