Official statement
What you need to understand
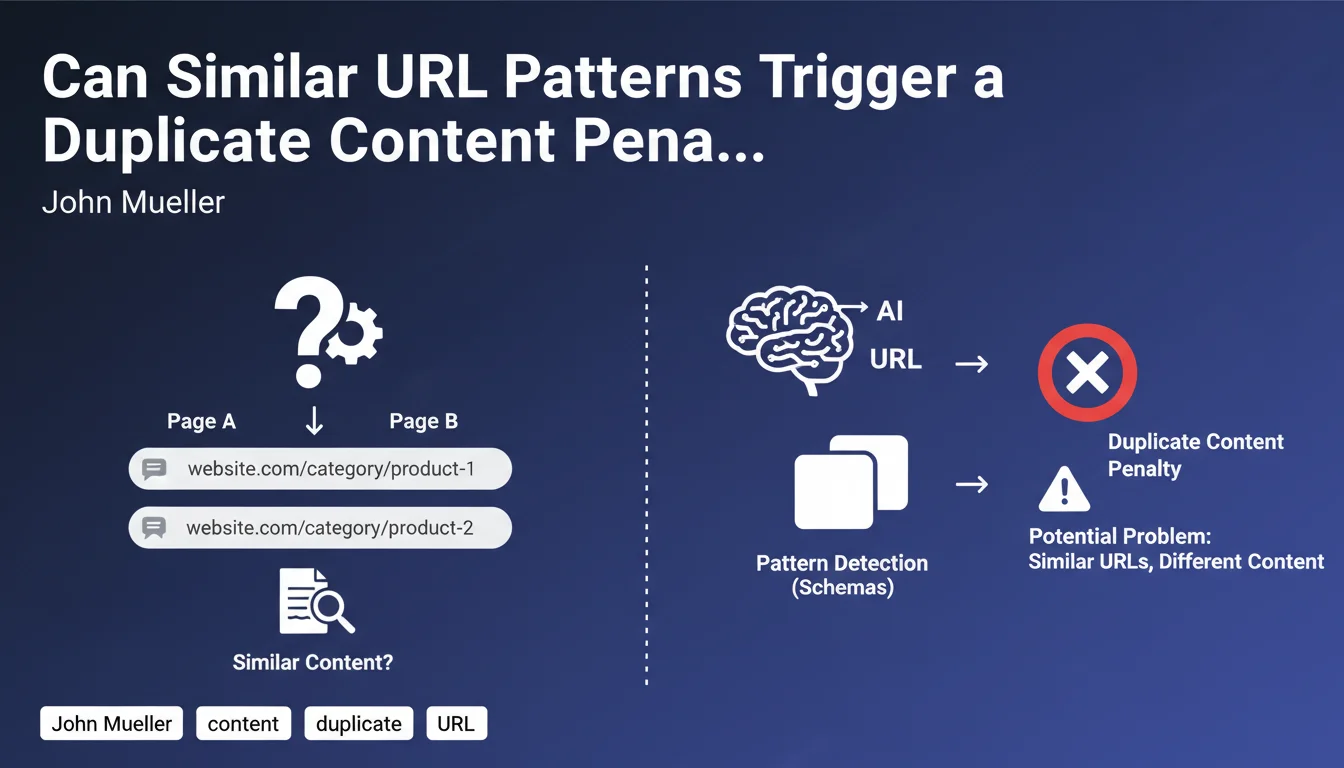
How Does Google Detect Duplicate Content Through URLs?
Google uses a predictive approach based on analyzing URL patterns to potentially identify duplicate content. The search engine examines the structure of web addresses and looks for recurring schemas.
When two pages present both structurally similar URLs and similar content, the algorithm may extrapolate this observation. It then risks categorizing all pages following this pattern as duplicate content, even if their content actually differs.
Why Does This Method Create Problems for SEOs?
This pattern-based detection creates a risk of false positives. Legitimately different pages may be considered duplicates solely because of their similar URL structure.
The problem becomes critical when you manage multi-location sites or product catalogs with variations. A logical and coherent URL architecture can paradoxically become a handicap.
What Are the Typical Cases Affected by This Phenomenon?
Local sites with city variations are the first concerned. For example: /plumber-paris, /plumber-lyon, /plumber-marseille with almost identical content.
Product pages with variants (colors, sizes) or geographically declined service pages are also vulnerable to this algorithmic detection.
- Google analyzes the structural patterns of URLs to detect duplicate content
- URLs that are too similar + close content = risk of erroneous classification of all pages with the same pattern
- This predictive method can generate penalizing false positives
- Multi-location sites and product catalogs are particularly exposed
SEO Expert opinion
Is This Statement Consistent with Field Observations?
Absolutely. This statement from John Mueller corresponds perfectly to the recurring problems observed on multi-city or franchise sites. Many local sites see their geolocated pages deindexed or cannibalized despite differentiation efforts.
Analysis tools like Search Console regularly show pages marked as "Excluded: Duplicate page" even though the webmaster has attempted to personalize the content. The URL pattern remains the main triggering signal for the algorithm.
What Nuances Should Be Added to This Rule?
The quality and real uniqueness of content remain determining factors. If your local pages truly offer differentiated content (local testimonials, specific references, unique geographic information), Google will generally end up distinguishing them.
The problem mainly occurs when you combine similar URLs + weakly differentiated templated content. Either one of these factors alone is manageable, but both together create too strong a duplication signal.
In What Contexts Is This Issue Overestimated?
For very large brands or sites with strong domain authority, Google seems more tolerant. The algorithm gives more credit to these established players and analyzes their content more finely.
Sites offering truly unique and long content (over 800-1000 words per page) with substantial variations generally escape this automatic categorization, even with similar URLs.
Practical impact and recommendations
What Should You Do Concretely to Avoid This Trap?
Favor a diversified URL architecture for your similar pages. Avoid overly predictable structures like /service-city-1, /service-city-2, etc. Vary the depth levels and naming conventions.
Invest heavily in real content differentiation. Each geolocated page must contain truly unique elements: local customer testimonials, regional statistical data, specific photos, local news.
Use canonical tags strategically to explicitly indicate to Google which version to prioritize. For truly different pages, make sure they point to themselves.
What Mistakes Should You Absolutely Avoid in This Situation?
Never create automatically geolocated pages by simply changing the city name in a template. This is the perfect recipe for triggering this pattern detection.
Avoid multiplying similar pages without real search volume justification. If a city generates 10 searches/month, the dedicated page risks doing more harm than good because of the duplication signal.
Don't use cloaking or hidden text techniques to artificially differentiate your content. Google detects these manipulations and the penalty will be much more severe.
How Do You Audit and Fix a Site Already Impacted?
Analyze in Google Search Console the pages marked as excluded for duplication. Identify the URL patterns common to these pages to understand what Google has detected.
Perform a differentiation test: compare the content of your similar pages with text comparison tools. If similarity exceeds 70-80%, you're in the danger zone.
Prioritize your corrections: keep only geolocated pages with high potential (search volume, conversion) and consolidate or delete the others. Redirect deleted pages to a generic local page.
- Consciously diversify URL structures to avoid overly obvious patterns
- Create truly unique content for each geolocated page (minimum 40-50% difference)
- Properly implement canonical tags to guide Google
- Regularly audit Search Console to detect exclusions for duplication
- Avoid multiplying similar pages without search volume justification
- Delete or merge low-value pages creating algorithmic noise
- Enrich each local page with specific elements: reviews, photos, regional data
- Vary depth levels and URL structures rather than following a single model
💬 Comments (0)
Be the first to comment.