Declaration officielle
Autres déclarations de cette vidéo 17 ▾
- □ Faut-il vraiment choisir entre www et non-www pour le SEO ?
- □ Pourquoi Googlebot ignore-t-il vos boutons et comment contourner cette limite ?
- □ Les guest posts pour des backlinks sont-ils vraiment bannis par Google ?
- □ Faut-il vraiment du texte sur les pages catégories pour bien ranker ?
- □ Le HTML sémantique a-t-il vraiment un impact sur le classement Google ?
- □ Faut-il vraiment s'inquiéter des erreurs 404 générées par JSON et JavaScript dans GSC ?
- □ Google privilégie-t-il vraiment la meta description quand le contenu est pauvre ?
- □ Faut-il vraiment bloquer l'indexation des menus et zones communes d'un site ?
- □ L'infinite scroll est-il compatible avec le SEO si chaque section possède une URL unique ?
- □ L'indexation mobile-first impose-t-elle vraiment la version mobile comme unique référence ?
- □ Les PDF hébergés sur Google Drive sont-ils vraiment indexables par Google ?
- □ Pourquoi Google indexe-t-il vos URLs même quand robots.txt les bloque ?
- □ Faut-il supprimer ou améliorer le contenu de faible qualité sur votre site ?
- □ Le CMS influence-t-il vraiment le jugement de Google sur votre site ?
- □ Faut-il vraiment optimiser l'INP si ce n'est pas (encore) un facteur de classement ?
- □ Faut-il vraiment nettoyer toutes les pages hackées ou laisser Google faire le tri ?
- □ Faut-il arrêter de forcer l'indexation quand Google désindexe vos pages ?
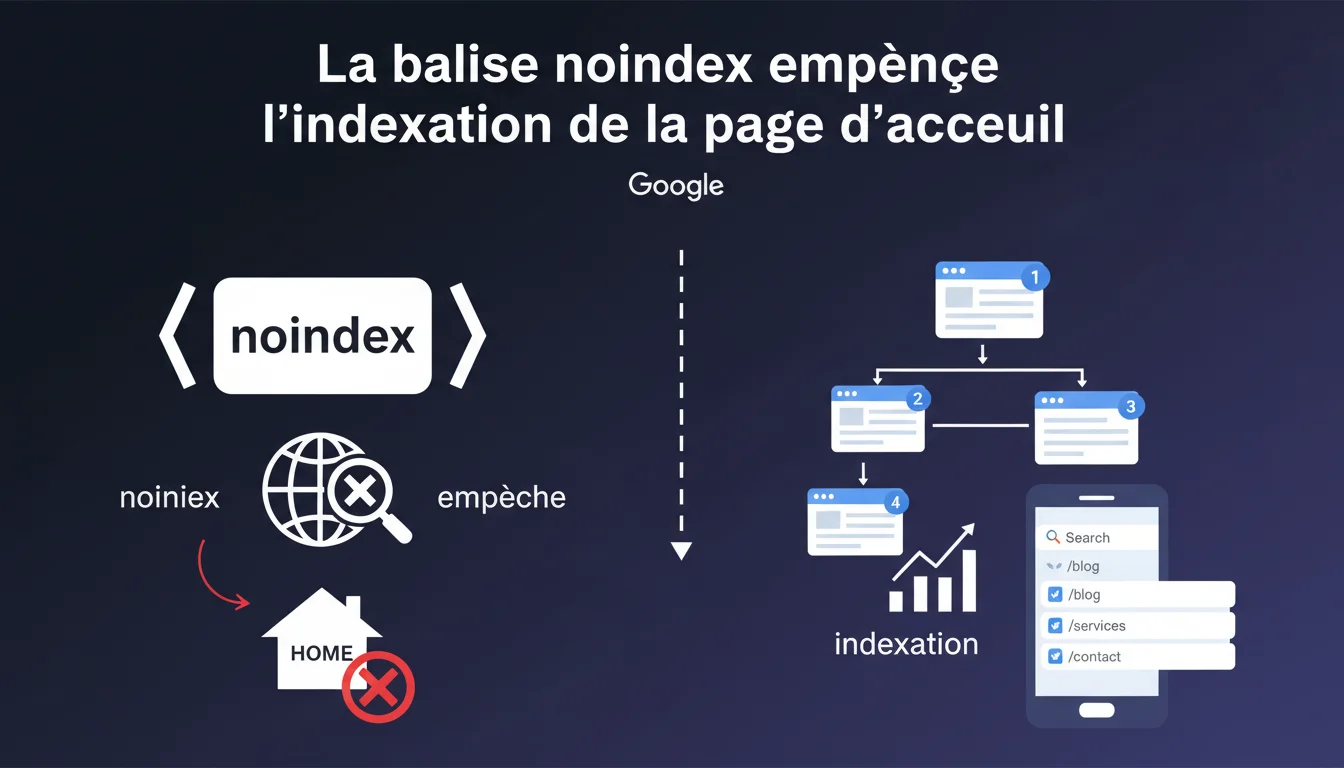
Google confirme qu'une balise noindex sur la page d'accueil bloque son indexation et peut faire remonter d'autres pages du site en tête des résultats. Cette situation, souvent accidentelle, redistribue la visibilité organique de manière imprévisible. Un audit rapide des directives robots s'impose sur tout site perdant du trafic.
Ce qu'il faut comprendre
Pourquoi cette déclaration mérite-t-elle notre attention ?
La directive noindex sur une homepage n'est pas un cas théorique. Les migrations CMS, les environnements de staging mal configurés ou les erreurs de copier-coller de templates génèrent régulièrement ce blocage. Google ne fait pas d'exception pour la page racine — elle disparaît de l'index comme n'importe quelle URL.
Le moteur redistribue alors la visibilité organique vers les pages qu'il juge les plus pertinentes pour les requêtes de marque ou génériques. Souvent, c'est une page produit, une catégorie ou un article de blog qui hérite du trafic. Pas toujours celle que vous auriez choisie.
Comment Google sélectionne-t-il la page de remplacement ?
Aucune documentation officielle ne détaille l'algorithme de sélection. L'expérience terrain montre que les signaux de pertinence classiques entrent en jeu : autorité interne, popularité des liens, ancienneté, correspondance avec l'intention de recherche.
Une page catégorie bien maillée et alimentée en backlinks prendra souvent le dessus sur une page « À propos » orpheline. Le crawl budget n'entre pas directement en ligne de compte ici — c'est un problème d'éligibilité à l'indexation, pas de découverte.
Quels sont les symptômes concrets de ce problème ?
- Chute brutale du trafic organique sur les requêtes de marque
- Disparition de la homepage des SERPs au profit d'une page secondaire
- Alertes Google Search Console signalant une page exclue par la balise noindex
- Incohérence entre les pages classées et l'intention utilisateur
- Perte de contrôle sur le messaging de marque en première position
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. J'ai vu des sites e-commerce perdre 40 % de leur trafic organique en 72 heures après qu'un développeur a répliqué une balise noindex depuis un environnement de dev. Google ne négocie pas avec les directives robots.
Le remplacement n'est jamais neutre. Une page produit positionnée en lieu et place de la homepage génère un trafic qualifié mais fragmenté. Les requêtes génériques de marque renvoient vers un contexte trop spécifique, ce qui dégrade le taux de conversion global. Soyons honnêtes : perdre le contrôle de sa porte d'entrée, c'est un boulet.
Dans quels cas cette logique devient-elle contre-productive ?
Les sites à architecture plate avec peu de profondeur hiérarchique souffrent davantage. Si votre homepage concentre 80 % de votre link equity interne et externe, sa disparition de l'index crée un vide d'autorité que les autres pages peinent à combler.
À l'inverse, un site média avec des centaines d'articles bien référencés encaisse mieux le choc. Le trafic se redistribue naturellement sur les contenus evergreen. [À vérifier] : Google prétend traiter toutes les pages à égalité, mais le comportement observé suggère qu'une homepage bénéficie d'un boost implicite dans les requêtes de marque — sa disparition n'est jamais compensée à 100 %.
Quelles nuances faut-il apporter à cette affirmation ?
Google ne précise pas le délai de propagation. En pratique, compter 48 à 96 heures pour que la désindexation soit effective et qu'une autre page prenne le relais. Ce n'est pas instantané.
Impact pratique et recommandations
Que faut-il faire concrètement si votre homepage est bloquée ?
Premier réflexe : vérifier le code source HTML de la page, pas le back-office du CMS. Les plugins WordPress, les configurations Shopify ou les thèmes PrestaShop peuvent injecter des balises robots sans que l'interface admin ne le signale clairement.
Cherchez <meta name="robots" content="noindex"> dans le <head>. Vérifiez aussi le HTTP header X-Robots-Tag via les DevTools Chrome ou un outil comme Screaming Frog. Certains serveurs Nginx ou Apache ajoutent cette directive au niveau de la configuration.
Comment prévenir ce type d'accident en environnement de production ?
Mettez en place un monitoring automatisé. Des outils comme OnCrawl, Botify ou même un script Python avec BeautifulSoup peuvent scraper quotidiennement vos pages stratégiques et alerter en cas de balise noindex inattendue.
Intégrez un checklist de pré-déploiement incluant un diff des balises meta entre staging et production. Une simple ligne dans un fichier de migration peut saboter des mois de travail SEO.
Quelles erreurs éviter lors de la correction ?
- Ne pas supprimer la balise sans vérifier qu'aucune autre directive (canonique, redirect) ne crée un conflit
- Oublier de demander une réindexation via Google Search Console après correction — laisser Google découvrir le changement naturellement rallonge inutilement le délai
- Ignorer les logs serveur pour identifier la source de l'erreur (plugin, thème, configuration serveur)
- Ne pas auditer les autres pages critiques : si la homepage porte un noindex accidentel, d'autres URLs sont probablement touchées
- Attendre passivement que le trafic revienne — analyser quel contenu a pris le relais pour comprendre les failles structurelles de votre site
❓ Questions frequentes
Combien de temps faut-il pour que Google désindexe une homepage avec noindex ?
Si je retire le noindex, ma homepage retrouve-t-elle immédiatement sa position ?
Le noindex sur la homepage affecte-t-il le crawl budget du reste du site ?
Peut-on utiliser le noindex stratégiquement pour forcer une autre page en tête ?
Google Search Console signale-t-il toujours un noindex sur la homepage ?
🎥 De la même vidéo 17
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 06/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.