Declaration officielle
Ce qu'il faut comprendre
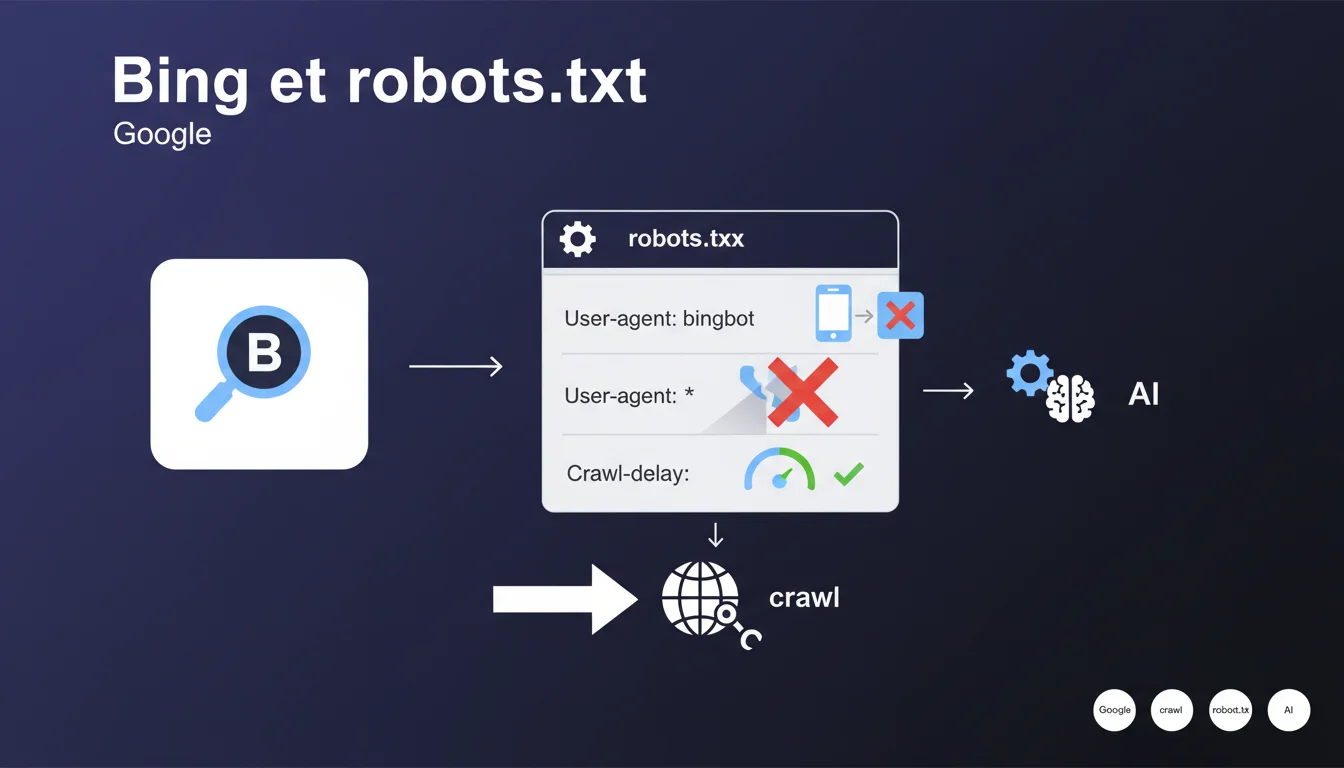
Le fichier robots.txt permet de contrôler l'accès des robots d'indexation aux différentes parties d'un site web. Il contient des directives qui peuvent s'appliquer à tous les robots (User-agent: *) ou à des robots spécifiques comme Googlebot ou Bingbot.
Cette déclaration révèle un comportement crucial : lorsqu'un moteur de recherche identifie une section qui lui est spécifiquement dédiée dans le robots.txt, il ignore totalement les directives génériques définies sous User-agent: *. Seules les directives de sa propre section sont alors prises en compte.
Concrètement, si vous avez défini des règles sous User-agent: * puis ajouté une section User-agent: bingbot ou User-agent: googlebot, ces moteurs n'appliqueront que les règles de leur section spécifique, même si elles sont moins complètes que les règles générales.
- Les directives spécifiques écrasent complètement les directives génériques (User-agent: *)
- Ce comportement s'applique aussi bien à Google qu'à Bing
- Il faut donc dupliquer toutes les règles nécessaires dans chaque section spécifique
- Une section incomplète pour un bot spécifique peut exposer involontairement des zones du site
- La directive Crawl-delay reste ignorée par Google mais prise en compte par Bing
Avis d'un expert SEO
Cette clarification confirme un principe fondamental de la hiérarchie des directives robots.txt que de nombreux professionnels du SEO méconnaissent ou sous-estiment. Dans ma pratique, j'ai régulièrement constaté des configurations où des sections spécifiques étaient ajoutées sans réplication complète des règles générales, créant des failles de confidentialité involontaires.
Le piège classique survient lorsqu'on ajoute une directive spécifique pour un seul bot (par exemple pour utiliser Crawl-delay avec Bing) sans reproduire l'ensemble des autres restrictions. Le bot concerné ignore alors toutes les protections définies en User-agent: *, ce qui peut exposer des répertoires sensibles, environnements de staging ou contenus dupliqués.
Il est également important de noter que cette règle s'applique de manière cohérente entre les différents moteurs, ce qui simplifie au moins la gestion une fois le principe compris. La complexité réside dans la maintenance : chaque modification des règles générales doit être répercutée dans toutes les sections spécifiques.
Impact pratique et recommandations
- Auditer immédiatement votre robots.txt pour identifier toutes les sections User-agent spécifiques (googlebot, bingbot, msnbot, etc.)
- Vérifier l'exhaustivité de chaque section spécifique : elle doit contenir toutes les directives Disallow et Allow nécessaires, pas seulement les ajouts particuliers
- Dupliquer systématiquement les règles de User-agent: * dans chaque section spécifique si vous en créez une
- Tester votre robots.txt avec les outils de validation de Google Search Console et Bing Webmaster Tools pour chaque bot individuellement
- Documenter la logique de votre robots.txt avec des commentaires expliquant pourquoi certaines sections spécifiques existent
- Éviter de créer des sections spécifiques sauf nécessité absolue (comme l'ajout de Crawl-delay pour Bing)
- Privilégier la simplicité : si les règles sont identiques pour tous les bots, n'utilisez que User-agent: *
- Mettre en place une procédure de validation systématique avant tout déploiement de modifications du robots.txt
Recommandation stratégique : La gestion optimale d'un fichier robots.txt nécessite une compréhension approfondie des spécificités de chaque moteur et une vigilance constante lors des mises à jour.
Les erreurs de configuration peuvent avoir des conséquences graves : indexation de contenus sensibles, gaspillage de crawl budget, ou au contraire blocage involontaire de sections importantes du site. Ces problématiques techniques s'avèrent particulièrement délicates dans les environnements complexes avec multiples sous-domaines, versions linguistiques ou architectures techniques avancées.
Face à ces enjeux critiques, nombreux sont les professionnels qui choisissent de s'entourer d'une expertise spécialisée pour sécuriser ces aspects techniques fondamentaux et bénéficier d'un accompagnement personnalisé adapté à leur contexte spécifique.
💬 Commentaires (0)
Soyez le premier à commenter.