Official statement
What you need to understand
Internal search engines generate result pages that can be indexed by Google. These pages pose a major problem: they create duplicate content and low-relevance URLs in the index.
The most problematic case concerns "No results found" pages. These pages provide no value to users and unnecessarily consume your site's crawl budget.
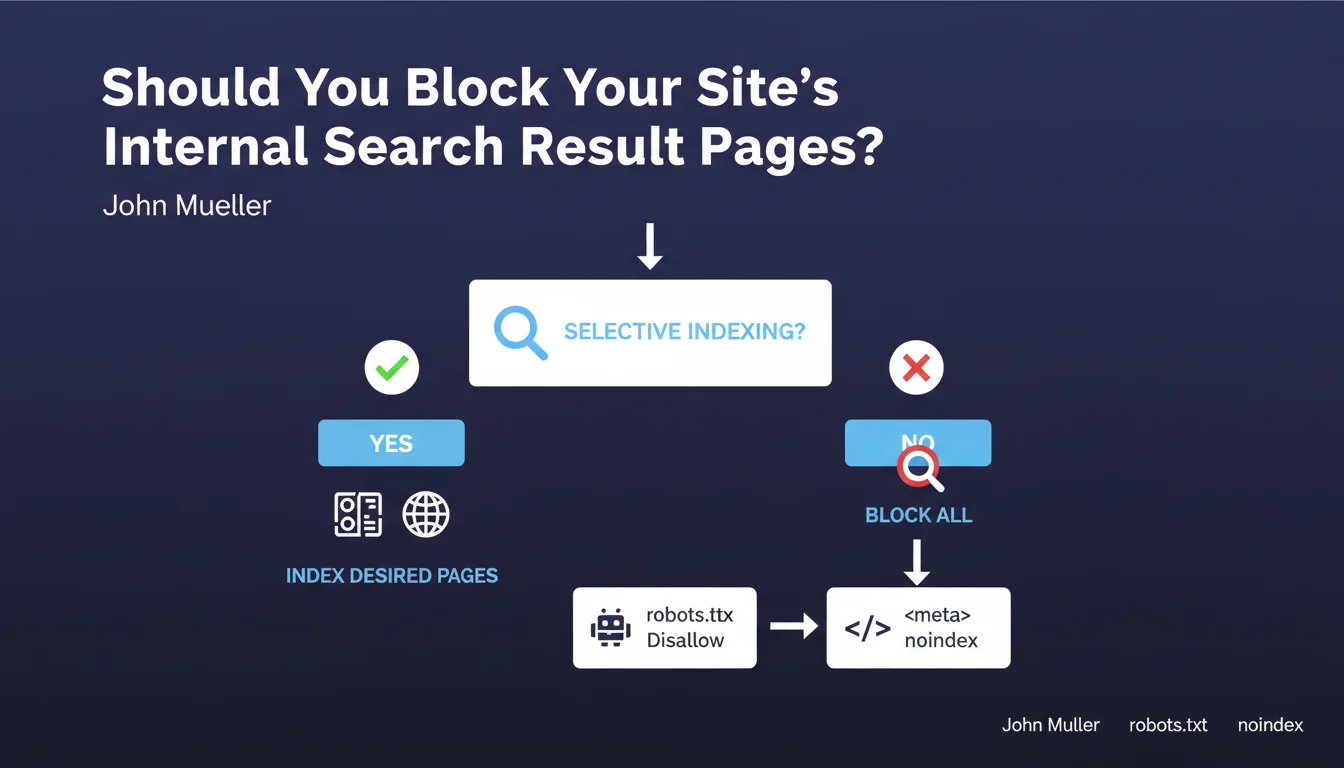
Google has explicitly recommended blocking these pages since 2007, emphasizing that this practice remains current today. The recommendation is clear: if you cannot finely select which internal search pages deserve indexing, it's better to block them all.
- Internal search pages dilute the overall quality of your indexation
- Empty results represent a waste of resources for robots
- Two methods are recommended: robots.txt (disallow) or meta robots (noindex)
- The directive applies particularly to e-commerce sites and sites with advanced search functionalities
SEO Expert opinion
This recommendation is perfectly consistent with SEO best practices observed in the field. Sites that massively index their internal search pages generally experience authority dilution and performance decline on their strategic pages.
However, there are notable exceptions. Some sites like Amazon or eBay deliberately index certain popular searches that generate qualified traffic. The key lies in the ability to discriminate high-value-added searches from generic or empty queries.
The method to favor depends on your architecture. Robots.txt prevents crawling but not necessarily indexing if external links point to these pages. The noindex tag guarantees deindexing but requires the page to be crawled, which can be problematic with high volumes.
Practical impact and recommendations
- Audit your currently indexed internal search pages via Search Console (query site:yourdomain.com/search or equivalent)
- Identify URL patterns generated by your internal search engine (parameters ?q=, ?s=, /search/, etc.)
- Analyze whether certain searches generate qualified organic traffic that would justify keeping them in the index
- For sites with few indexed searches: implement a meta robots noindex tag on all search pages
- For high volumes: block crawling via robots.txt with a Disallow directive targeting search URLs
- Configure specific rules to systematically block "0 results" pages if your CMS allows it
- Verify that your robots.txt file doesn't prevent Google from seeing noindex tags (never block a page with noindex in robots.txt)
- Monitor the evolution of indexed pages in the following weeks to validate effectiveness
- Add these URLs to your sitemap.xml with a low <priority> tag if you choose to keep certain searches indexable
💬 Comments (0)
Be the first to comment.