Official statement
What you need to understand
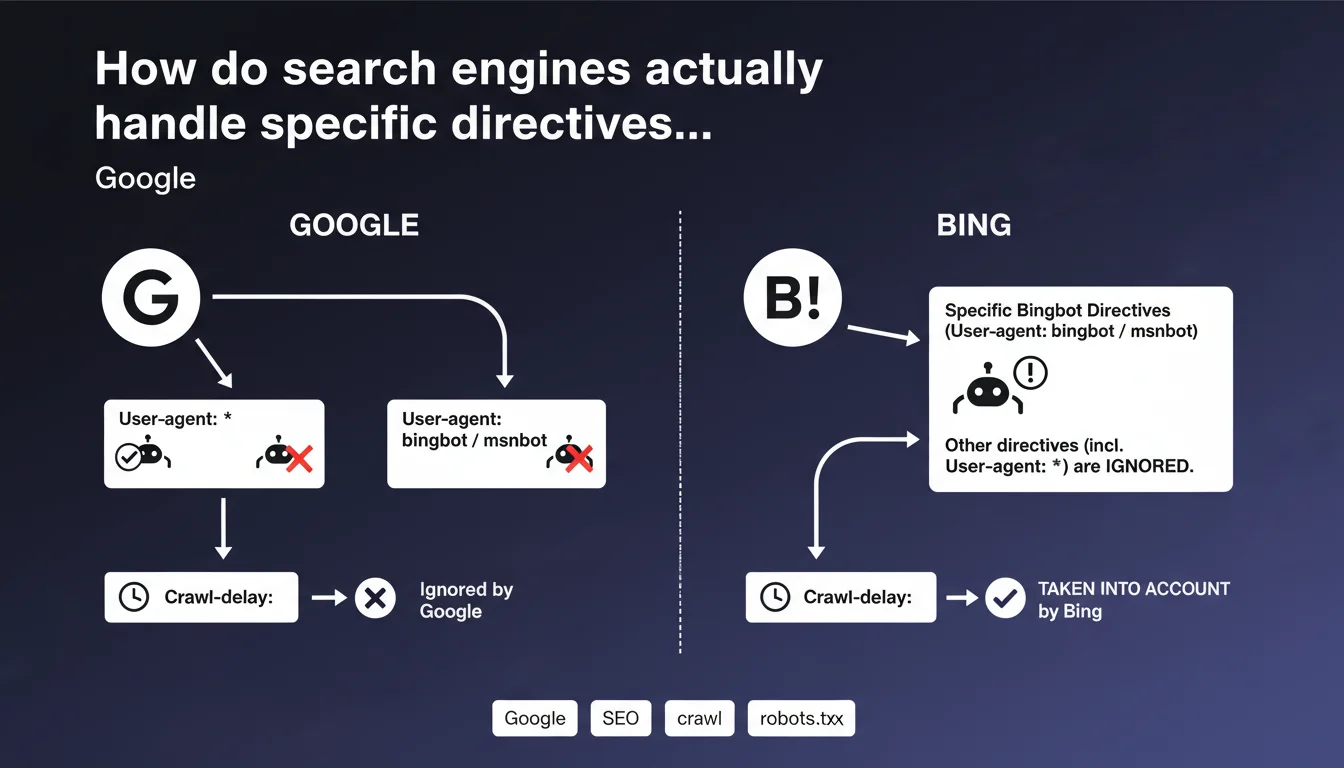
The robots.txt file allows you to control indexing robots' access to different parts of a website. It contains directives that can apply to all robots (User-agent: *) or to specific robots like Googlebot or Bingbot.
This statement reveals a crucial behavior: when a search engine identifies a section specifically dedicated to it in the robots.txt, it completely ignores the generic directives defined under User-agent: *. Only the directives from its own section are then taken into account.
Concretely, if you have defined rules under User-agent: * then added a User-agent: bingbot or User-agent: googlebot section, these engines will only apply the rules from their specific section, even if they are less complete than the general rules.
- Specific directives completely override generic directives (User-agent: *)
- This behavior applies to both Google and Bing
- You must therefore duplicate all necessary rules in each specific section
- An incomplete section for a specific bot can inadvertently expose areas of the site
- The Crawl-delay directive remains ignored by Google but is taken into account by Bing
SEO Expert opinion
This clarification confirms a fundamental principle of robots.txt directive hierarchy that many SEO professionals misunderstand or underestimate. In my practice, I have regularly observed configurations where specific sections were added without complete replication of general rules, creating involuntary privacy vulnerabilities.
The classic trap occurs when you add a specific directive for a single bot (for example to use Crawl-delay with Bing) without reproducing all the other restrictions. The concerned bot then ignores all protections defined in User-agent: *, which can expose sensitive directories, staging environments, or duplicate content.
It is also important to note that this rule applies consistently across different engines, which at least simplifies management once the principle is understood. The complexity lies in maintenance: each modification of general rules must be replicated in all specific sections.
Practical impact and recommendations
- Audit your robots.txt immediately to identify all specific User-agent sections (googlebot, bingbot, msnbot, etc.)
- Verify the completeness of each specific section: it must contain all necessary Disallow and Allow directives, not just particular additions
- Systematically duplicate the User-agent: * rules in each specific section if you create one
- Test your robots.txt with validation tools from Google Search Console and Bing Webmaster Tools for each bot individually
- Document the logic of your robots.txt with comments explaining why certain specific sections exist
- Avoid creating specific sections unless absolutely necessary (such as adding Crawl-delay for Bing)
- Favor simplicity: if the rules are identical for all bots, only use User-agent: *
- Implement a systematic validation procedure before any deployment of robots.txt modifications
Strategic recommendation: Optimal management of a robots.txt file requires in-depth understanding of each engine's specificities and constant vigilance during updates.
Configuration errors can have serious consequences: indexation of sensitive content, waste of crawl budget, or conversely unintentional blocking of important site sections. These technical issues prove particularly delicate in complex environments with multiple subdomains, language versions, or advanced technical architectures.
Faced with these critical challenges, many professionals choose to surround themselves with specialized expertise to secure these fundamental technical aspects and benefit from personalized support adapted to their specific context.
💬 Comments (0)
Be the first to comment.