Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- □ Faut-il vraiment choisir entre www et non-www pour le SEO ?
- □ Pourquoi Googlebot ignore-t-il vos boutons et comment contourner cette limite ?
- □ Les guest posts pour des backlinks sont-ils vraiment bannis par Google ?
- □ Faut-il vraiment du texte sur les pages catégories pour bien ranker ?
- □ Le HTML sémantique a-t-il vraiment un impact sur le classement Google ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 générées par JSON et JavaScript dans GSC ?
- □ Google privilégie-t-il vraiment la meta description quand le contenu est pauvre ?
- □ Faut-il vraiment bloquer l'indexation des menus et zones communes d'un site ?
- □ L'infinite scroll est-il compatible avec le SEO si chaque section possède une URL unique ?
- □ L'indexation mobile-first impose-t-elle vraiment la version mobile comme unique référence ?
- □ Les PDF hébergés sur Google Drive sont-ils vraiment indexables par Google ?
- □ Faut-il supprimer ou améliorer le contenu de faible qualité sur votre site ?
- □ Le CMS influence-t-il vraiment le jugement de Google sur votre site ?
- □ Un noindex sur la homepage peut-il vraiment faire apparaître d'autres pages en premier ?
- □ Faut-il vraiment optimiser l'INP si ce n'est pas (encore) un facteur de classement ?
- □ Faut-il vraiment nettoyer toutes les pages hackées ou laisser Google faire le tri ?
- □ Faut-il arrêter de forcer l'indexation quand Google désindexe vos pages ?
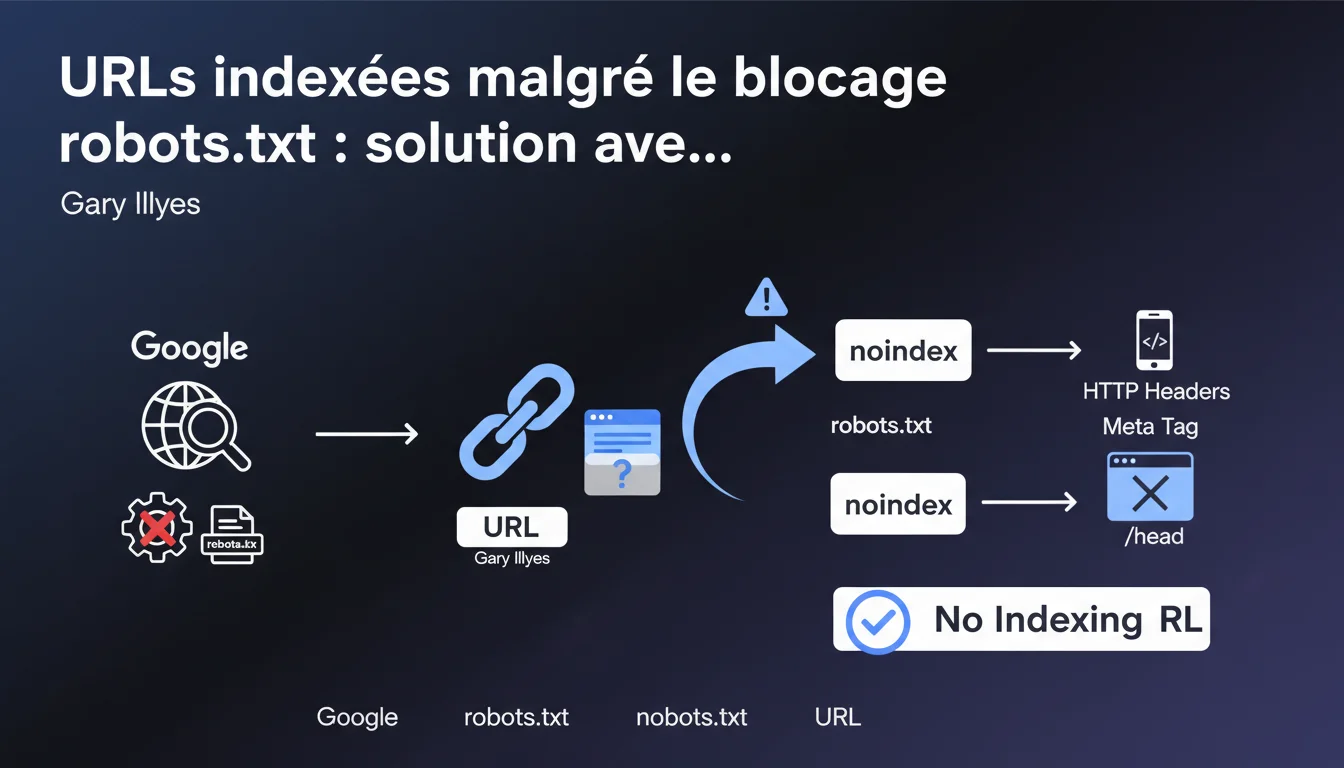
Google peut indexer une URL (sans son contenu) même si elle est bloquée par robots.txt. Si cette indexation est problématique, il faut autoriser l'exploration et ajouter une directive noindex via balise meta ou en-tête HTTP. Le blocage robots.txt n'empêche pas l'apparition dans l'index, il bloque seulement le crawl du contenu.
Ce qu'il faut comprendre
Quelle est la différence entre blocage robots.txt et noindex ?
Le robots.txt empêche l'exploration d'une URL par Googlebot. Mais si cette URL reçoit des backlinks externes, Google peut quand même l'ajouter à son index — sans avoir crawlé le contenu. Seule l'URL apparaît, accompagnée parfois d'un extrait tiré du texte d'ancrage des liens pointant vers elle.
La directive noindex, elle, demande explicitement à Google de ne pas indexer la page. Problème : si robots.txt bloque l'accès, Googlebot ne peut pas lire cette directive. C'est pour ça que Gary Illyes recommande d'autoriser l'exploration pour permettre à Google de découvrir le noindex.
Comment Google indexe-t-il une URL qu'il n'a jamais crawlée ?
Google découvre des URLs via plusieurs canaux : sitemaps, liens internes, backlinks externes. Même si robots.txt interdit le crawl, une URL peut apparaître dans l'index si elle reçoit suffisamment de signaux externes.
Dans ce cas, la fiche dans les résultats de recherche affiche uniquement l'URL, sans titre ni description tirés du contenu réel. Google s'appuie sur le contexte des liens qui pointent vers cette page.
Pourquoi est-ce un problème pour certains sites ?
Certaines URLs ne doivent jamais apparaître dans les résultats : interfaces d'administration, pages de test, environnements de staging, URLs avec paramètres sensibles. Si ces pages reçoivent des liens, elles peuvent finir indexées.
D'autres cas incluent des pages dupliquées qu'on pensait bloquer via robots.txt, ou des URLs confidentielles dont la simple existence ne doit pas être révélée publiquement.
- Robots.txt bloque le crawl, pas l'indexation
- Une URL peut être indexée si elle reçoit des backlinks, même sans crawl
- Le noindex nécessite que Googlebot puisse accéder à la page pour lire la directive
- La solution : autoriser l'exploration ET ajouter noindex
- Le noindex peut être placé dans une balise meta ou un en-tête HTTP X-Robots-Tag
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les observations terrain ?
Oui — et c'est un classique qui surprend encore beaucoup de SEO juniors. On observe régulièrement des URLs bloquées par robots.txt qui apparaissent dans l'index, avec la mention « Aucune information n'est disponible pour cette page ».
Le problème se pose surtout sur des sites qui reçoivent des backlinks parasites ou des liens internes mal configurés. Une page bloquée mais liée finit par remonter dans l'index, et certains clients découvrent des URLs sensibles indexées par accident.
Quelles erreurs fréquentes observe-t-on sur ce point ?
Première erreur : croire que robots.txt = désindexation. C'est faux. Robots.txt contrôle l'accès, pas la présence dans l'index. Beaucoup de sites bloquent par réflexe des sections entières, sans réaliser que ça complique la désindexation ultérieure.
Deuxième erreur : mettre noindex ET bloquer dans robots.txt simultanément. Ça crée un conflit — Google ne peut pas lire le noindex si le crawl est interdit. Résultat : la page reste parfois indexée indéfiniment. [A vérifier] dans certains cas edge, Google semble traiter différemment les noindex en en-tête HTTP versus balise meta quand robots.txt bloque — mais Google n'a jamais fourni de données précises là-dessus.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si une URL ne reçoit aucun lien externe ni interne, et n'apparaît dans aucun sitemap, elle ne sera probablement jamais découverte par Google. Bloquer par robots.txt suffit alors — en théorie.
Mais dans la pratique ? Les URLs fuient. Logs serveur consultables publiquement, outils de crawl tiers, scrapers, fuites dans des outils analytics… Compter uniquement sur l'obscurité est risqué. Si l'URL ne doit vraiment pas être indexée, le noindex reste la garantie.
Impact pratique et recommandations
Que faut-il faire concrètement si des URLs bloquées sont indexées ?
Premier réflexe : retirer le blocage robots.txt pour permettre à Googlebot d'explorer les URLs concernées. Ensuite, ajouter une directive noindex — soit via balise meta dans le HTML, soit via en-tête HTTP X-Robots-Tag si c'est un fichier non-HTML.
Ensuite, soumettre les URLs via Google Search Console avec l'outil de suppression d'URL. Ça accélère le traitement, même si ce n'est pas strictement obligatoire. Google finira par recrawler et désindexer, mais ça peut prendre des semaines sans intervention manuelle.
Comment vérifier qu'une URL est indexée malgré robots.txt ?
Utilise la commande site:votredomaine.com/url-precise dans Google. Si l'URL apparaît avec « Aucune information n'est disponible », c'est qu'elle est indexée sans avoir été crawlée.
Surveille aussi le rapport Couverture dans Search Console. Les URLs « Exclues par robots.txt » n'apparaissent pas forcément dans l'index, mais celles qui y sont malgré tout nécessitent une action corrective.
Quelle méthode choisir : balise meta ou en-tête HTTP ?
Pour du HTML classique, la balise meta est simple : <meta name="robots" content="noindex">. Ça fonctionne parfaitement pour des pages WordPress, des CMS standards.
Pour des fichiers PDF, images, ou des réponses JSON d'API, l'en-tête HTTP X-Robots-Tag: noindex est la seule option. C'est aussi pratique pour appliquer noindex dynamiquement via règles serveur — utile sur des sites avec des milliers d'URLs paramétrées.
- Auditer les URLs bloquées par robots.txt qui reçoivent des backlinks
- Retirer le blocage robots.txt pour les URLs à désindexer
- Ajouter noindex via balise meta ou en-tête HTTP selon le type de ressource
- Soumettre les URLs via Google Search Console pour accélérer la désindexation
- Vérifier régulièrement avec site: que les URLs sensibles ne sont pas indexées
- Privilégier l'en-tête HTTP pour les fichiers non-HTML (PDF, images, etc.)
- Documenter la stratégie pour éviter que robots.txt ne soit modifié par erreur ultérieurement
❓ Questions frequentes
Peut-on utiliser noindex et robots.txt simultanément ?
Combien de temps faut-il pour qu'une URL soit désindexée après ajout du noindex ?
Le noindex en en-tête HTTP est-il aussi efficace que la balise meta ?
Que se passe-t-il si une URL bloquée par robots.txt reçoit beaucoup de backlinks ?
Faut-il garder robots.txt pour protéger des pages sensibles ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.